Download as PDF, PPTX








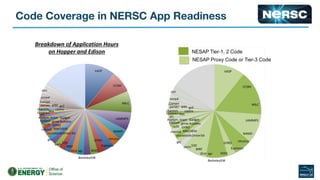
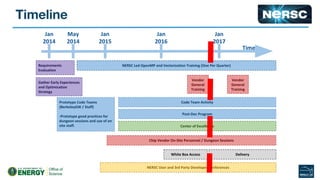

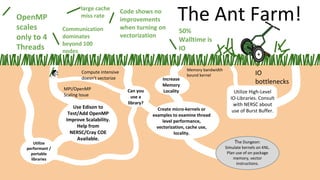
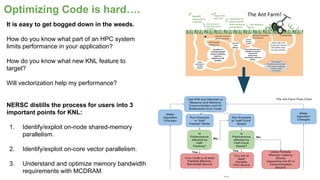


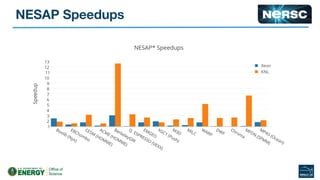
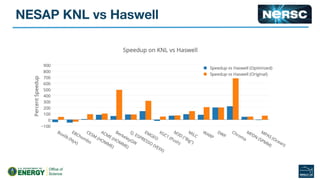
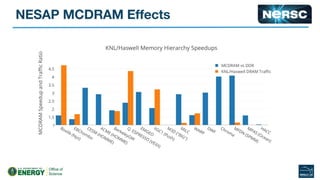
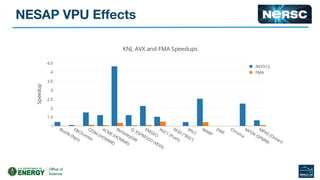
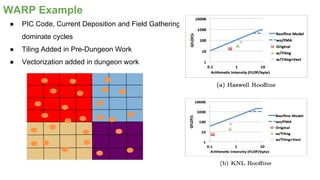
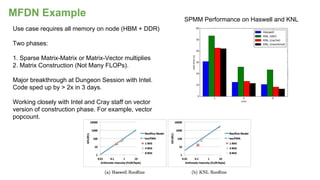
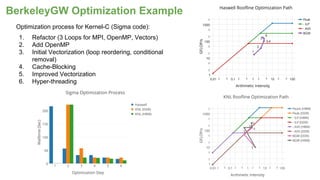
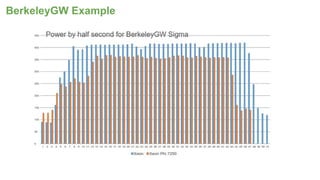




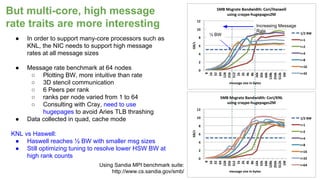

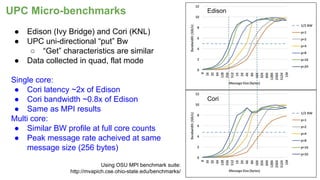
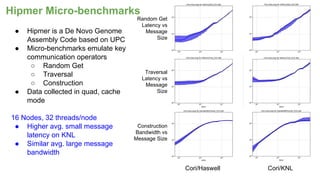


The document outlines the optimization of large-scale science applications on the Cori supercomputer at NERSC, focusing on various research areas supported by the Department of Energy. It details the specifications of current production systems, the transition to energy-efficient architectures, and efforts to enhance user applications through training and collaboration with developers. Additionally, it discusses performance improvements and benchmarking metrics for code using the Knights Landing processors compared to previous architectures.






































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)
















