Download to read offline


![QMC: the standard Dogma
Star discrepancy.
D⇤
N(X) = sup
R⇢[0,1]d
# {i : xi 2 R}
N
|R|
This is a good quantity to minimize because
Theorem (Koksma-Hlawka)
Z
[0,1]d
f (x)dx
1
N
NX
n=1
f (xn) . (D⇤
N) (var(f )) .
In particular: error only depends on the oscillation of f .](https://image.slidesharecdn.com/jittered-171215153348/75/QMC-Program-Trends-and-Advances-in-Monte-Carlo-Sampling-Algorithms-Workshop-Jittered-Sampling-Bounds-Problems-Stefan-Steinberger-Dec-14-2017-3-2048.jpg)
![QMC: the standard Dogma
Star discrepancy.
D⇤
N(X) = sup
R⇢[0,1]d
# {i : xi 2 R}
N
|R|
Two competing conjectures (emotionally charged subject)
D⇤
N &
(log N)d 1
N
or D⇤
N &
(log N)d/2
N
.
There are many clever constructions of point set that achieve
D⇤
N .
(log N)d 1
N
.](https://image.slidesharecdn.com/jittered-171215153348/75/QMC-Program-Trends-and-Advances-in-Monte-Carlo-Sampling-Algorithms-Workshop-Jittered-Sampling-Bounds-Problems-Stefan-Steinberger-Dec-14-2017-4-2048.jpg)


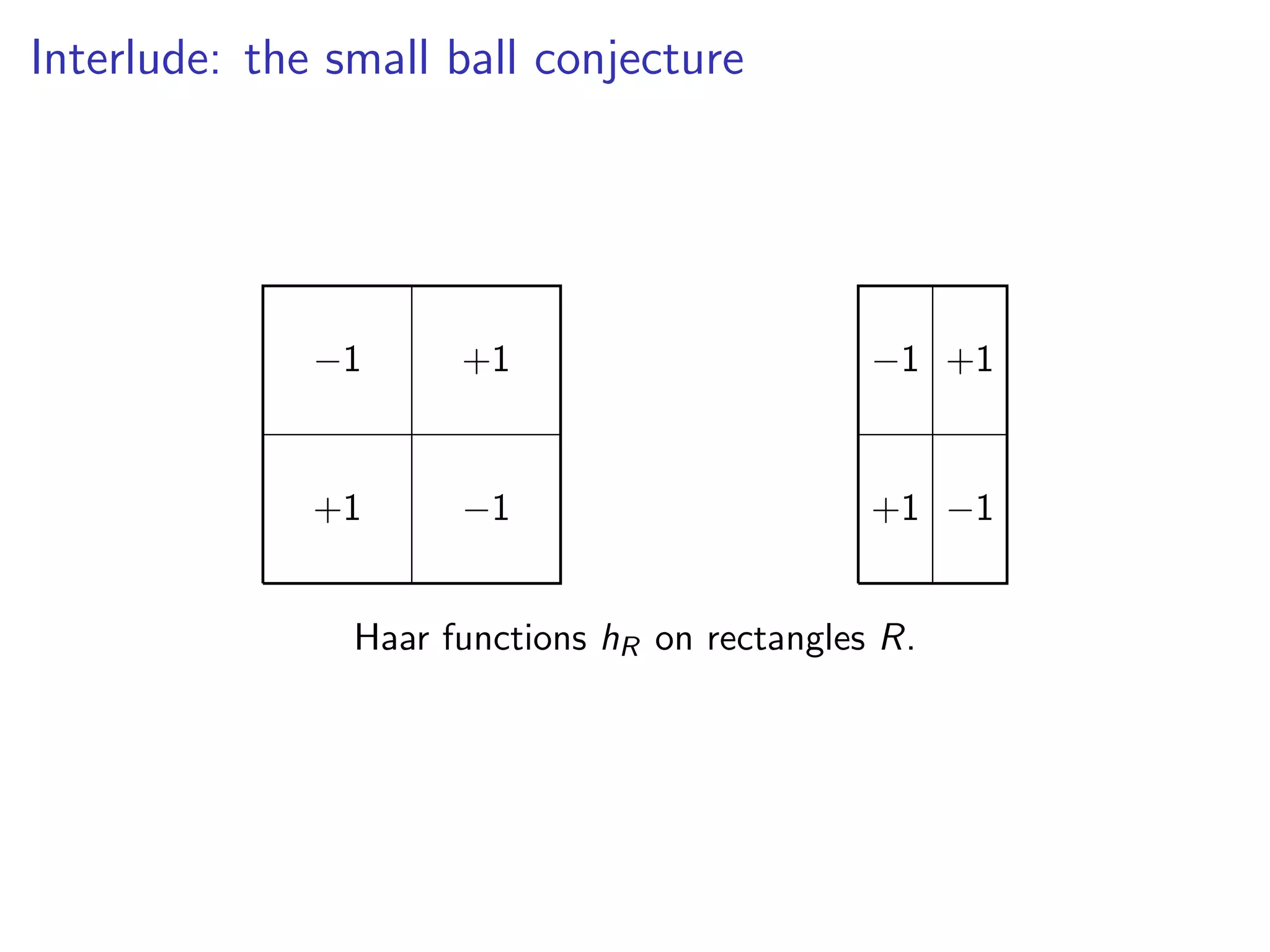
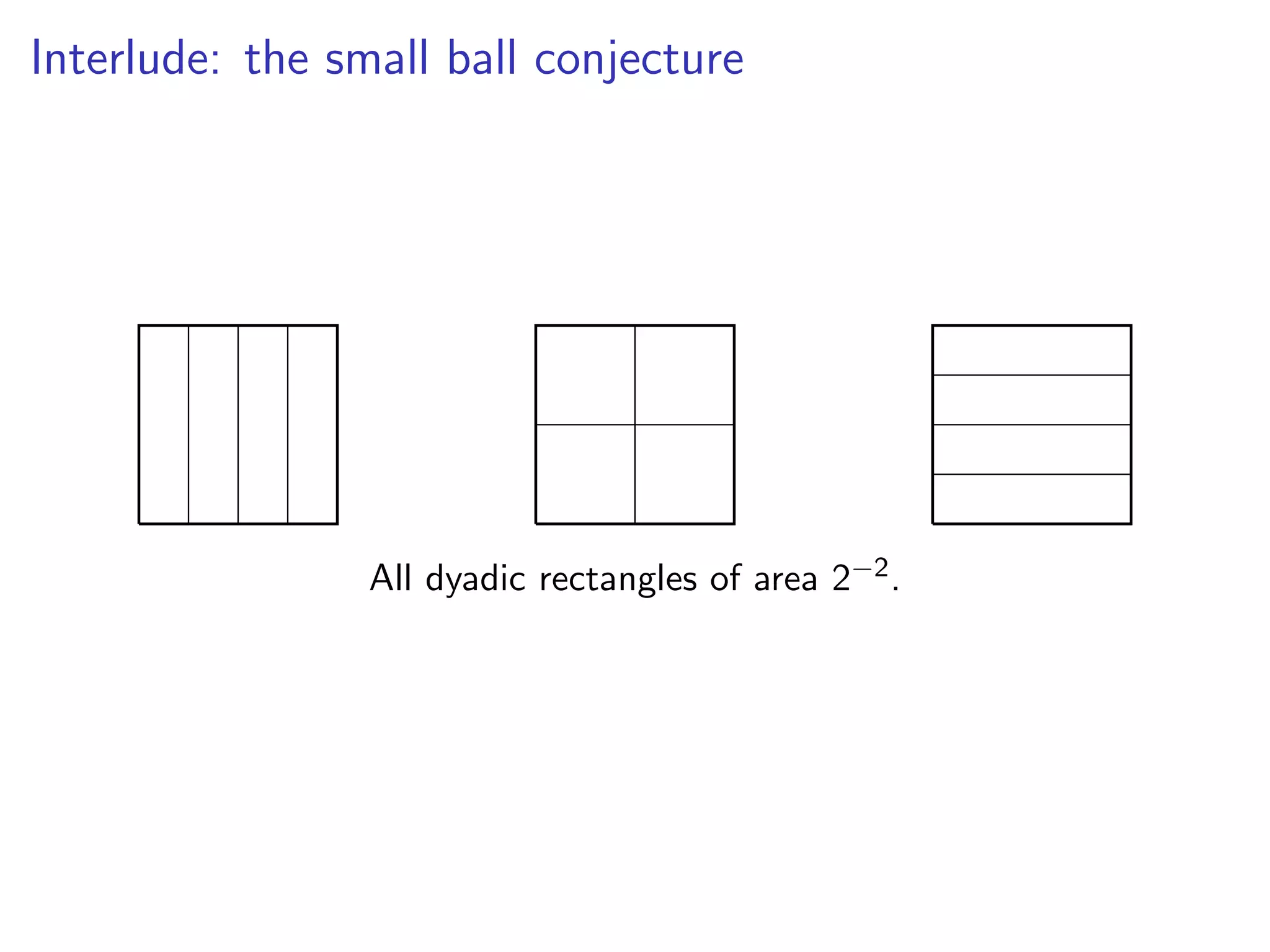


![Problem with the Standard Dogma
Star discrepancy.
D⇤
N(X) = sup
R⇢[0,1]d
# {i : xi 2 R}
N
|R|
The constructions achieving
D⇤
N .
(log N)d 1
N
start being e↵ective around N dd (actually a bit larger even).
More or less totally useless in high dimensions.](https://image.slidesharecdn.com/jittered-171215153348/75/QMC-Program-Trends-and-Advances-in-Monte-Carlo-Sampling-Algorithms-Workshop-Jittered-Sampling-Bounds-Problems-Stefan-Steinberger-Dec-14-2017-11-2048.jpg)
![Monte Carlo strikes back
Star discrepancy.
D⇤
N(X) = sup
R⇢[0,1]d
# {i : xi 2 R}
N
|R|
We want error bounds in N, d!
(Heinrich, Novak, Wasilkowski, Wozniakowski, 2002)
There are points
D⇤
N(X) .
d
p
N
.
This is still the best result. (Aistleitner 2011: constant c = 10).
How do you get these points? Monte Carlo](https://image.slidesharecdn.com/jittered-171215153348/75/QMC-Program-Trends-and-Advances-in-Monte-Carlo-Sampling-Algorithms-Workshop-Jittered-Sampling-Bounds-Problems-Stefan-Steinberger-Dec-14-2017-12-2048.jpg)





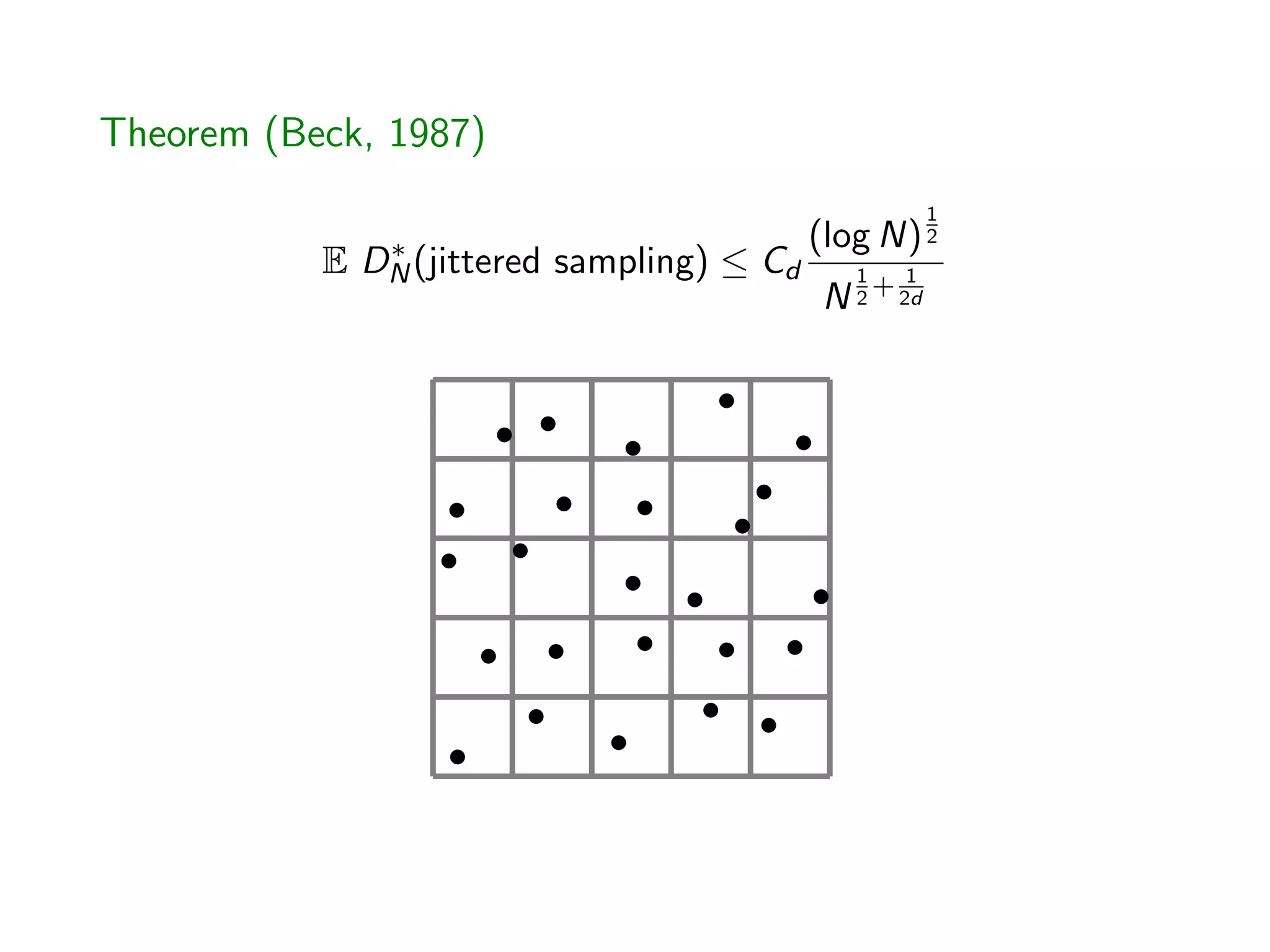


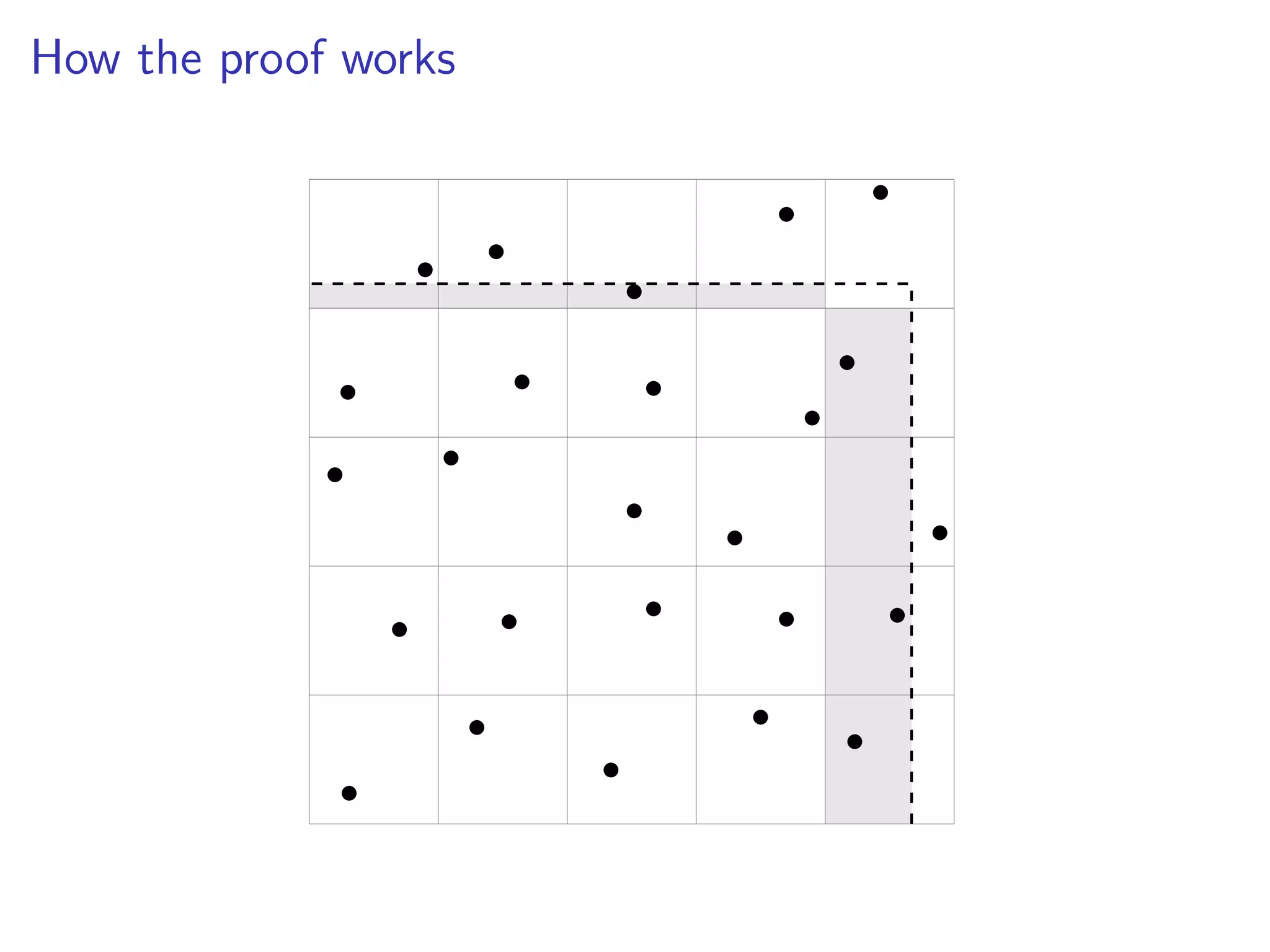
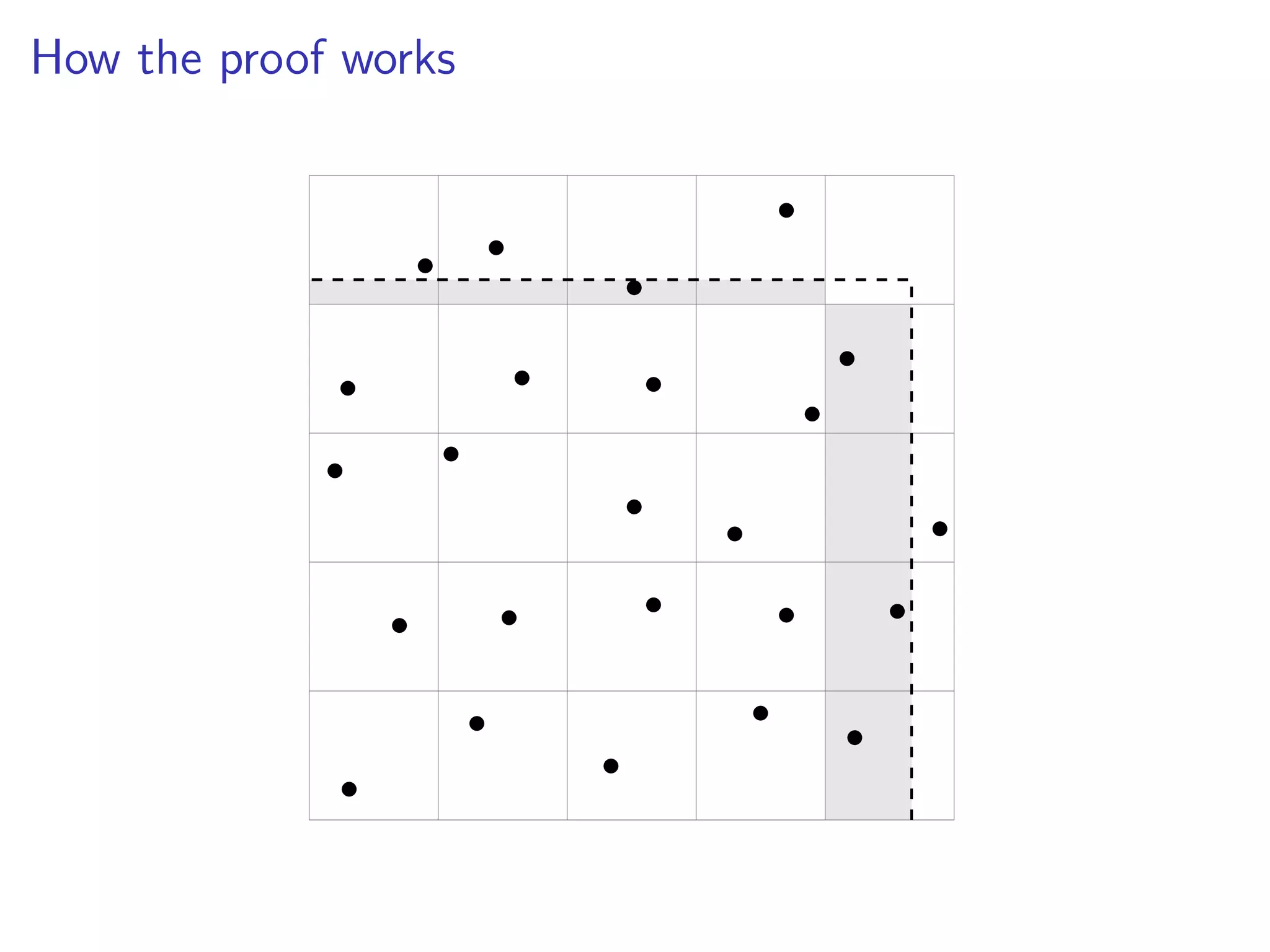
![How the proof works
• •
•
•
Maximize discrepancy over
p
N dimensional set in [0, N 1/2].
DN ⇠
pp
N
p
N
1
p
N
=
1
N3/4
.
I lose a logarithm
I union bound on the other cubes](https://image.slidesharecdn.com/jittered-171215153348/75/QMC-Program-Trends-and-Advances-in-Monte-Carlo-Sampling-Algorithms-Workshop-Jittered-Sampling-Bounds-Problems-Stefan-Steinberger-Dec-14-2017-23-2048.jpg)
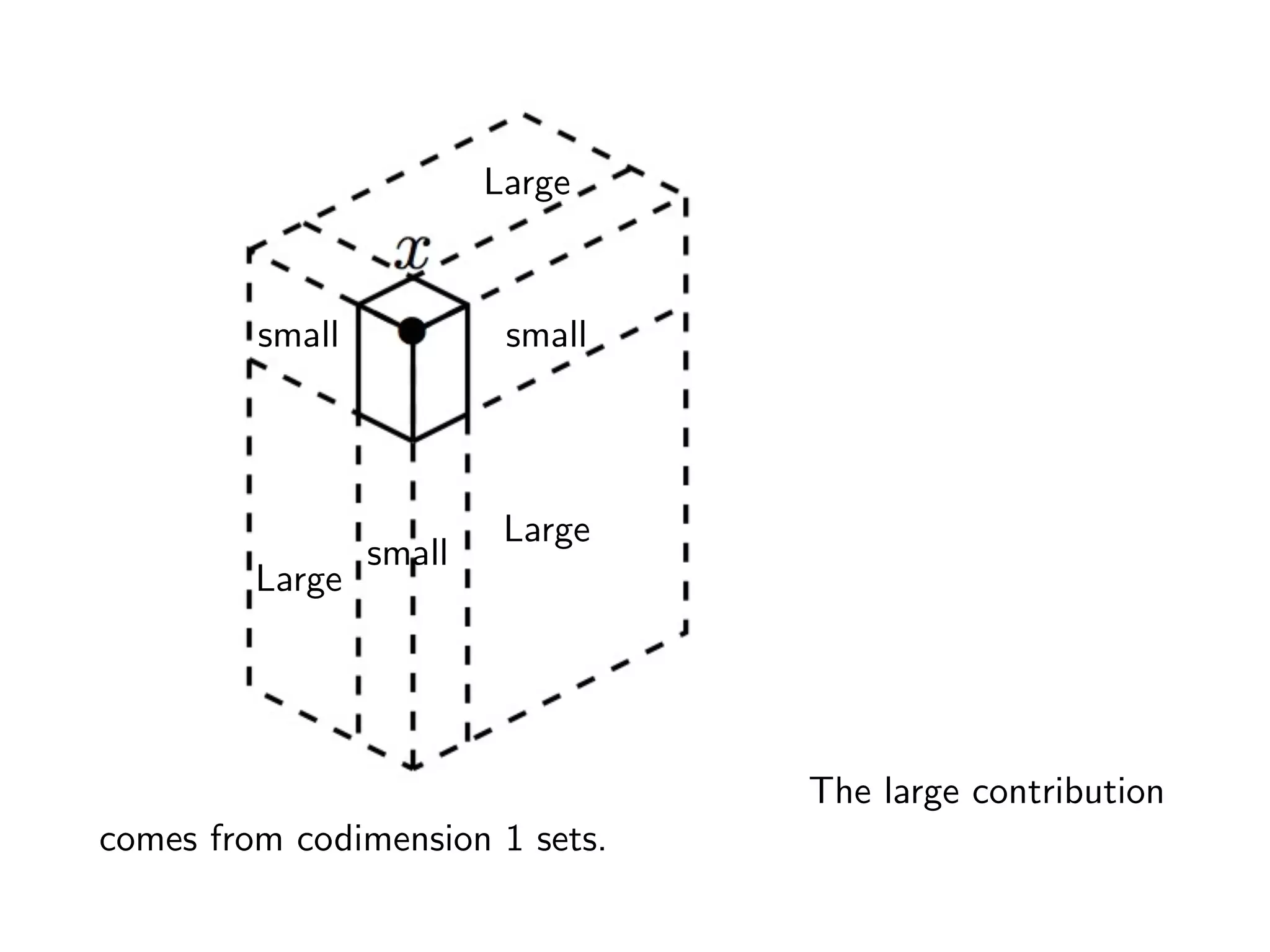

![Sharp Dvoretzy-Kiefer-Wolfowitz inequality (Massart, 1990)
If z1, z2, . . . , zk are independently and uniformly distributed
random variables in [0, 1], then
P
✓
sup
0z1
# {1 ` k : 0 z` z}
k
z > "
◆
2e 2k"2
.
limit ! Brownian Bridge ! Kolmogorov-Smirnov distribution](https://image.slidesharecdn.com/jittered-171215153348/75/QMC-Program-Trends-and-Advances-in-Monte-Carlo-Sampling-Algorithms-Workshop-Jittered-Sampling-Bounds-Problems-Stefan-Steinberger-Dec-14-2017-26-2048.jpg)


![What partition gives the best jittered sampling?
You want to decompose [0, 1]2 into 4 sets such that the associated
jittered sampling construction is as e↵ective as possible. How?
•
•
•
•
Is this good? Is this bad? Will it be into 4 parts of same volume?
We don’t actually know.](https://image.slidesharecdn.com/jittered-171215153348/75/QMC-Program-Trends-and-Advances-in-Monte-Carlo-Sampling-Algorithms-Workshop-Jittered-Sampling-Bounds-Problems-Stefan-Steinberger-Dec-14-2017-29-2048.jpg)
![Jittered sampling always improves: variance reduction
Decompose [0, 1]d into sets of equal measure
[0, 1]d
=
N[
i=1
⌦i such that 8 1 i N : |⌦i | =
1
N
and measure using the L2 discrepancy
L2(A) :=
Z
[0,1]d
#A [0, x]
#A
|[0, x]|
2
dx
!1
2
.
Observation (Pausinger and S., 2015)
E L2(Jittered Sampling⌦)2
E L2(Purely randomN)2
,](https://image.slidesharecdn.com/jittered-171215153348/75/QMC-Program-Trends-and-Advances-in-Monte-Carlo-Sampling-Algorithms-Workshop-Jittered-Sampling-Bounds-Problems-Stefan-Steinberger-Dec-14-2017-30-2048.jpg)


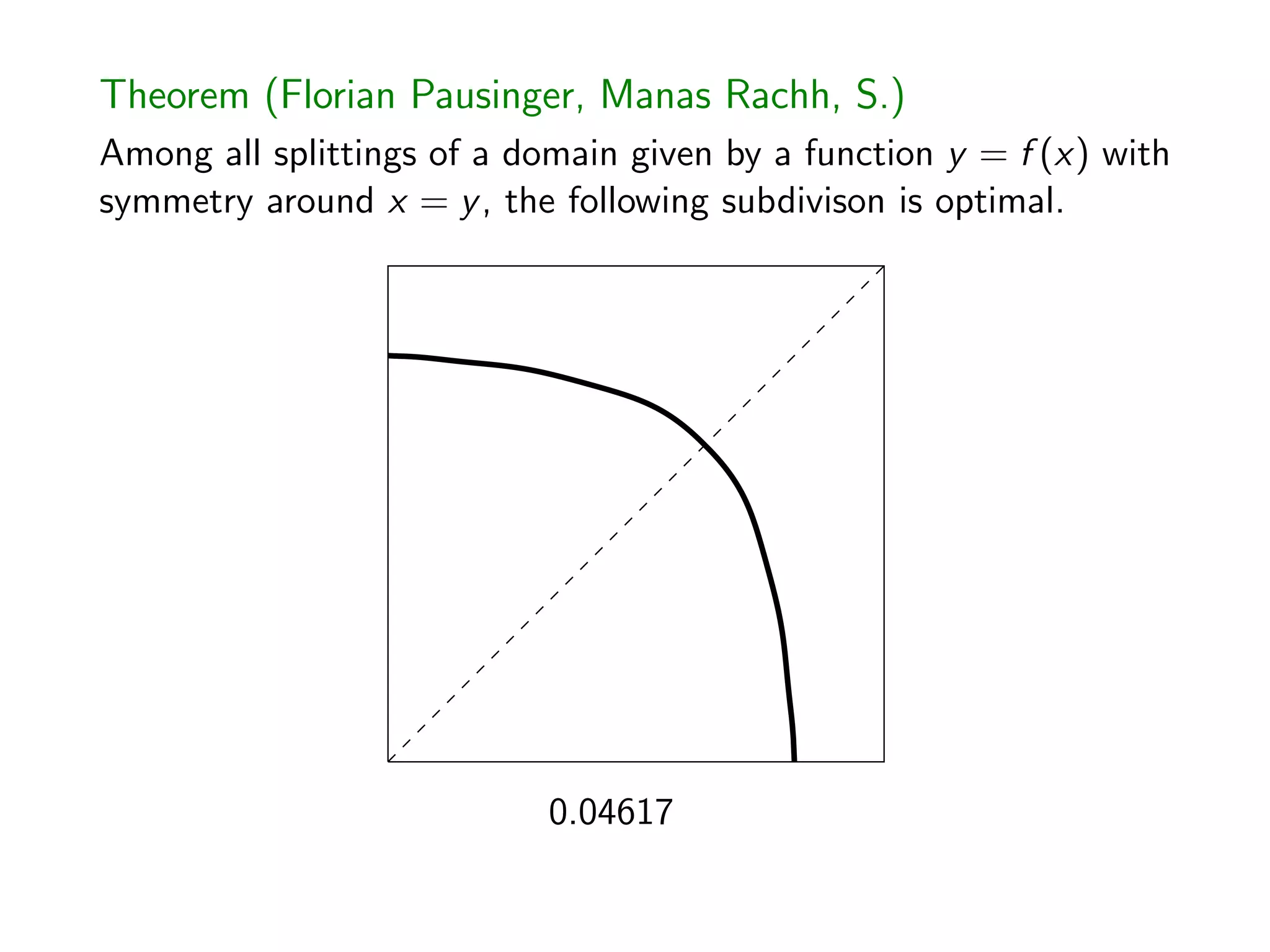
![The Most Nonlinear Integral Equation I’ve Ever Seen
Theorem (Florian Pausinger, Manas Rachh, S.)
Any optimal monotonically decreasing function g(x) whose graph
is symmetric about y = x satisfies, for 0 x g 1(0),
(1 2p 4xg(x)) (1 g(x)) + (4p 1)x 1 g(x)2
4
Z g 1(0)
g(x)
(1 y)g (y)dy + g0
(x) (1 2p 4xg(x)) (1 x)
+ (4p 1)g(x) 1 x2
4
Z g 1(0)
x
(1 y)g(y)dy = 0.
Question. How to do 3 points in [0, 1]2? Simple rules?](https://image.slidesharecdn.com/jittered-171215153348/75/QMC-Program-Trends-and-Advances-in-Monte-Carlo-Sampling-Algorithms-Workshop-Jittered-Sampling-Bounds-Problems-Stefan-Steinberger-Dec-14-2017-34-2048.jpg)

The document discusses jittered sampling and its implications for minimizing star discrepancy in quasi-Monte Carlo methods, exploring various conjectures related to point distributions. It presents theorems and results regarding the bounds of star discrepancy, the effectiveness of randomized point distributions, and the impact of dimension on the performance of these methods. Additionally, the document touches on the small ball conjecture and provides insights into recent advances and challenges in the field.