Download as PDF, PPTX





















![WebSockets (Vue.js)
connect() {
this.socket = new WebSocket(
"ws://localhost:9000/api/transfer/stream");
this.socket.onopen = () => {
this.socket.onmessage = (e) => {
let event = JSON.parse(e.data);
var index = -1;
// 1. determine if we're updating a row (initiated)
// or adding a new row (completed)
for (var i = 0; i < this.transfers.length; i++) {
if (this.transfers[i].id === event.id) {
index = i;
break;
}
}
if (index === -1) {
// unshift is similar to push, but prepends
this.transfers.unshift({
// ... 3. create object with id, status, etc
});
} else {
let t = {
// ... 4. create object with id, status, etc
};
this.transfers.splice(index, 1, t);
this.updateCashOnHand();
}
};
};
}](https://image.slidesharecdn.com/full-stack-reactive-190910152731/85/Full-Stack-Reactive-In-Practice-44-320.jpg)
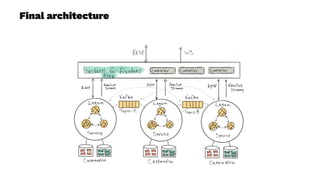

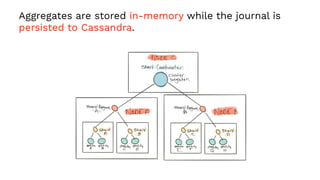
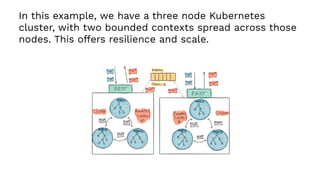




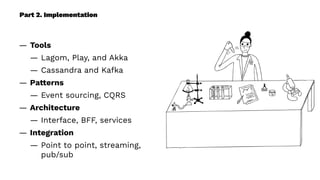
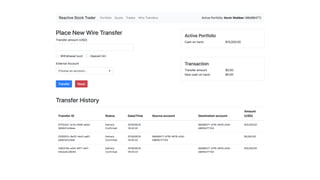
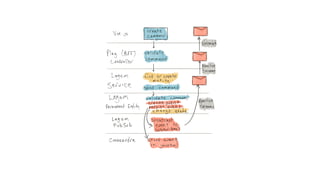
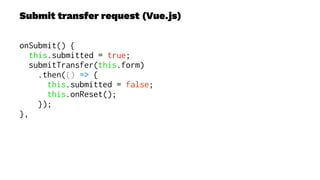
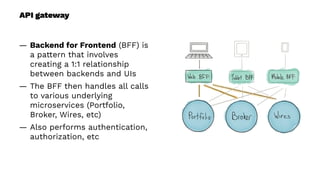
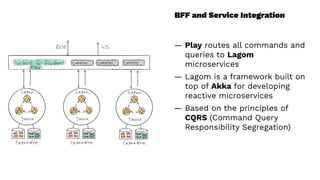
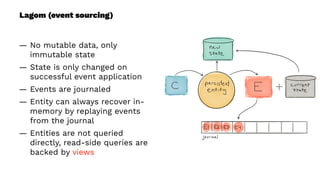
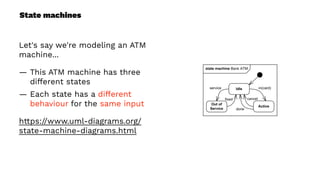
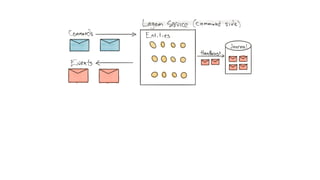
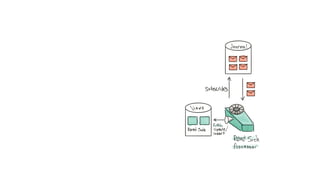
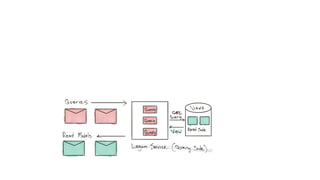
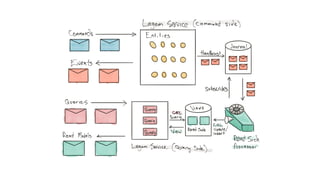
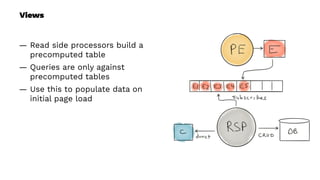
This document presents a real-world application of a full stack reactive architecture utilizing Command Query Responsibility Segregation (CQRS) and Event Sourcing (ES) principles, primarily through Java tools like Lagom, Play, and Akka. It explores the design, implementation, and deployment of reactive systems, emphasizing event-driven approaches and their integration with modern front-end frameworks like React and Vue. The content is geared towards engineering practices at Reading Plus, an adaptive platform for K-12 education, and highlights upcoming opportunities in engineering within a reactive context.























































































