Download to read offline



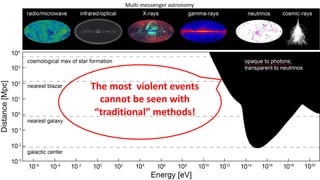





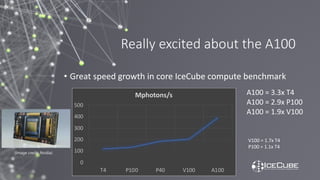


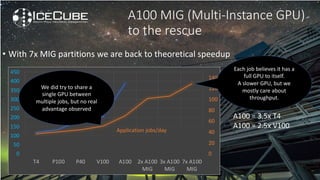
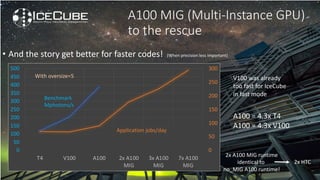


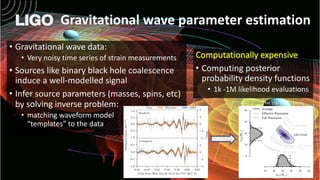

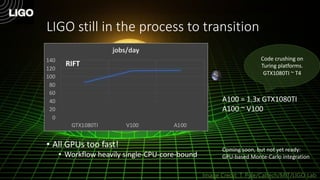
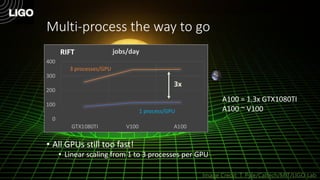

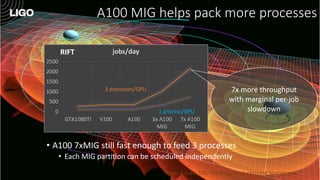




The document discusses how Nvidia's A100 GPU with Multi-Instance GPU (MIG) capability can help scale up scientific output for astronomy projects like IceCube and LIGO. The A100 is much faster than previous GPUs, but MIG allows it to be partitioned so multiple jobs or processes can leverage the GPU simultaneously. This results in 200-600% higher throughput compared to using a single GPU, by better utilizing the massive parallelism of the A100. MIG makes the powerful A100 GPU practical for these CPU-bound scientific workloads.























































































