Downloaded 22 times




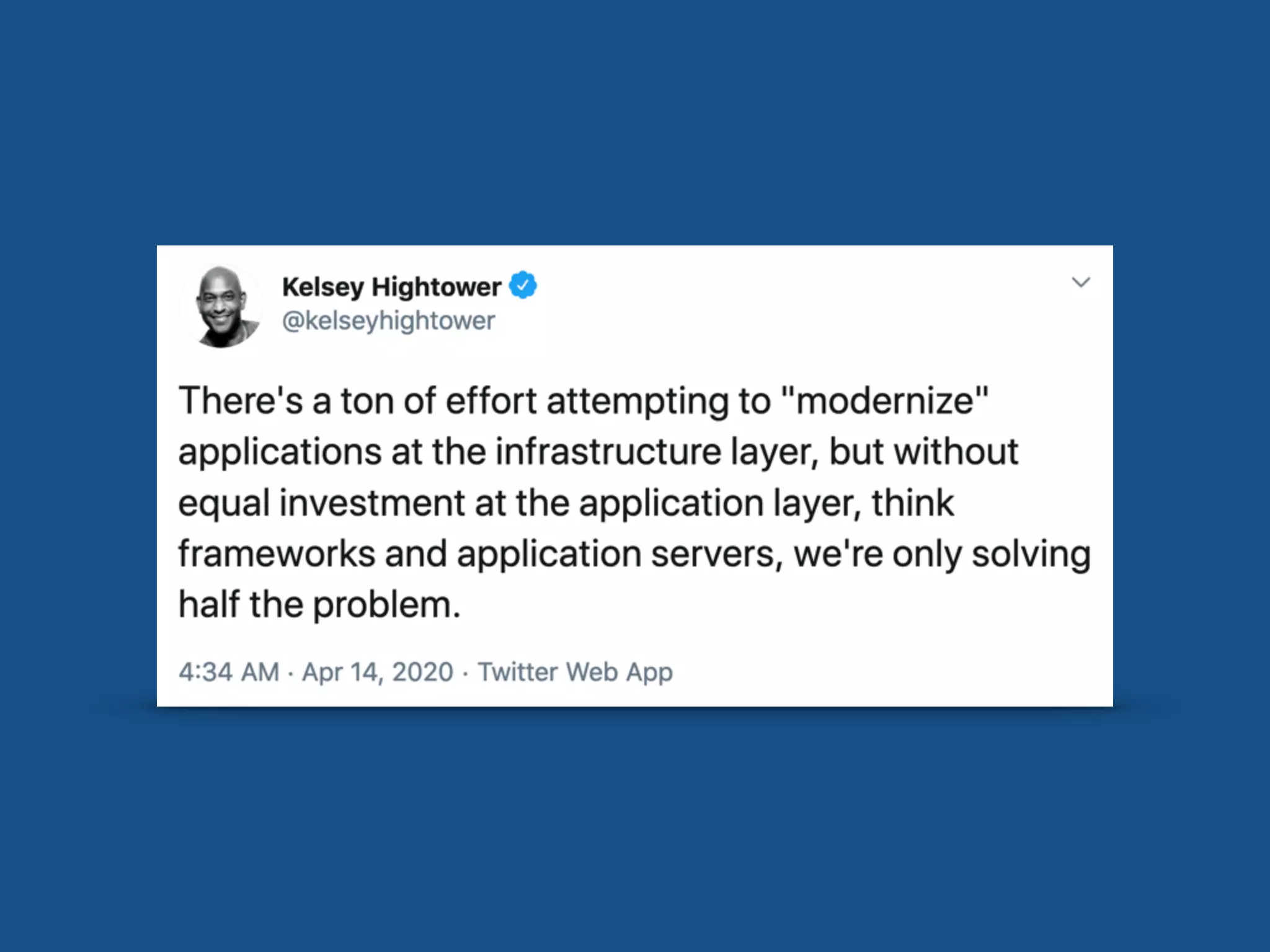












































































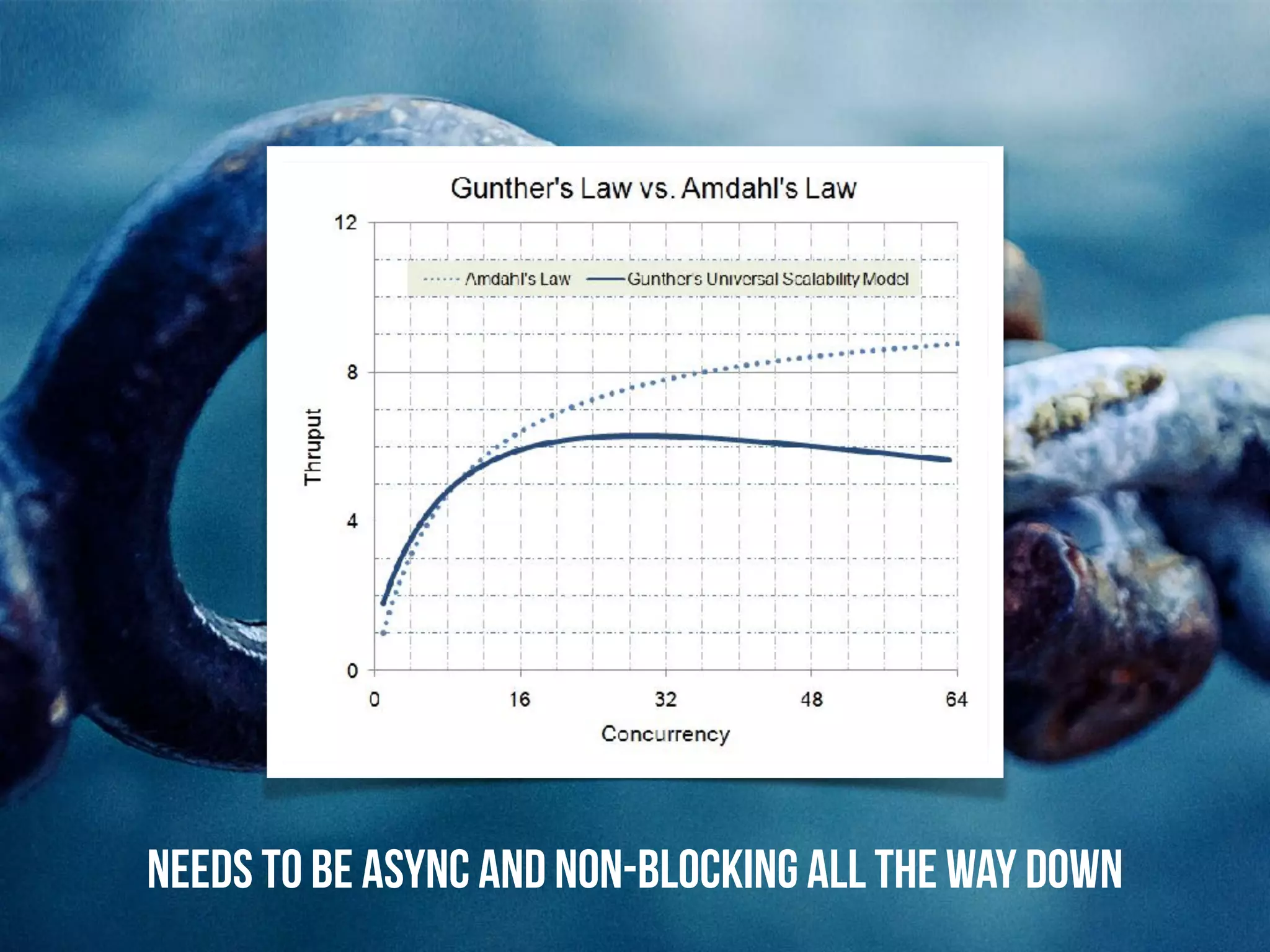








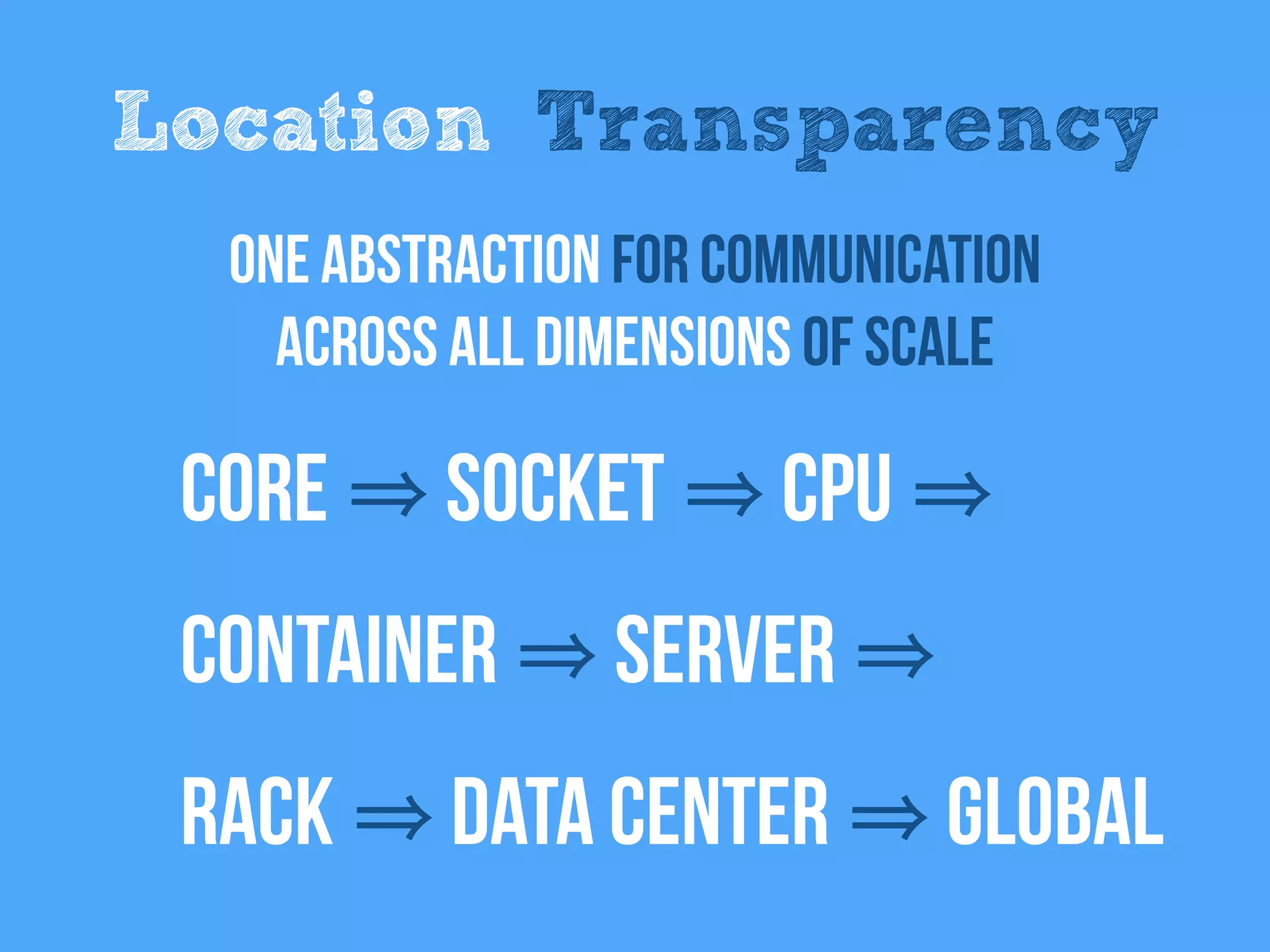














The document discusses the concept of cloud-native infrastructure, emphasizing that managing only the infrastructure is insufficient without considering the applications within it. It introduces reactive principles that help address the complexities of distributed systems, such as remaining responsive, accepting uncertainty, embracing failure, and asserting autonomy. By advocating for tailored consistency and decoupling time and space, the document suggests strategies for building resilient and flexible cloud-native applications.























































































