Download as PDF, PPTX






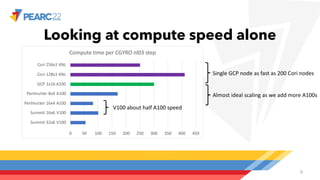
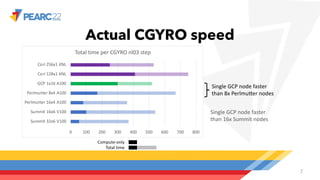
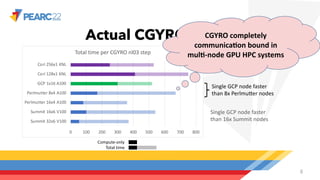
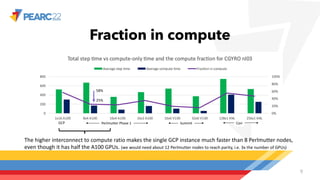

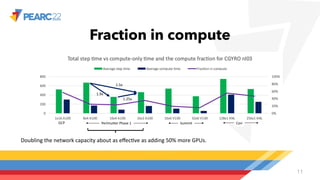




The document compares single-node and multi-node performance of a fusion HPC code, highlighting that while HPC systems have increased compute throughput, interconnect bandwidth has not kept pace, limiting scaling for communication-heavy applications. A specific simulation tool, Cgyro, was tested on various systems, demonstrating that a single GCP node outperforms multiple nodes of other systems due to higher interconnect-to-compute ratios. It concludes that high-interconnect GPU-based systems are crucial for enhancing efficiency in communication-heavy applications like Cgyro.



























