Download as PDF, PPTX





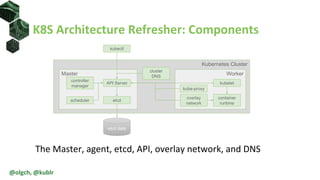
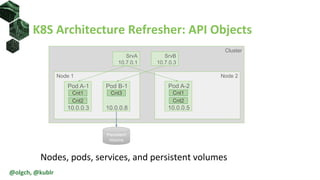







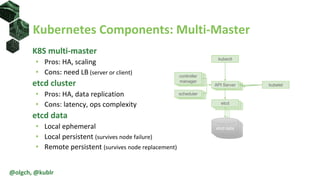


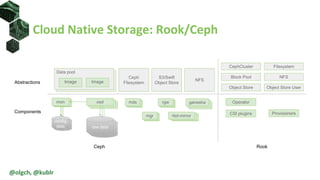






The document discusses the impact of self-healing nodes and infrastructure management on system reliability within Kubernetes environments. It covers various architectural components, monitoring tools, and reliability strategies essential for maintaining robust operations. Key takeaways include the importance of understanding Kubernetes layers and the responsibilities of cluster operators in managing recovery and performance.




![[OpenStack Days Korea 2016] Track4 - Deep Drive: k8s with Docker](https://cdn.slidesharecdn.com/ss_thumbnails/45adeepdiveintokubernetes-160226175008-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[Container world 2017] The Questions You're Afraid to Ask about Containers](https://cdn.slidesharecdn.com/ss_thumbnails/containerworld2017usetherightcontainertechnologyforthejobpublic-170224003200-thumbnail.jpg?width=640&height=640&fit=bounds)








































