Download as PDF, PPTX



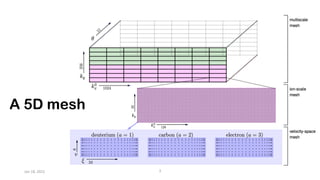


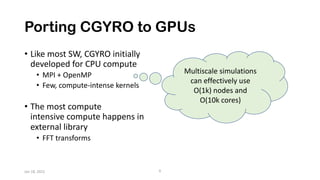


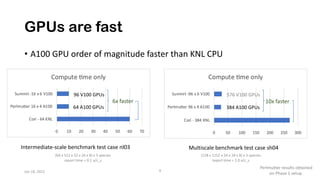
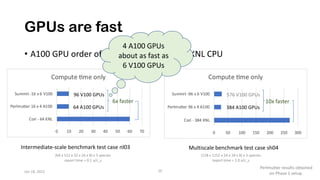
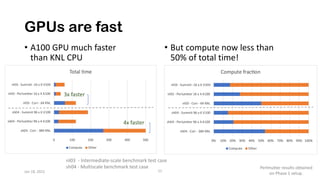

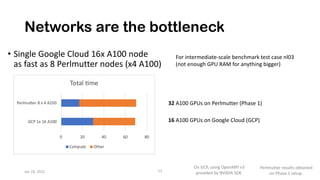

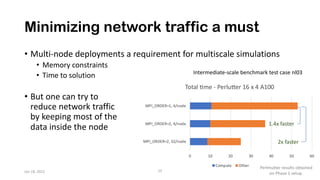

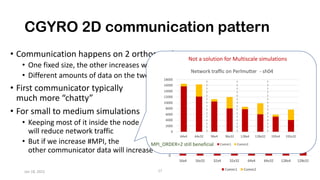


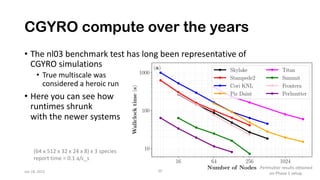
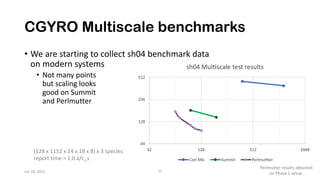
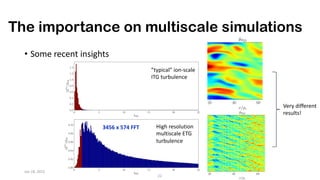
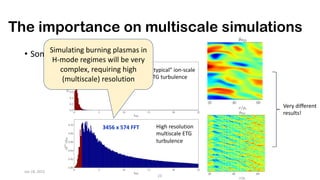

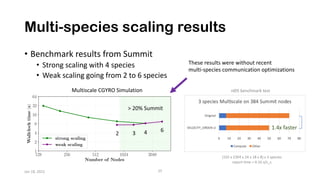




The document discusses the performance optimization of the cgyro solver for multiscale turbulence simulations in fusion plasma, emphasizing its design for efficient simulation on modern high-performance computing systems. The transition to GPU computing significantly reduced compute times and enhanced the scalability of simulations, aided by algorithmic improvements for communication costs. Future work includes ensuring compatibility with new hardware and further optimizing algorithms for complex multi-species simulations in burning plasma conditions.

















![[WSO2Con Asia 2018] Deploying Applications in K8S and Docker](https://cdn.slidesharecdn.com/ss_thumbnails/deployingapplicationsink8sanddocker-wso2conasia2018-sanjaya-180810103523-thumbnail.jpg?width=640&height=640&fit=bounds)



















































![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)












![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)




