Downloaded 20 times





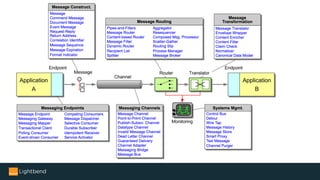

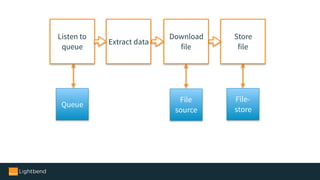
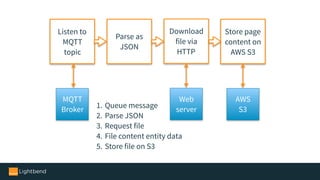
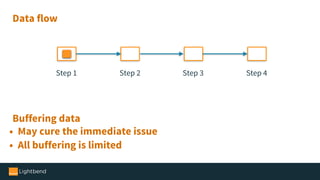
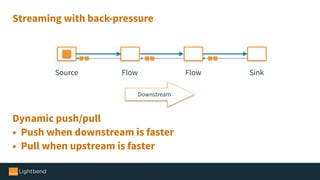



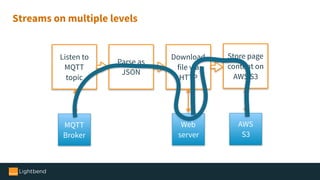



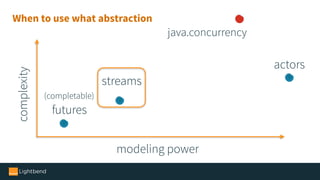

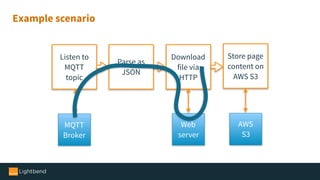
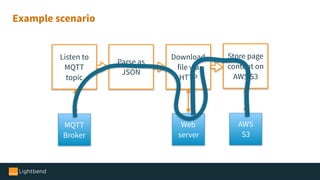





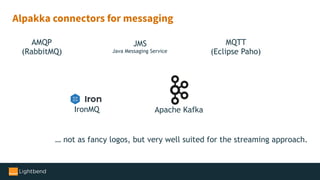




The document introduces Alpakka, a reactive enterprise integration library for Java and Scala that leverages reactive streams and Akka for efficient data processing and integration. It covers the evolution and features of Alpakka, including its connectors for various cloud services and data stores, as well as its comparison with Apache Camel. The text emphasizes the importance of back-pressure in reactive integrations and outlines the roadmap for Alpakka 1.0, inviting community involvement.























































































