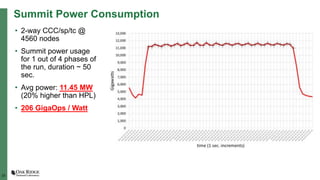
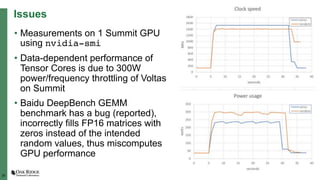
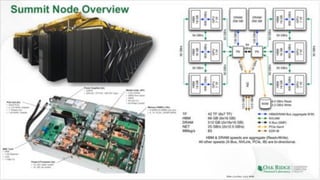
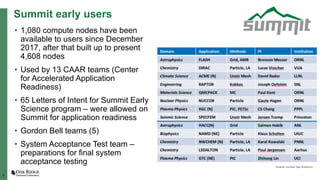
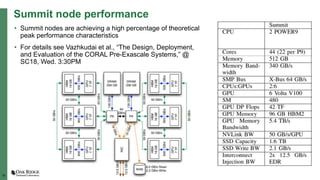
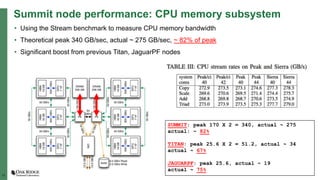
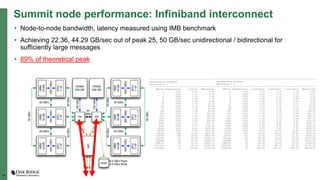
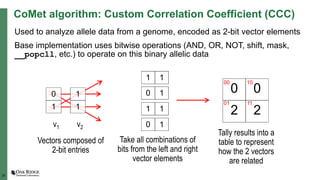
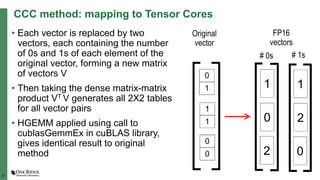
The document summarizes early experiences using the Summit supercomputer at Oak Ridge National Laboratory. Summit is the world's fastest supercomputer and has been used by several early science projects. Two example applications, GTC and CoMet, have achieved good scaling and performance on Summit. Some initial issues were encountered but addressed. Overall, Summit is a very powerful system but continued software improvements are needed to optimize applications for its complex hardware architecture.















![22
CoMet performance
• Achieved 2.36 ExaOps (mixed
precision ExaFlops) at 4,560
nodes (99% of Summit) using the
Tensor Cores
• Near-perfect scaling made
possible by Summit’s Mellanox
Infiniband fat tree network with
adaptive routing
• Equivalent to 86.4 TF per GPU
for the whole computation
(including communications and
transfers)
• > 4X faster than original bitwise
implementation on Summit GPUs
W. Joubert, J. Nance, D. Weighill, D. Jacobson, “Parallel Accelerated Vector Similarity Calculations
for Genomics Applications,” Parallel Computing, vol. 75, July 2018, pp. 130-145,
https://www.sciencedirect.com/science/article/pii/S016781911830084X
W. Joubert, J. Nance, S. Climer, D. Weighill, D. Jacobson, “Parallel Accelerated Custom Correlation
Coefficient Calculations for Genomics Applications,” arxiv 1705.08213 [cs], Parallel Computing,
accepted.
Wayne Joubert, Deborah Weighill, David Kainer, Sharlee Climer, Amy Justice, Kjiersten Fagnan,
Daniel Jacobson, “Attacking the Opioid Epidemic: Determining the Epistatic and Pleiotropic Genetic
Architectures for Chronic Pain and Opioid Addiction,” SC18, Gordon Bell finalist, to appear.](https://image.slidesharecdn.com/openpoweradg2018-summitearlyexperiences-2018-11-wj-181119144952/85/Early-Application-experiences-on-Summit-22-320.jpg)