Download as PDF, PPTX






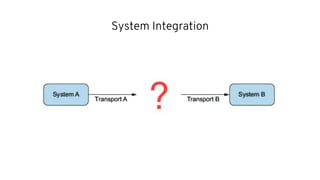
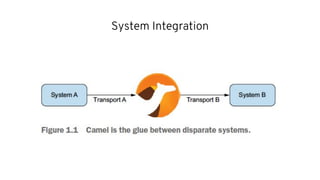

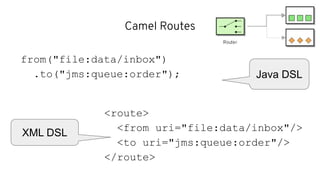







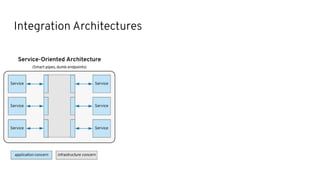
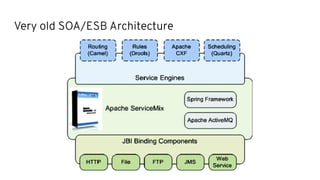
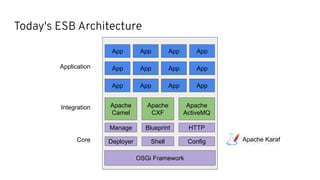
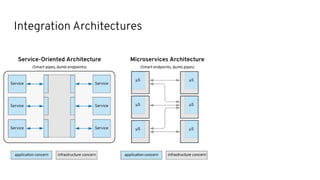
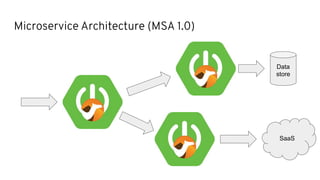
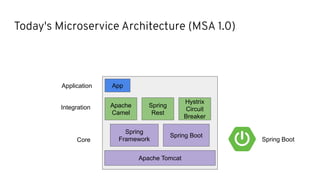
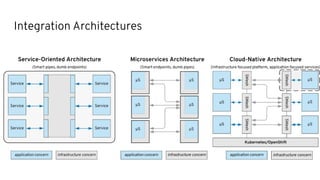
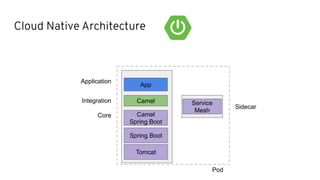
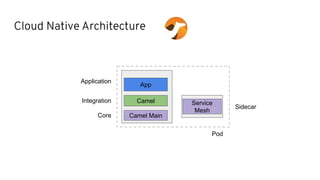
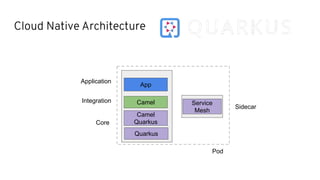
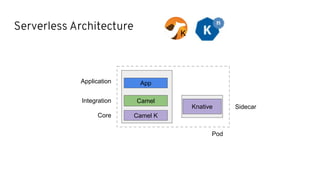





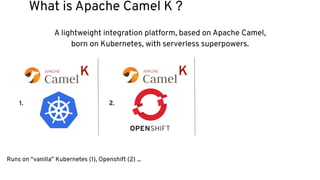
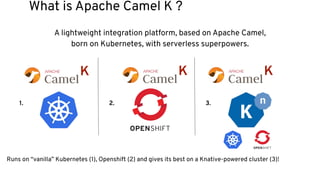


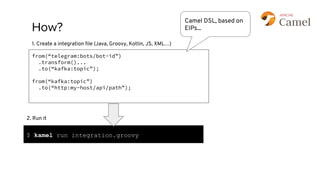
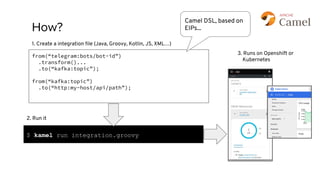
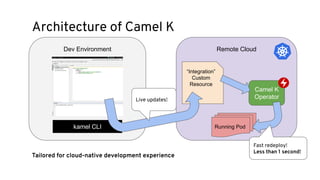
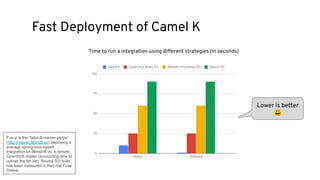
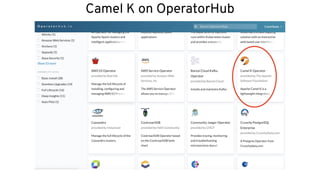
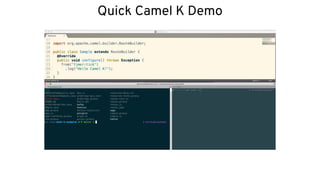
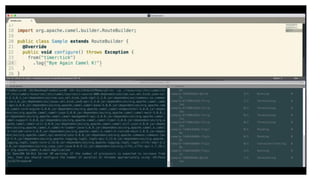






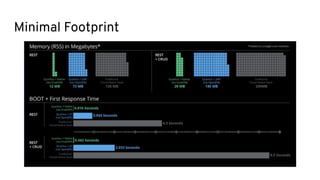
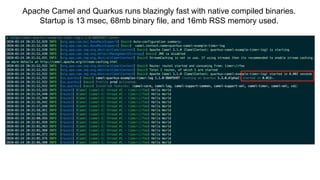


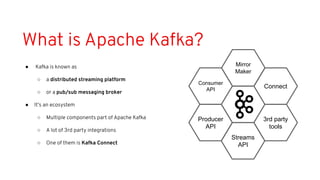
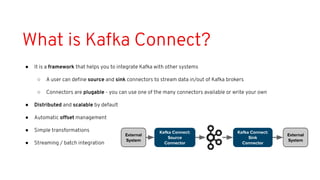









This document discusses best practices for middleware and integration architecture modernization using Apache Camel. It provides an overview of Apache Camel, including what it is, how it works through routes, and the different Camel projects. It then covers trends in integration architecture like microservices, cloud native, and serverless. Key aspects of Camel K and Camel Quarkus are summarized. The document concludes with a brief discussion of the Camel Kafka Connector and pointers to additional resources.







![[Konveyor] migrate and modernize your application portfolio to kubernetes wit...](https://cdn.slidesharecdn.com/ss_thumbnails/konveyormigrateandmodernizeyourapplicationportfoliotokuberneteswithtackle-210728162324-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[jvmmeetup] next-gen integration with apache camel and quarkus.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/jvmmeetupnext-genintegrationwithapachecamelandquarkus-250822032223-c05a088e-thumbnail.jpg?width=640&height=640&fit=bounds)











































