Download as PDF, PPTX


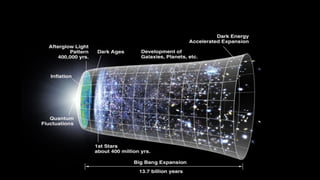
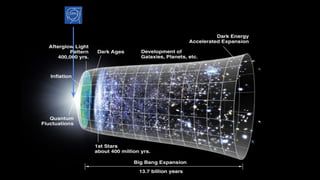
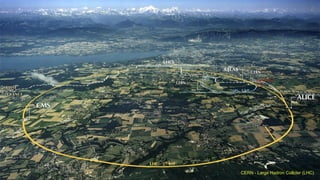


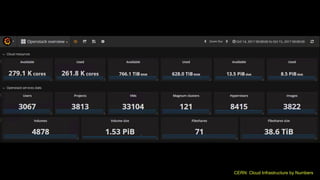
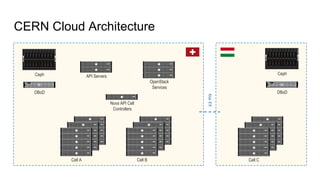
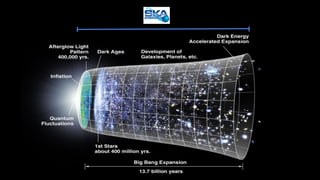



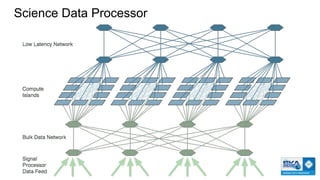

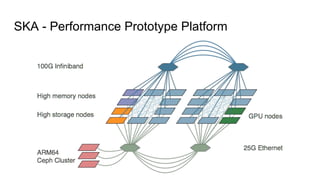






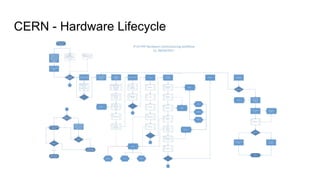















The document outlines the development of next-generation infrastructure at CERN and the SKA using OpenStack, focusing on hardware lifecycle management and resource optimization. It discusses the challenges posed by heterogeneous hardware and the implementation of OpenStack Ironic for managing physical servers. Additionally, it addresses the use of preemptible instances to improve resource efficiency and the integration of various OpenStack tools for advanced data processing and cluster management.



































































