Download as PDF, PPTX






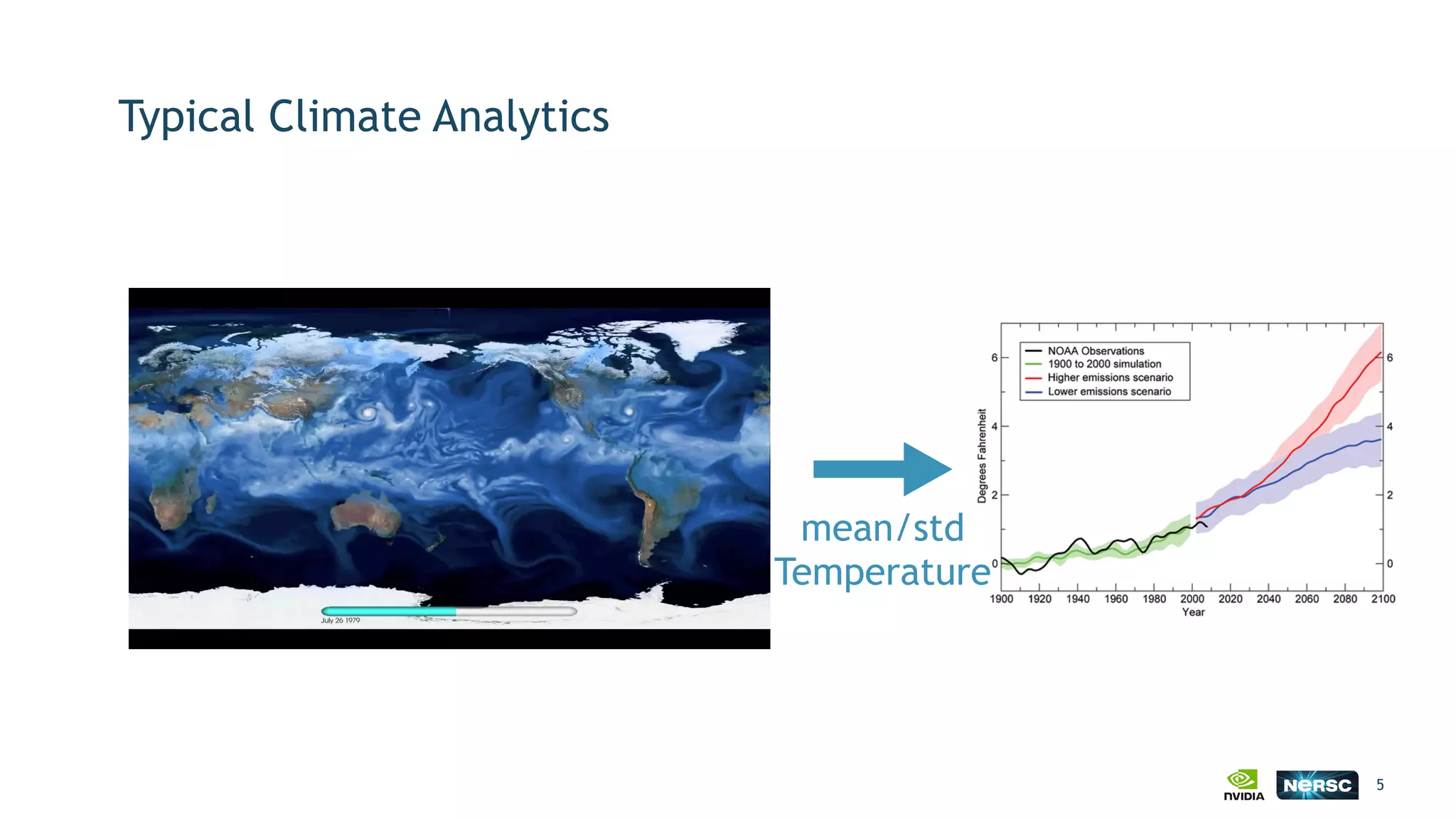
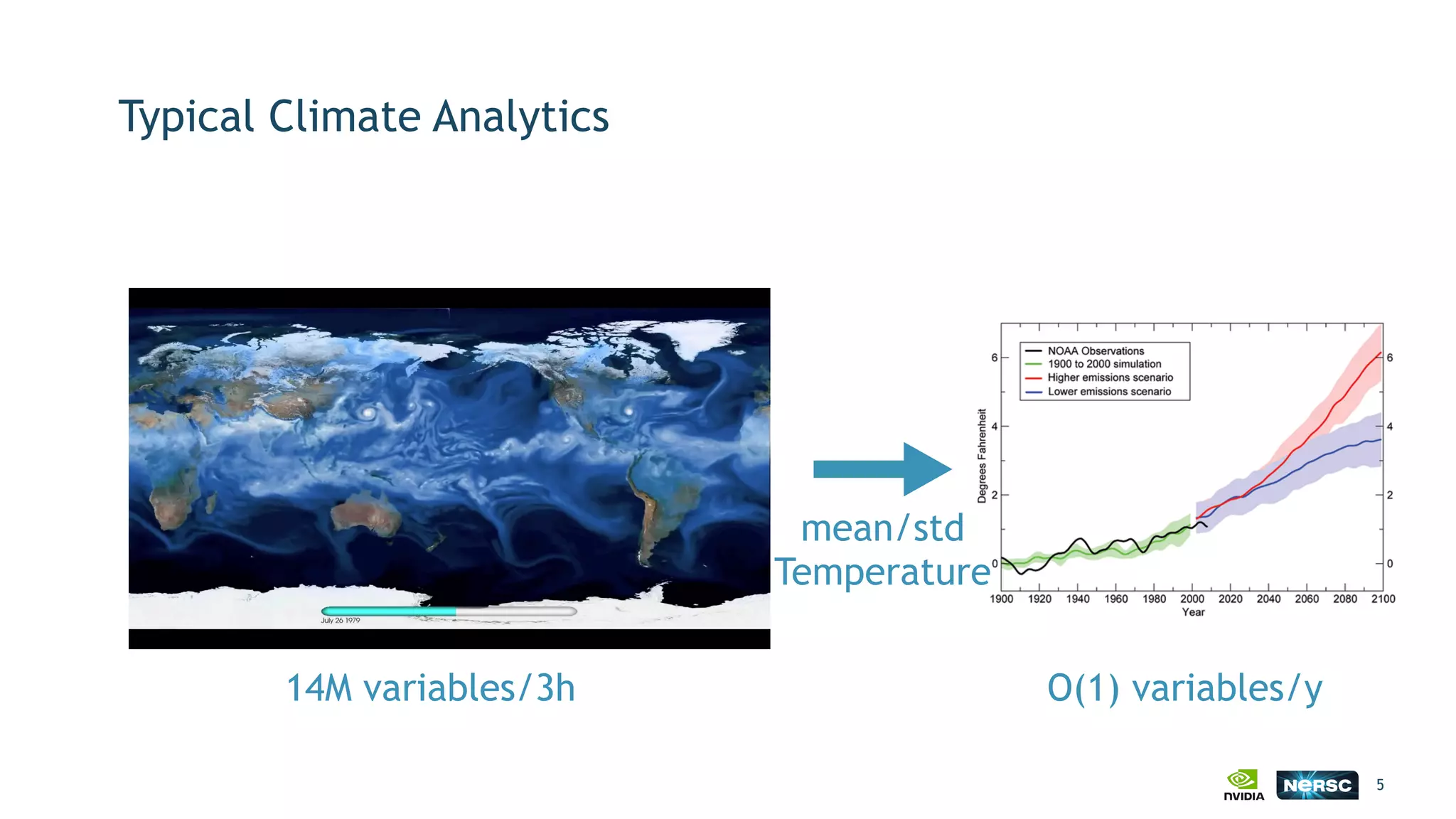




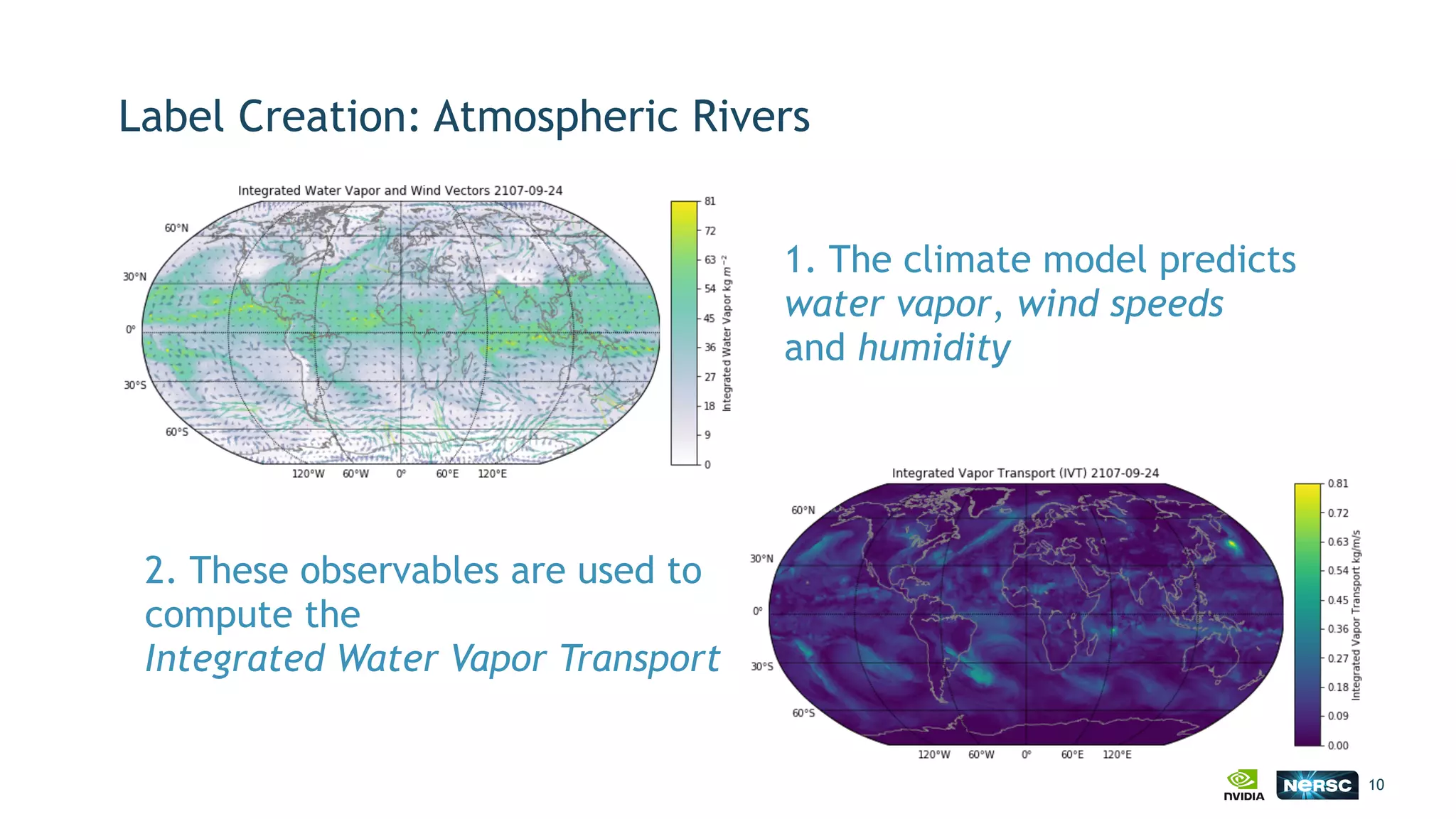
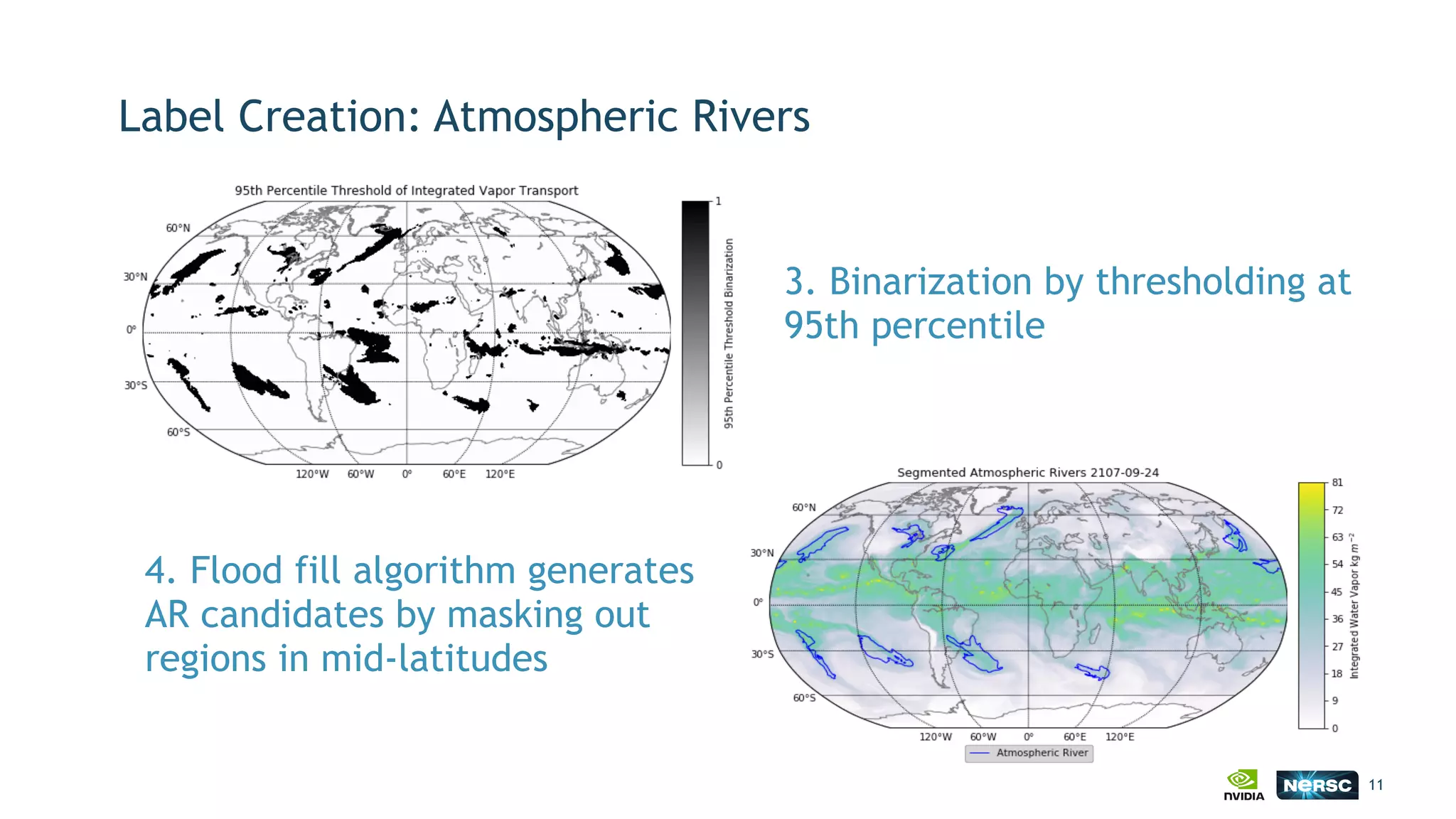
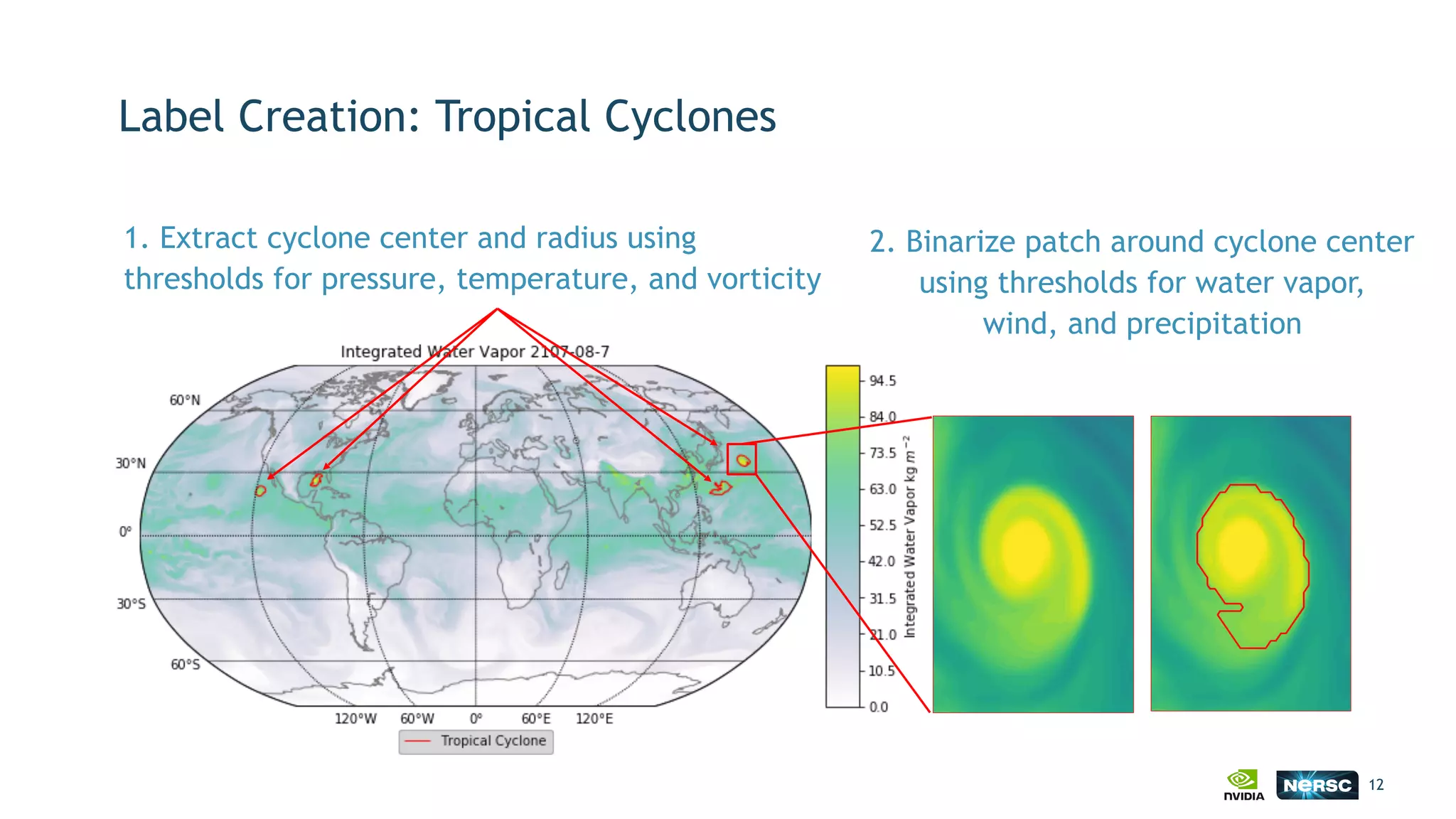





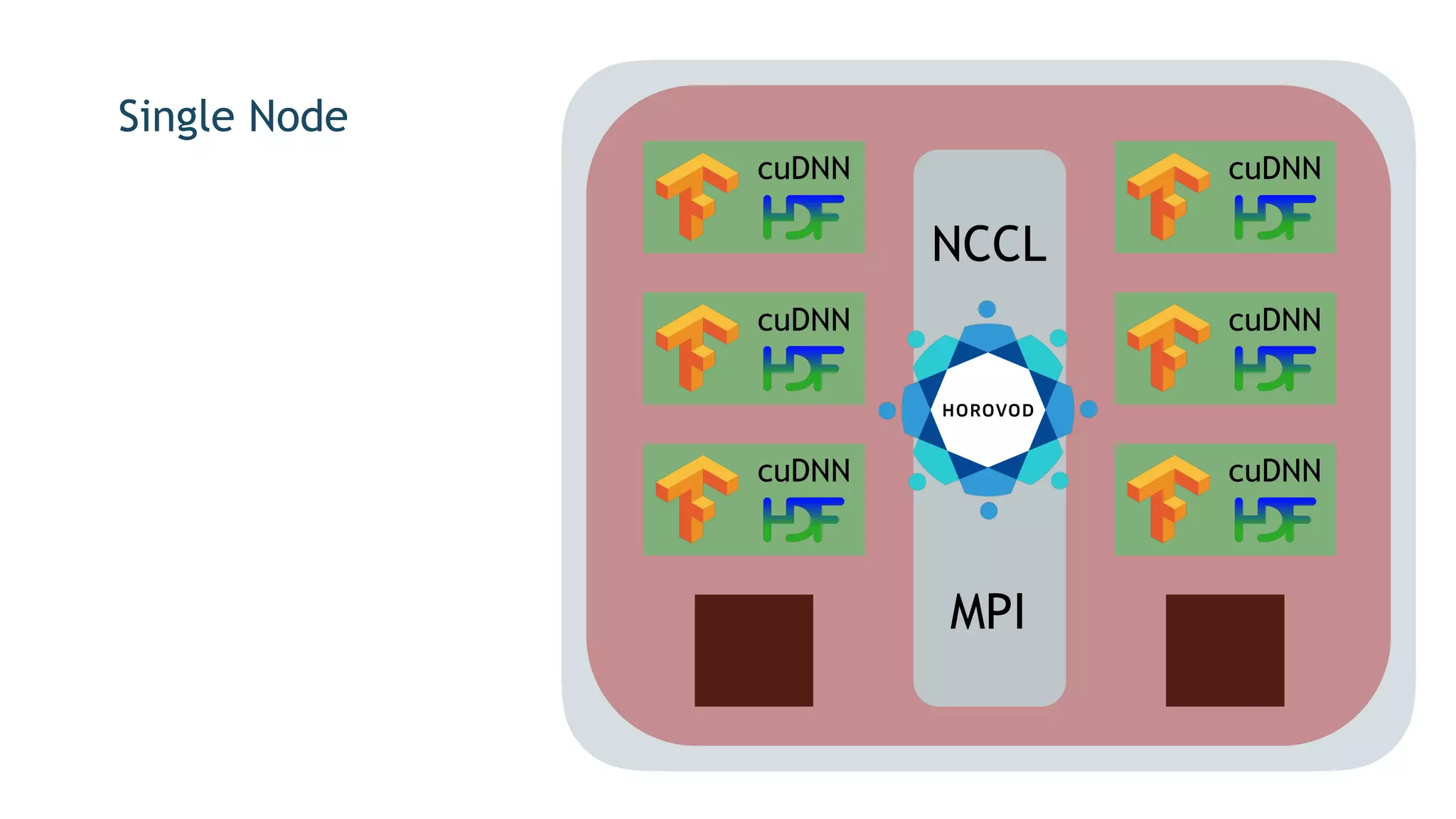
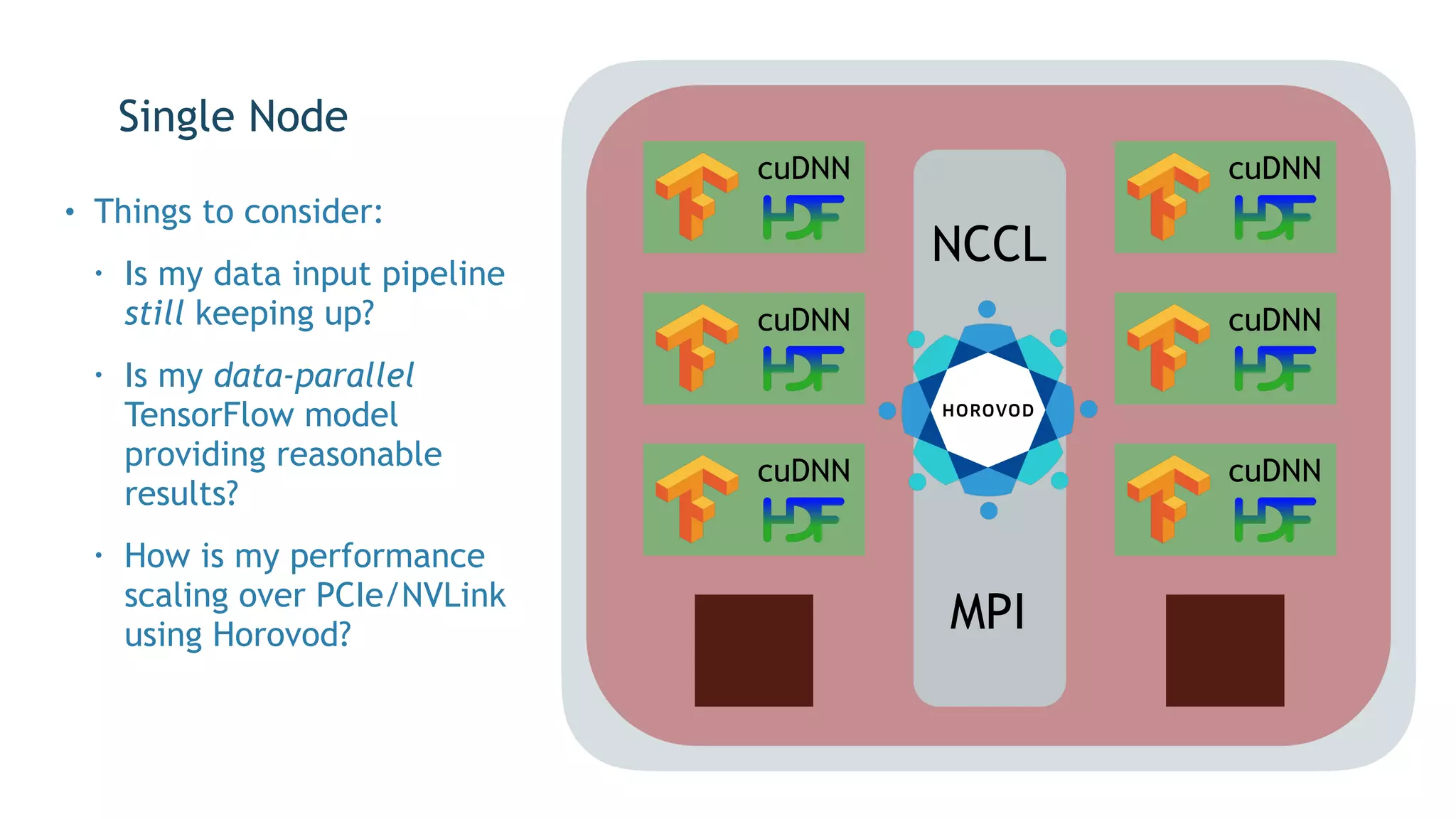
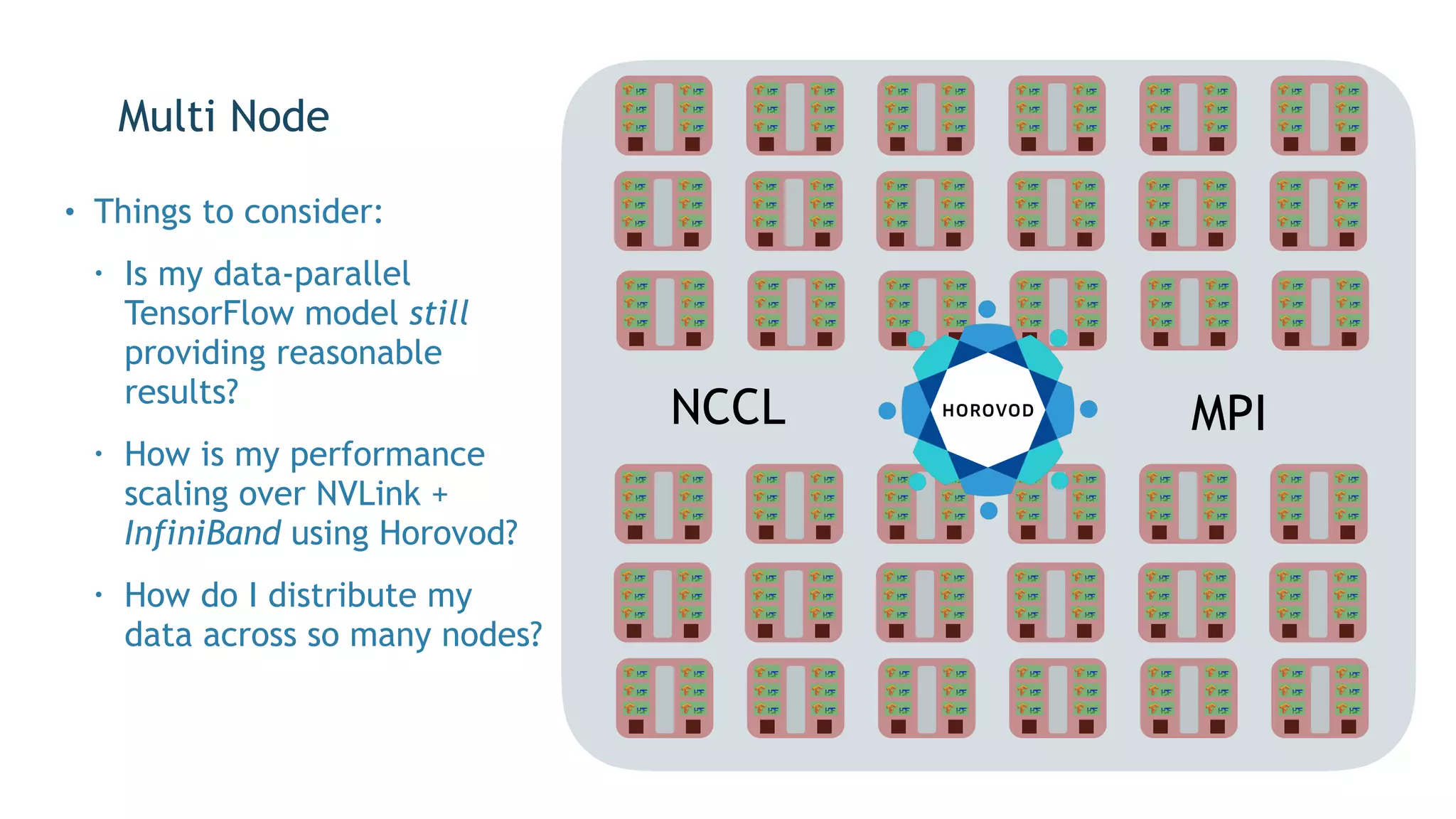
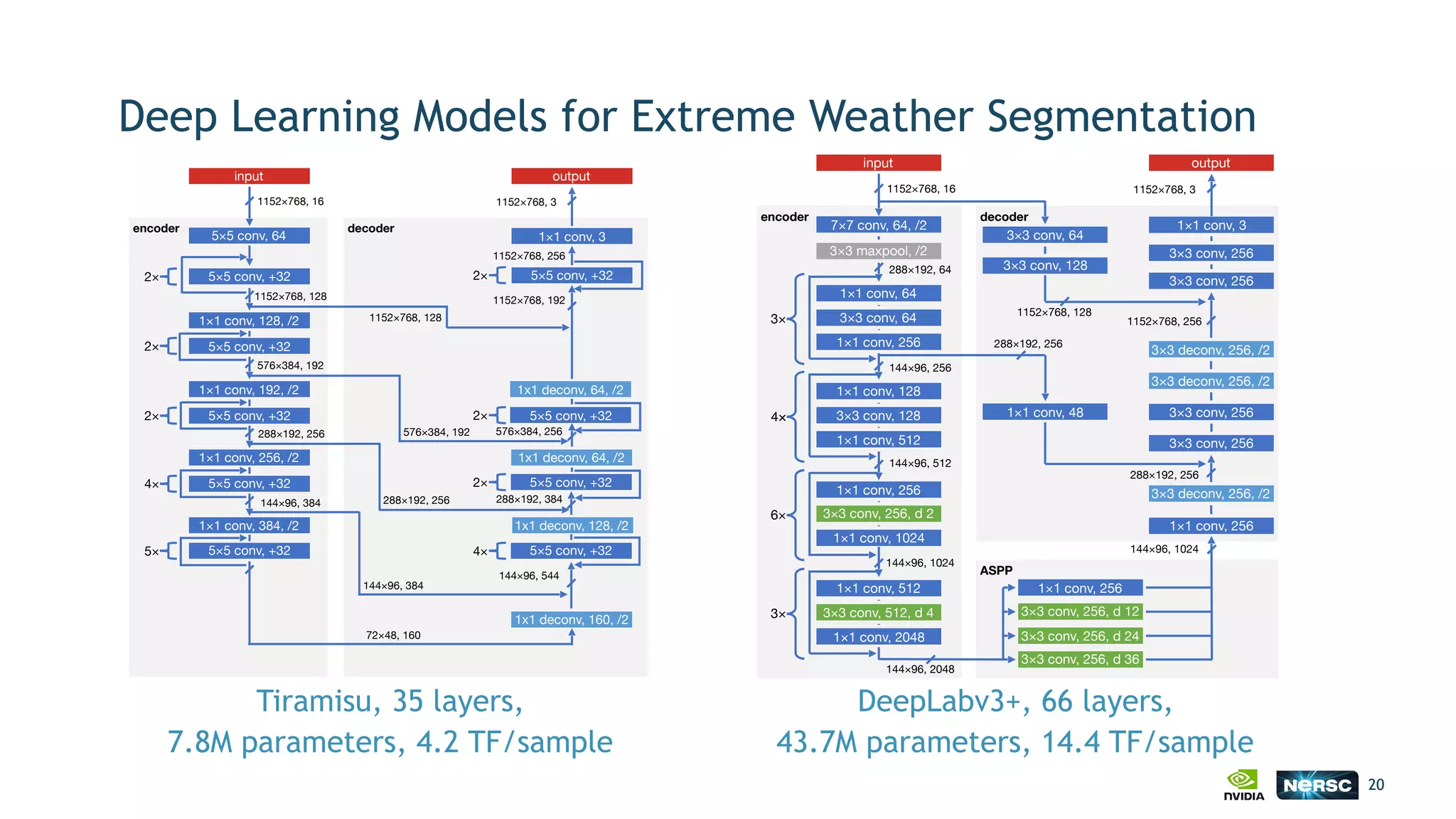
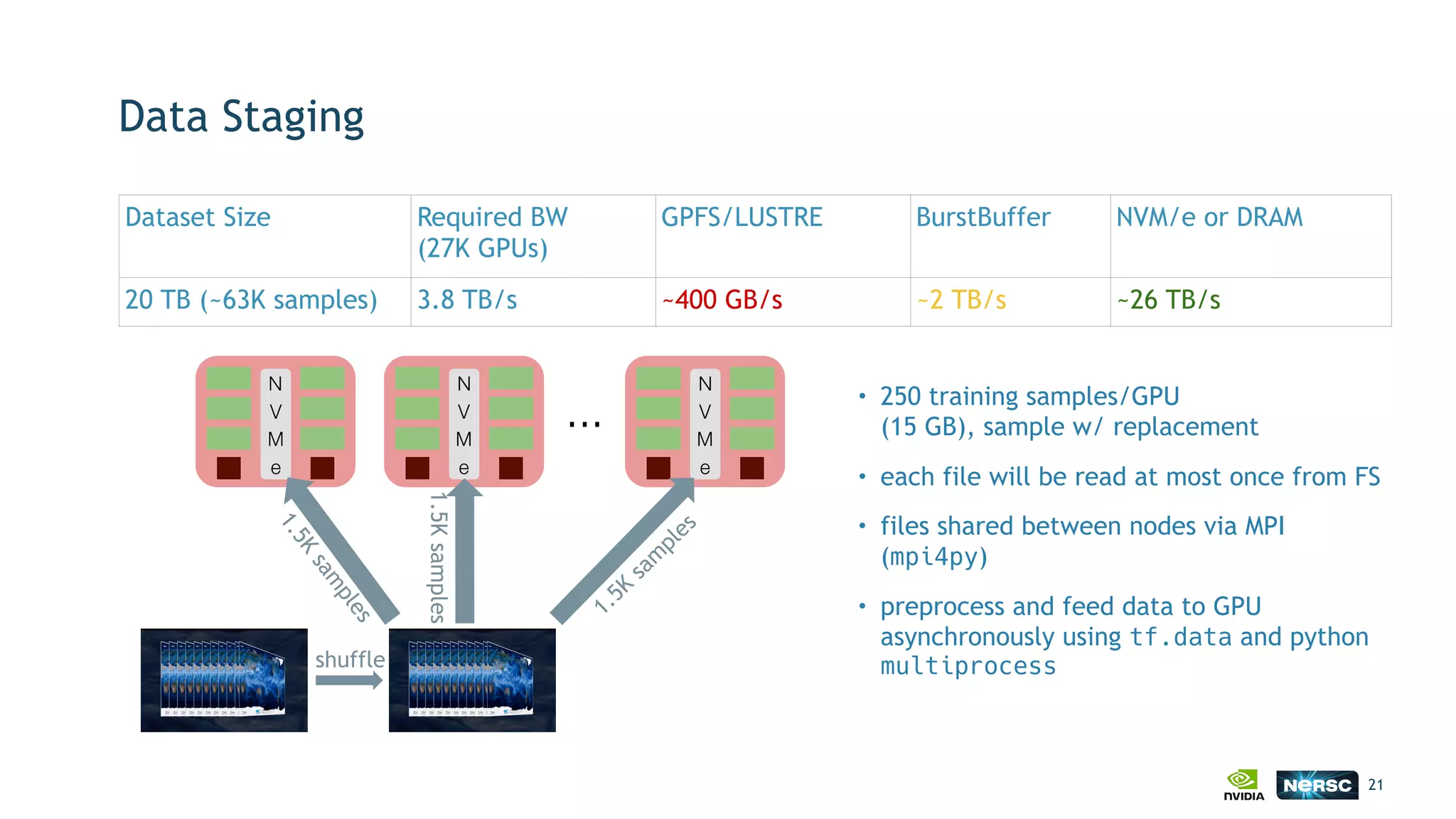

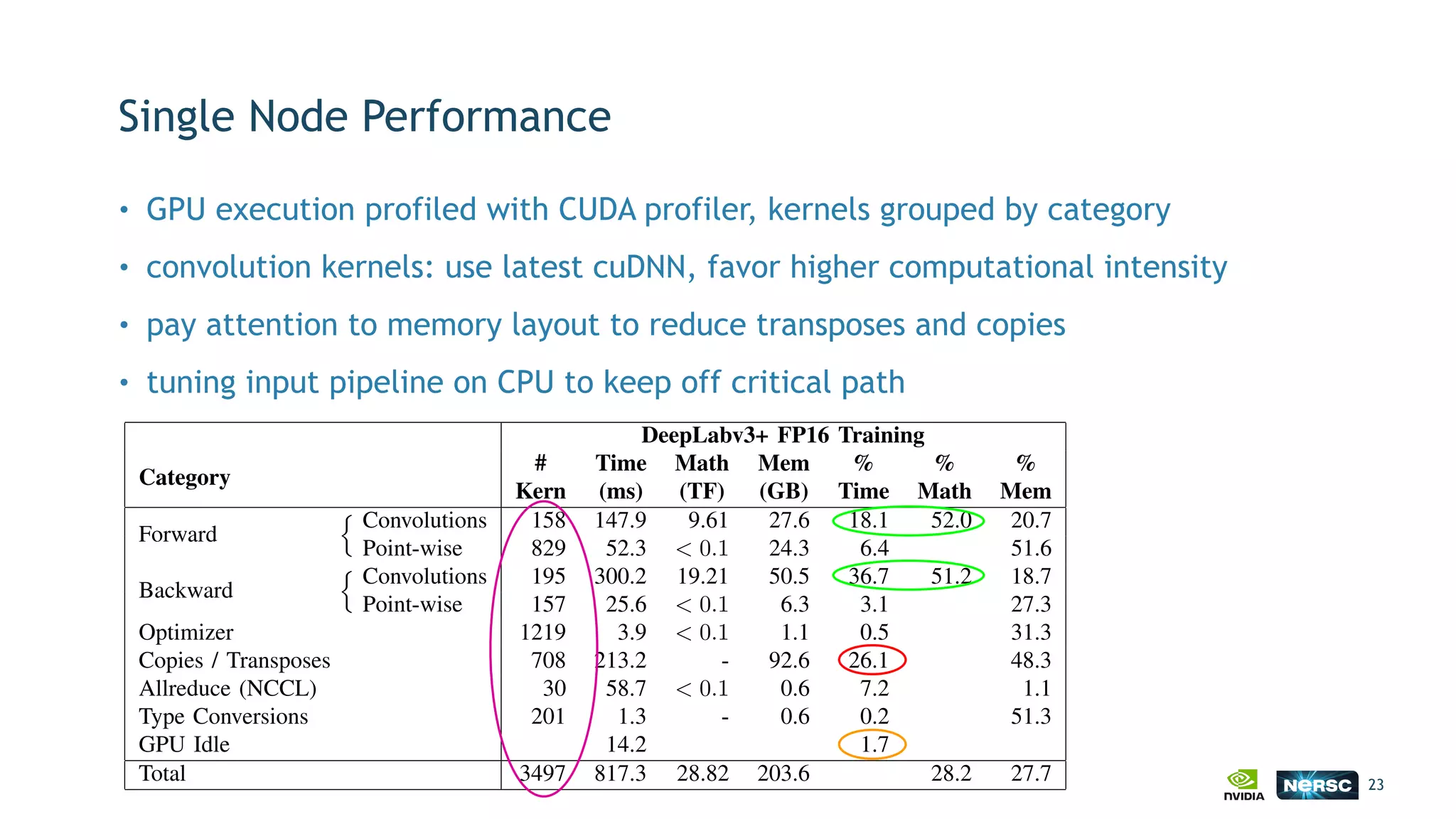
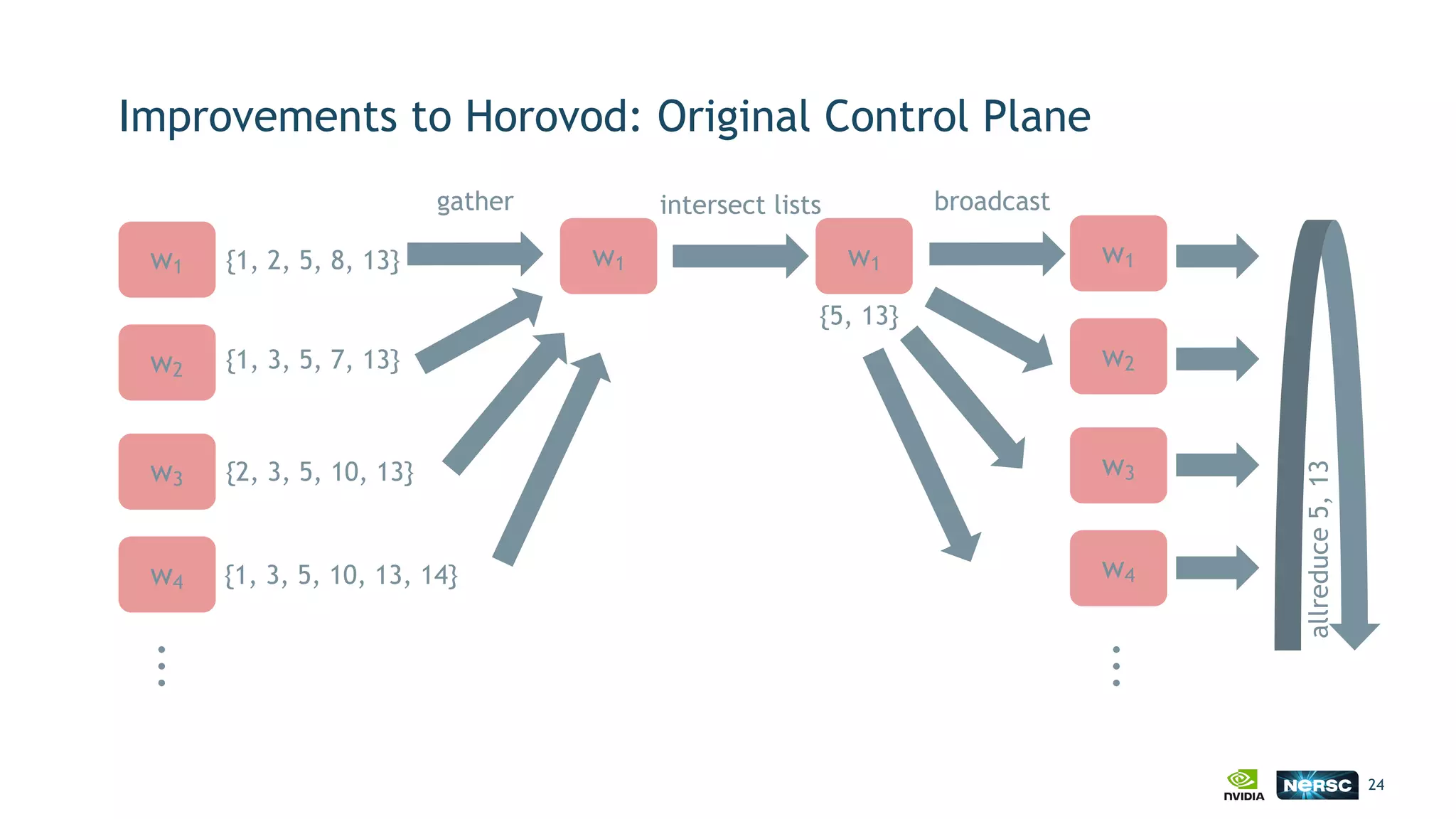
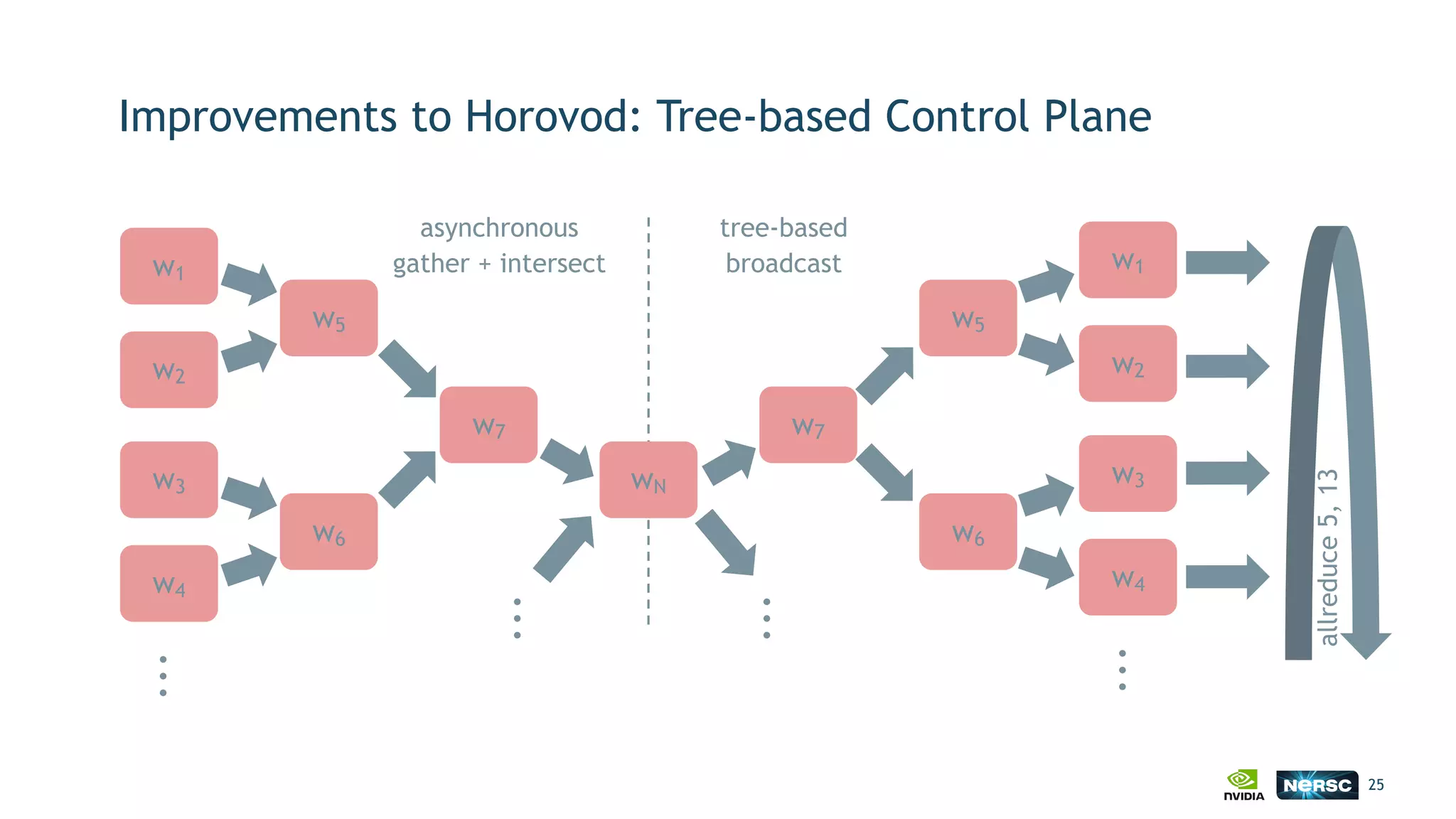
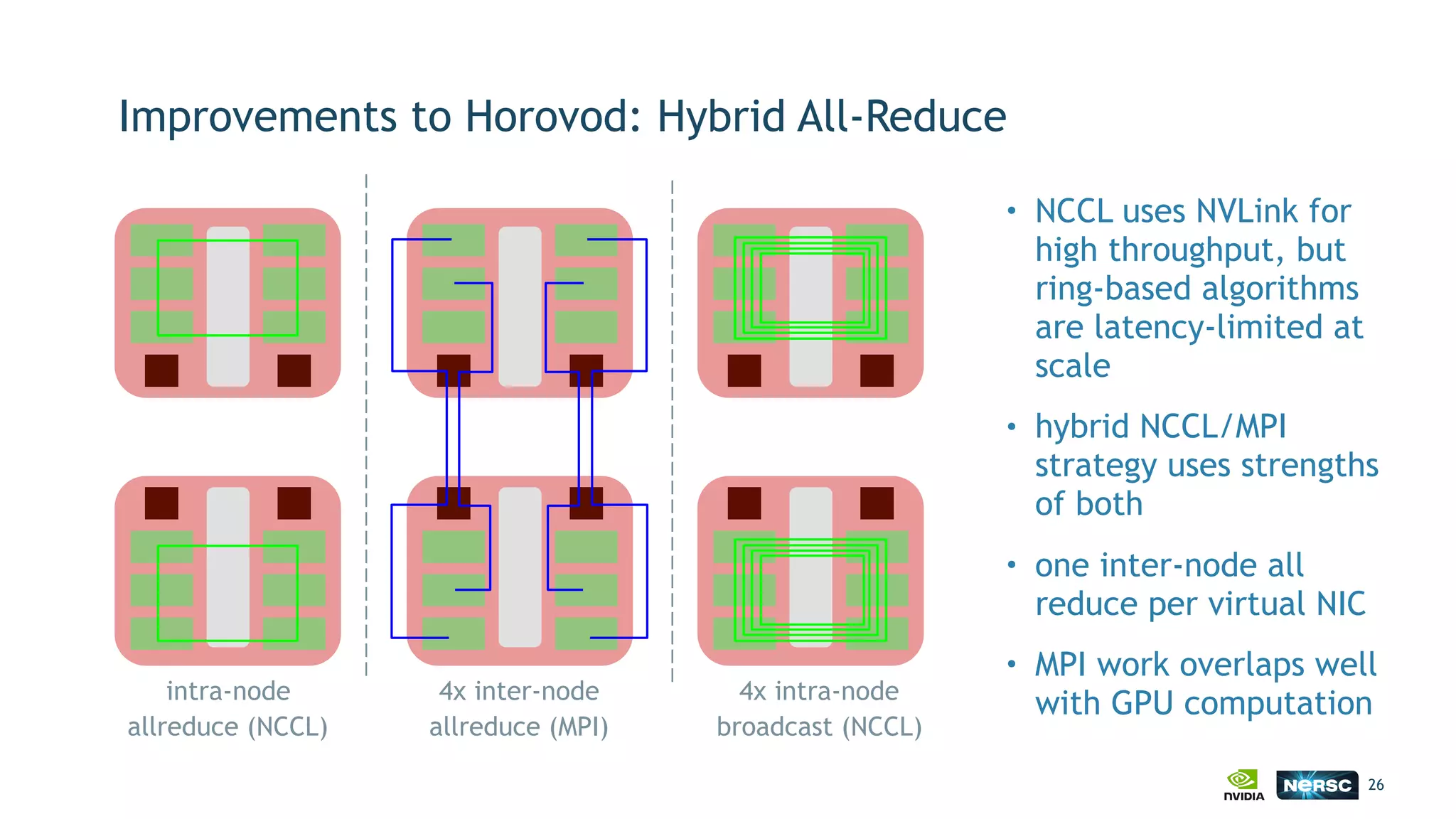
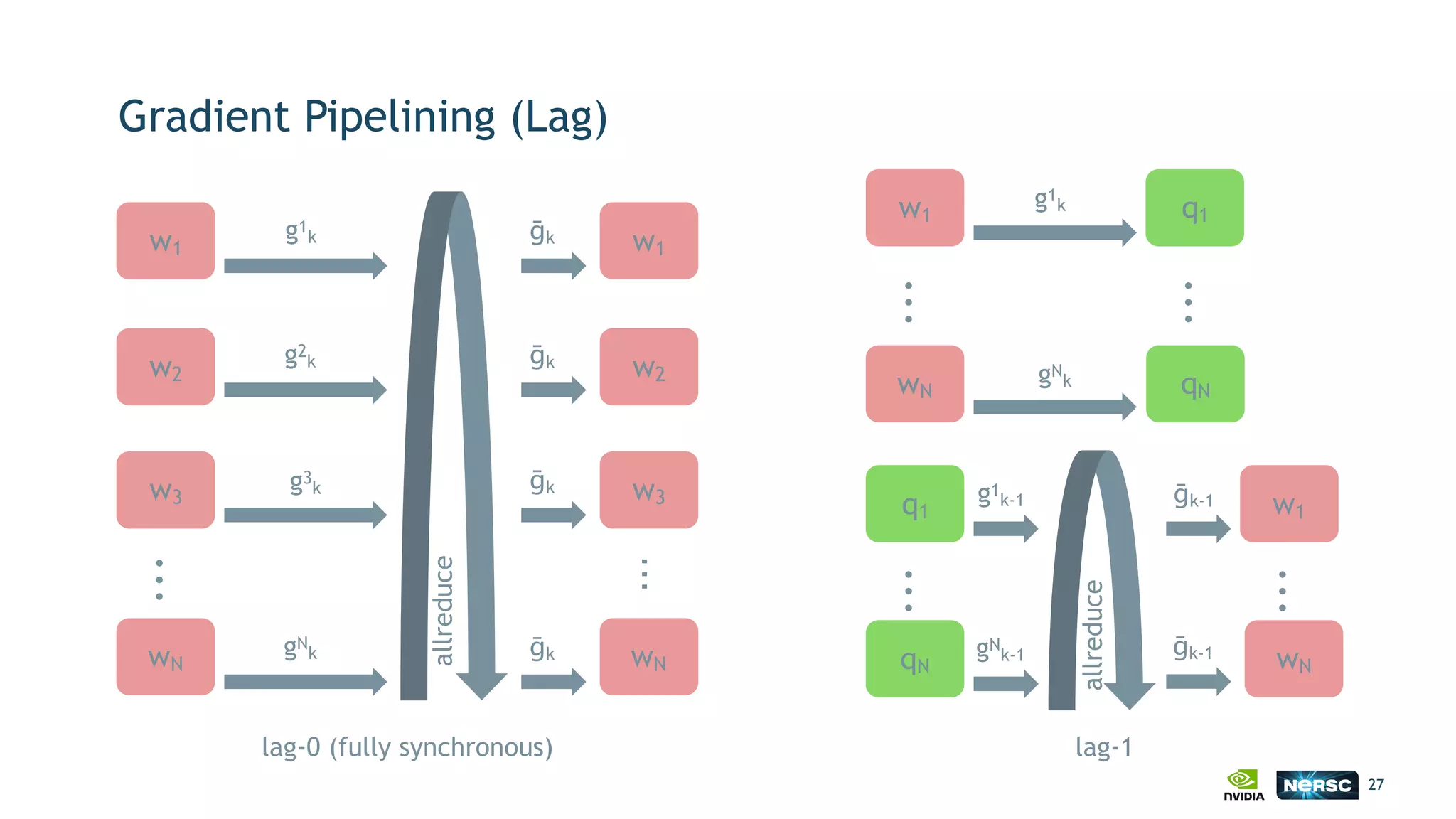
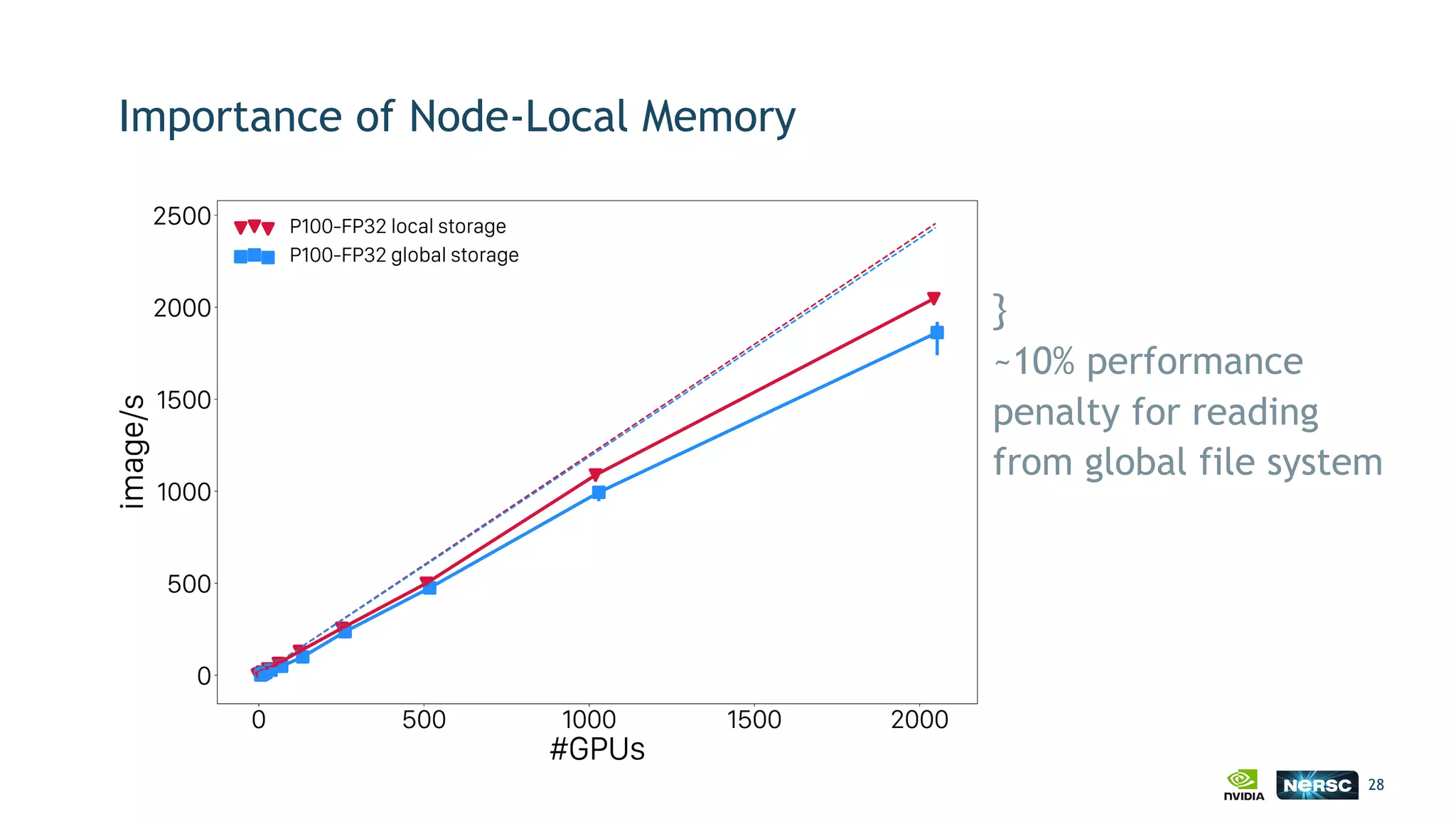
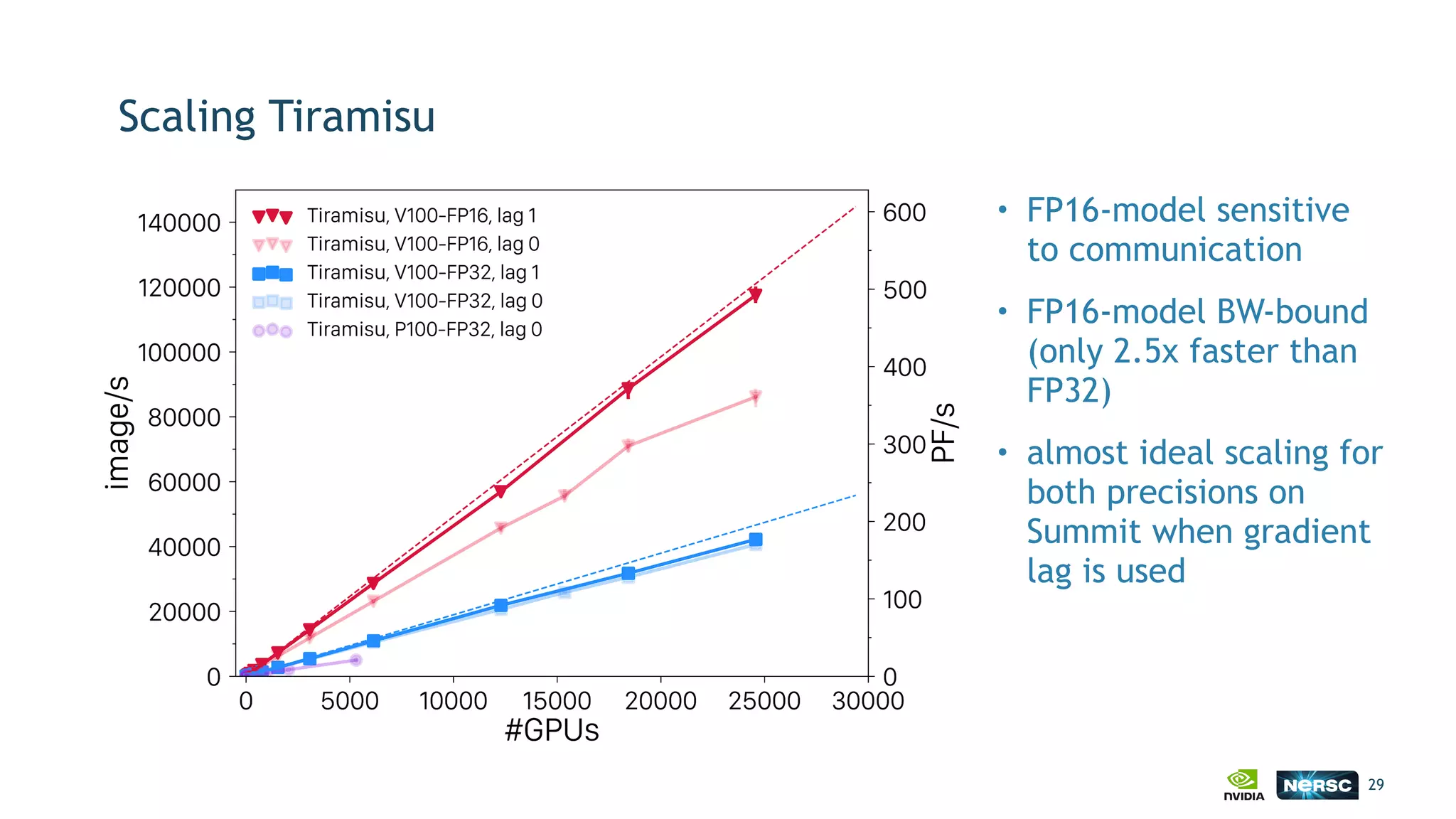
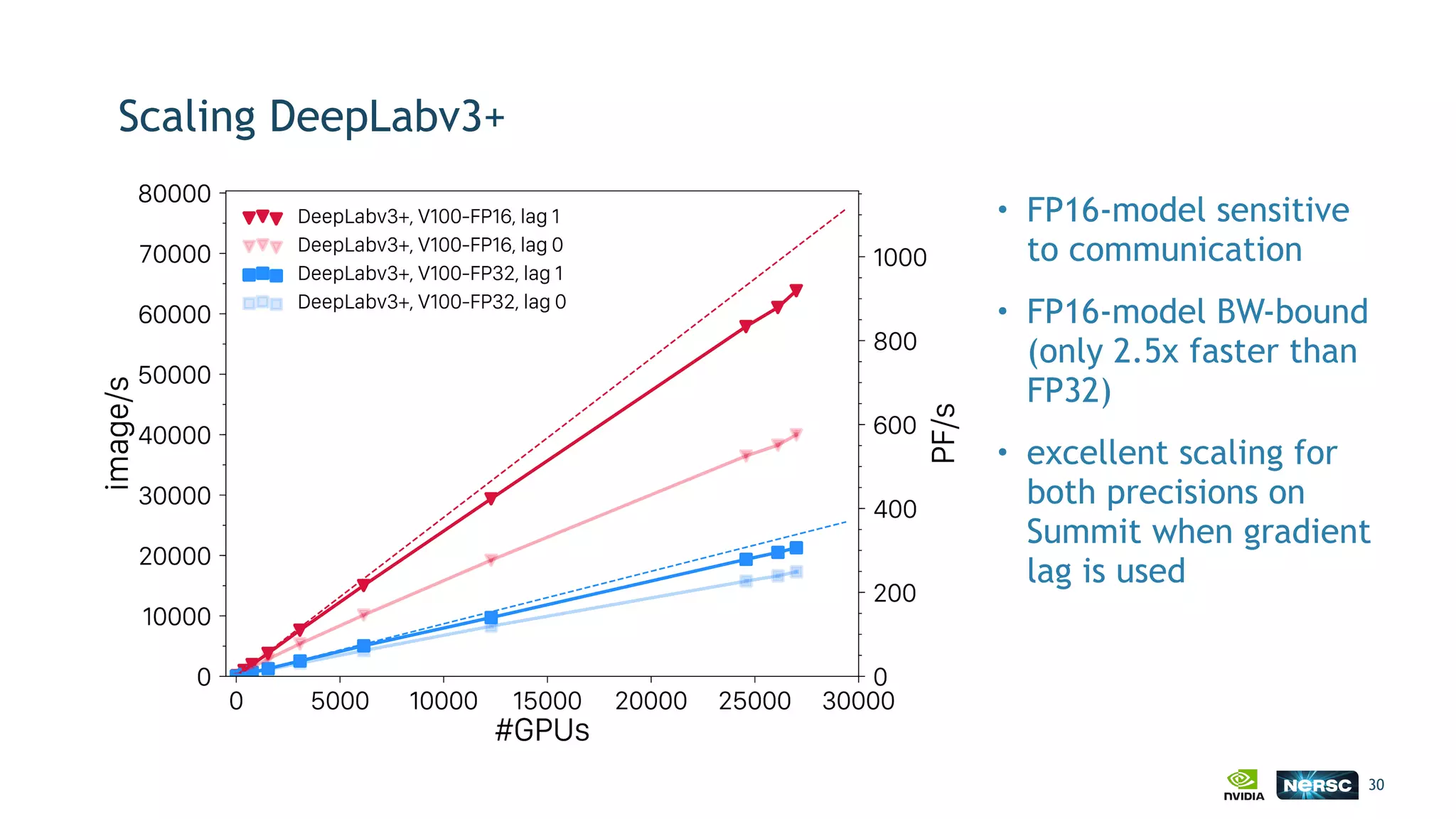



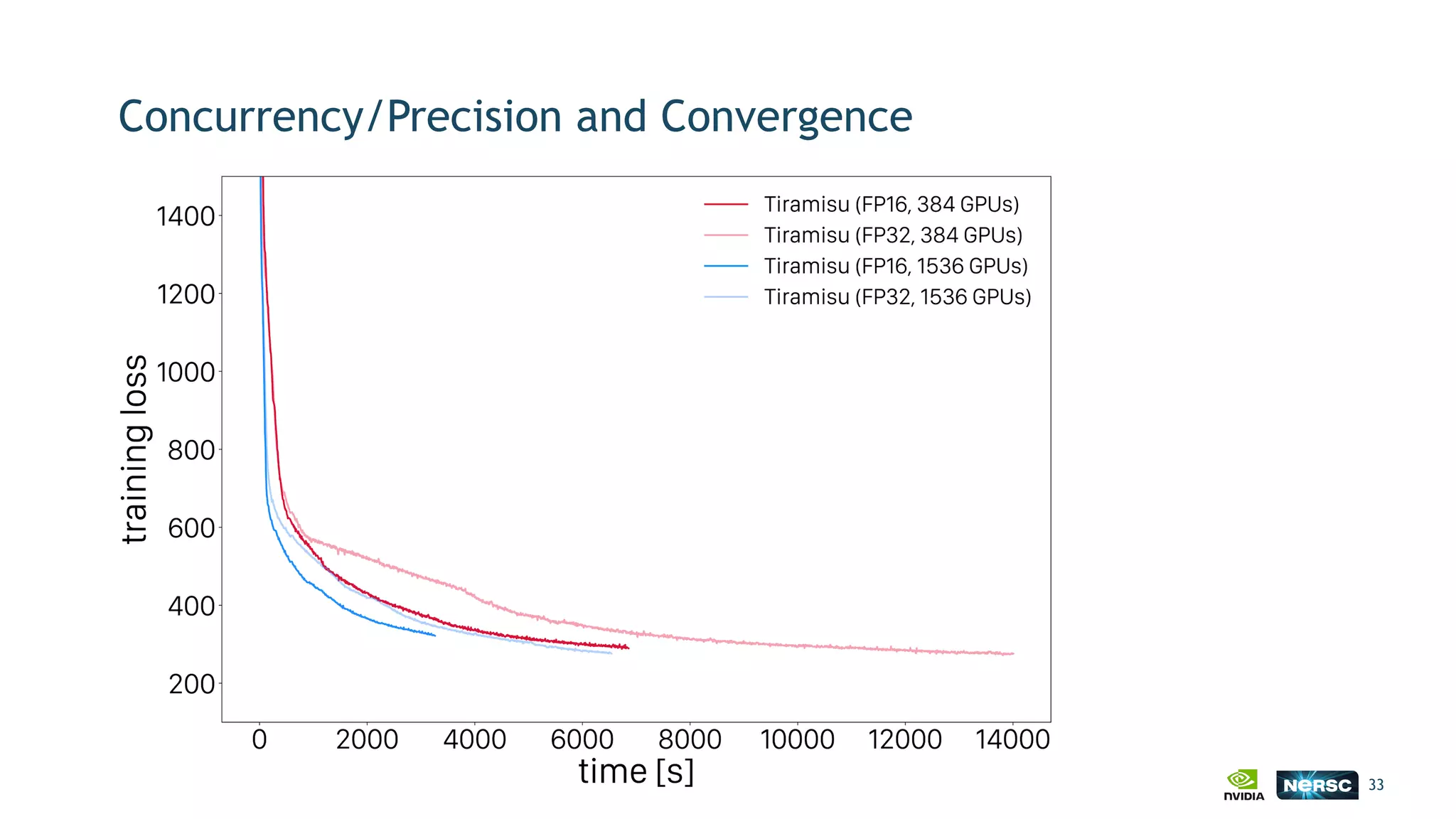
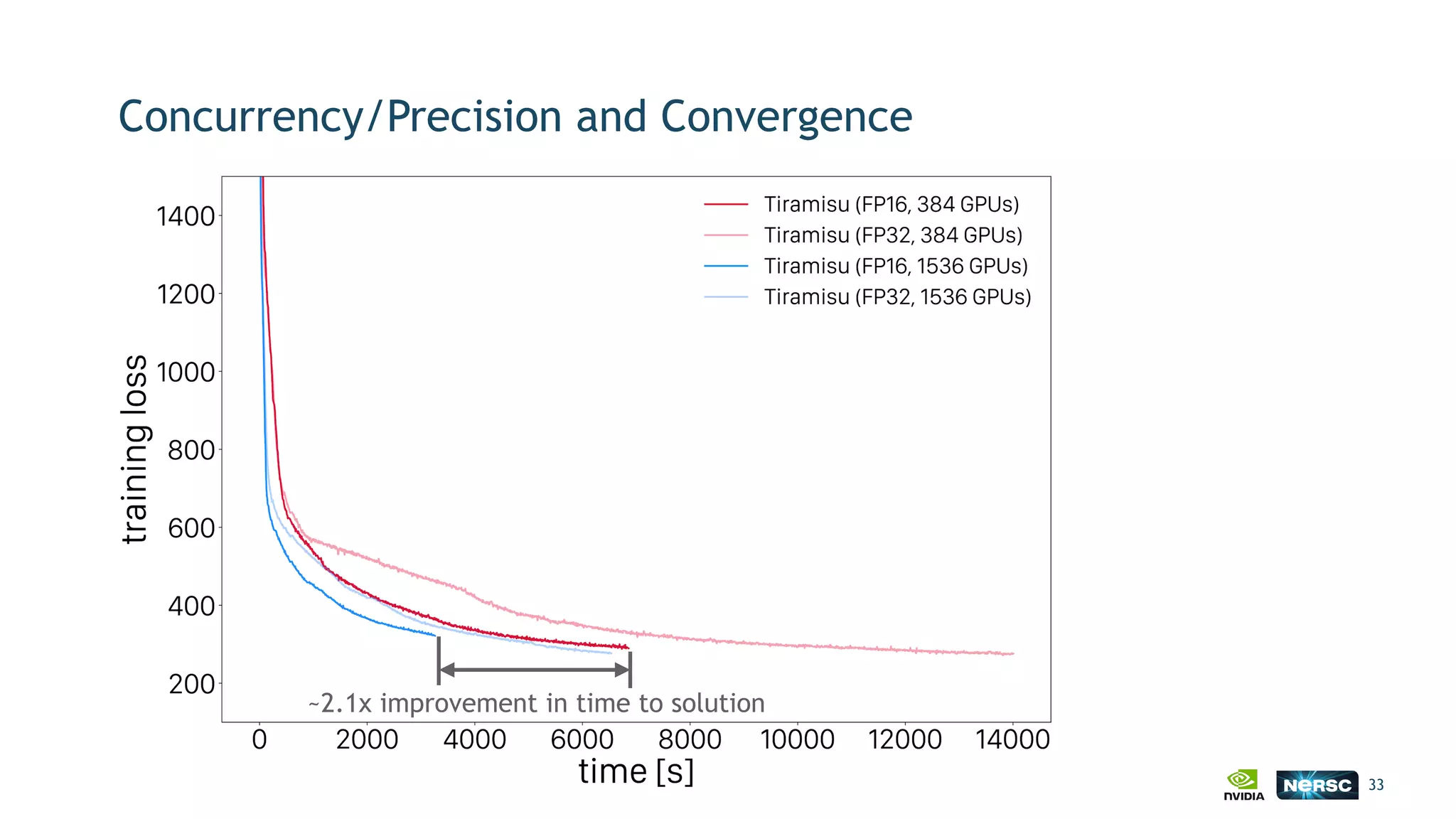
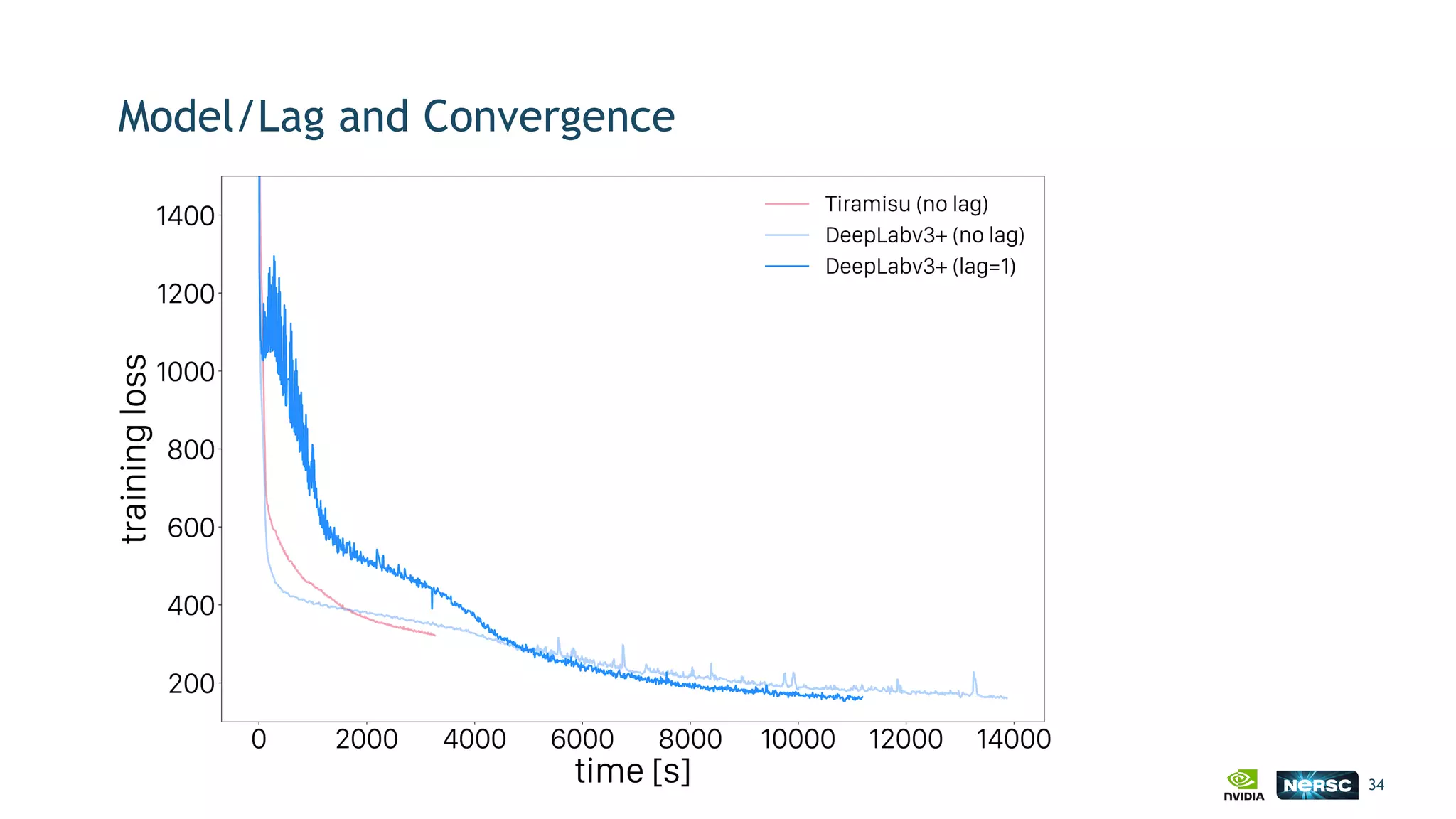






The document discusses the application of exascale deep learning to climate analytics, focusing on the socio-economic impacts of extreme weather events and their modeling through machine learning approaches. It highlights the unique challenges in climate data analytics and deep learning, including data balance, model accuracy, and the need for robust computational frameworks. Ultimately, it concludes that advancements in deep learning and high-performance computing can enhance the precision of climate predictions and response strategies.


















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)




