Downloaded 23 times








![@maasg
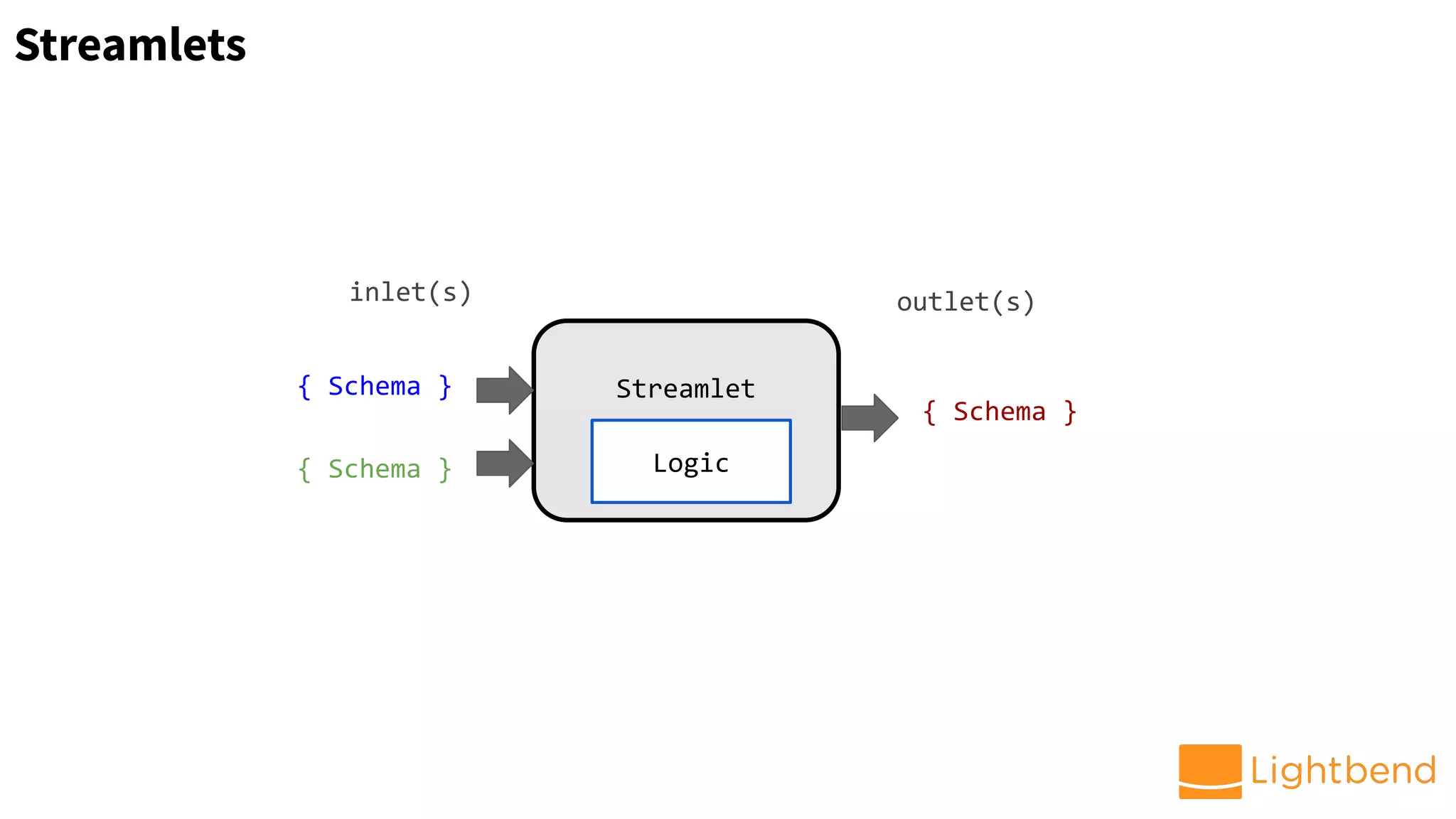
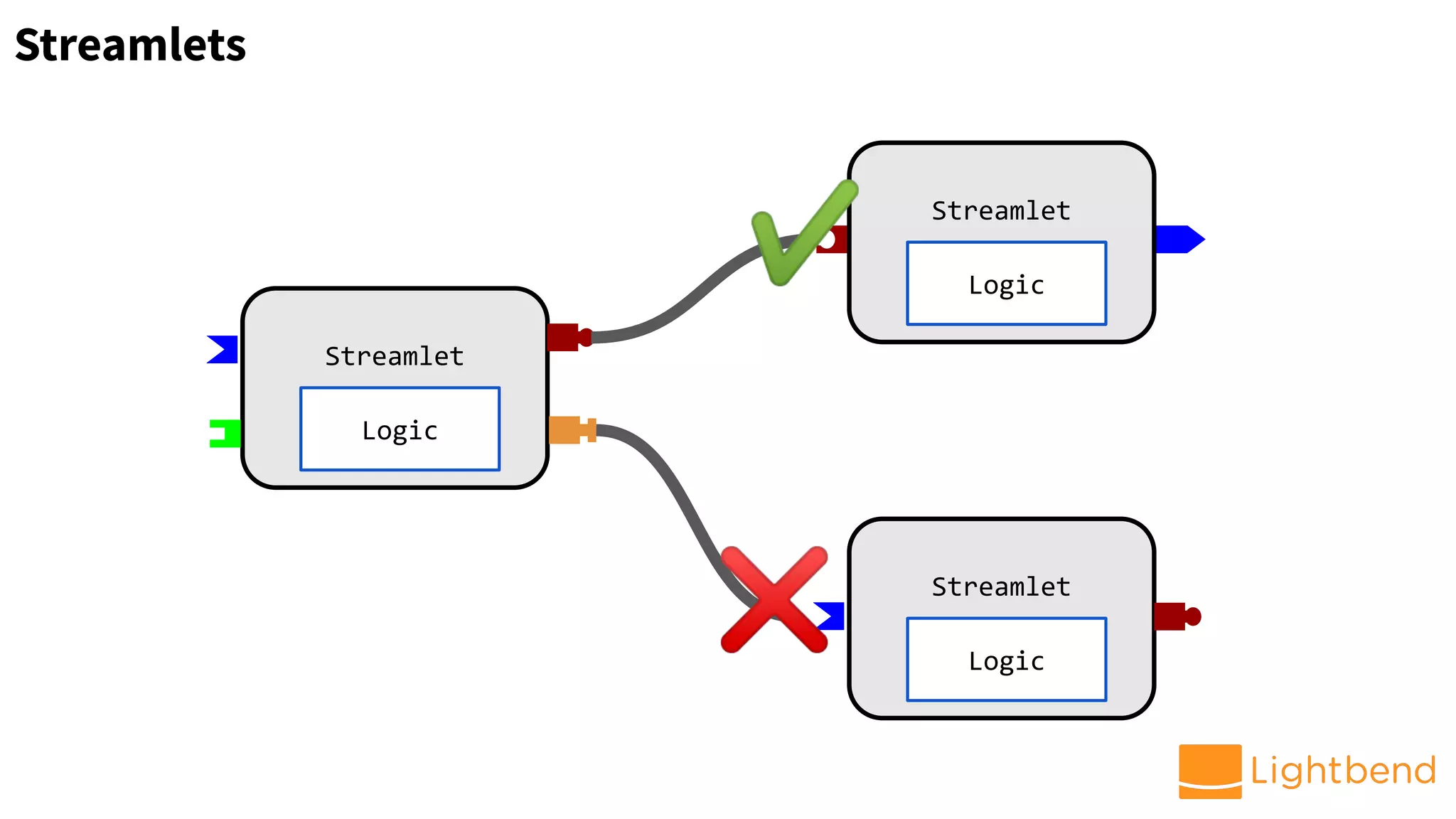
HTTP
ingress
[schema]
Enrichment
(+features)
Fraud ML
Scoring
Egress
(console)
Transactions](https://image.slidesharecdn.com/cloudflowfrauddetectionwithcloudflowwebinar2-200423135250/75/Detecting-Real-Time-Financial-Fraud-with-Cloudflow-on-Kubernetes-20-2048.jpg)
![@maasg
HTTP
ingress
[schema]
Enrichment
(+features)
Fraud ML
Scoring
Egress
(console)
Transactions
py
DT
Model
Persistent
Volume](https://image.slidesharecdn.com/cloudflowfrauddetectionwithcloudflowwebinar2-200423135250/75/Detecting-Real-Time-Financial-Fraud-with-Cloudflow-on-Kubernetes-21-2048.jpg)
![@maasg
HTTP
ingress
[schema]
Enrichment
(+features)
Fraud ML
Scoring
Egress
(console)
Transactions
py
DT
Model
Persistent
Volume](https://image.slidesharecdn.com/cloudflowfrauddetectionwithcloudflowwebinar2-200423135250/75/Detecting-Real-Time-Financial-Fraud-with-Cloudflow-on-Kubernetes-22-2048.jpg)
![@maasg
HTTP
ingress
[schema]
Enrichment
(+features)
Fraud ML
Scoring
Egress
(console)
Transactions
py
DT
Model
Persistent
Volume](https://image.slidesharecdn.com/cloudflowfrauddetectionwithcloudflowwebinar2-200423135250/75/Detecting-Real-Time-Financial-Fraud-with-Cloudflow-on-Kubernetes-23-2048.jpg)
![@maasg
HTTP
ingress
[schema]
Enrichment
(+features)
Fraud ML
Scoring
Egress
(console)
Transactions
py
DT
Model
Persistent
Volume](https://image.slidesharecdn.com/cloudflowfrauddetectionwithcloudflowwebinar2-200423135250/75/Detecting-Real-Time-Financial-Fraud-with-Cloudflow-on-Kubernetes-24-2048.jpg)
![@maasg
HTTP
ingress
[schema]
Enrichment
(+features)
Fraud ML
Scoring
Egress
(console)
Transactions
py
DT
Model
Persistent
Volume](https://image.slidesharecdn.com/cloudflowfrauddetectionwithcloudflowwebinar2-200423135250/75/Detecting-Real-Time-Financial-Fraud-with-Cloudflow-on-Kubernetes-25-2048.jpg)
![@maasg
HTTP
ingress
[schema]
Enrichment
(+features)
Fraud ML
Scoring
Egress
(console)
Transactions
py
DT
Model
Persistent
Volume](https://image.slidesharecdn.com/cloudflowfrauddetectionwithcloudflowwebinar2-200423135250/75/Detecting-Real-Time-Financial-Fraud-with-Cloudflow-on-Kubernetes-26-2048.jpg)
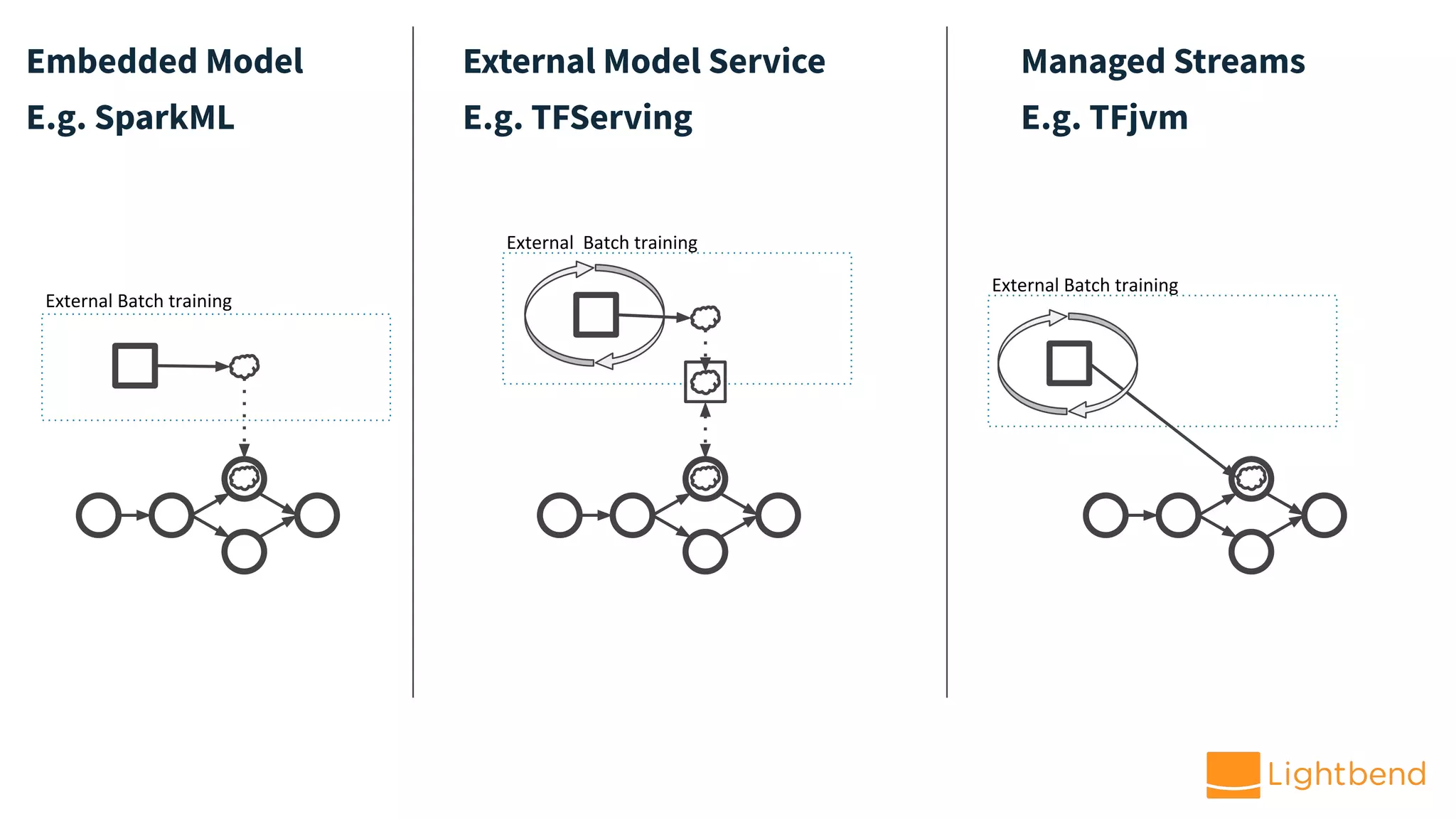




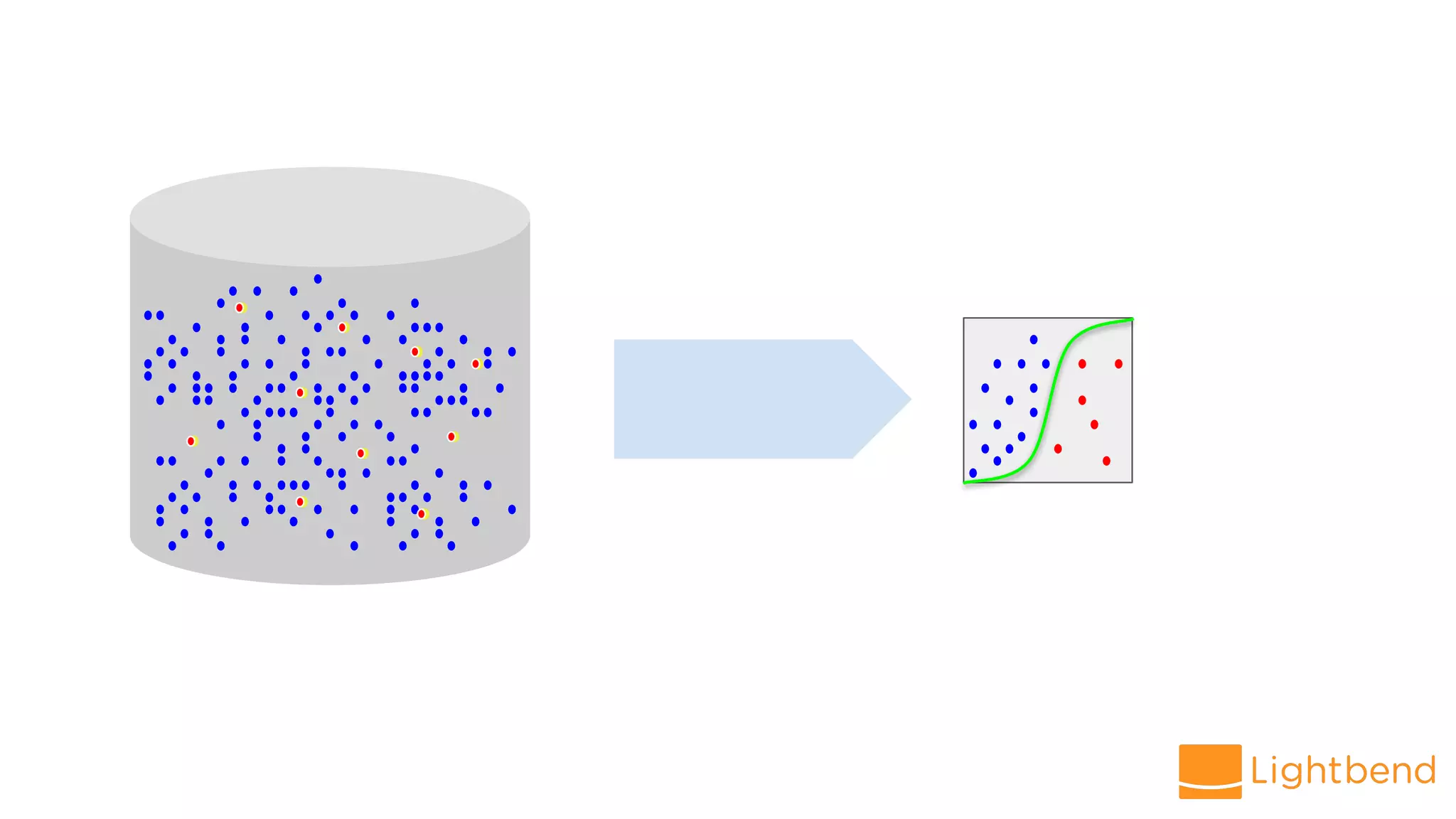
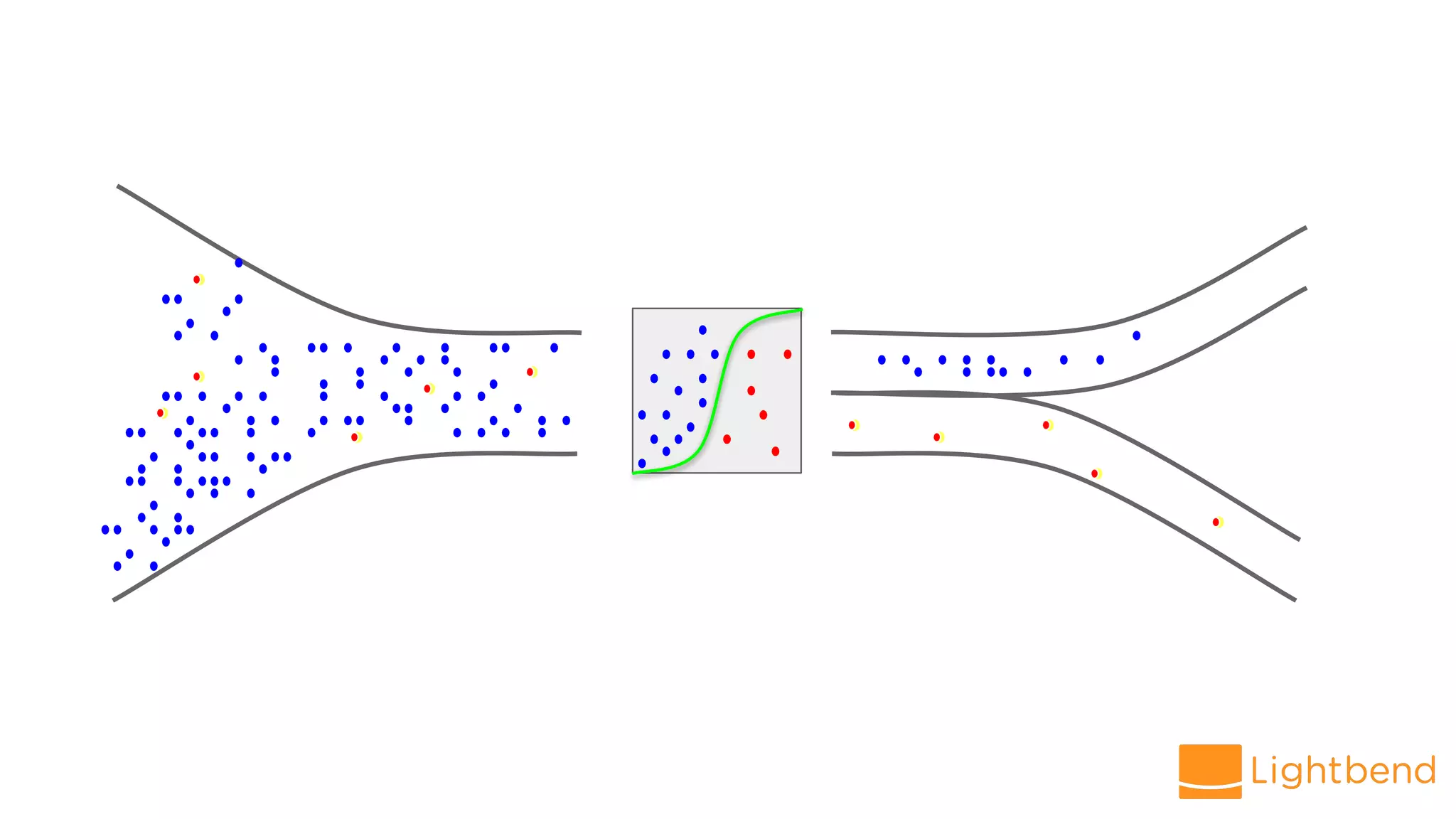
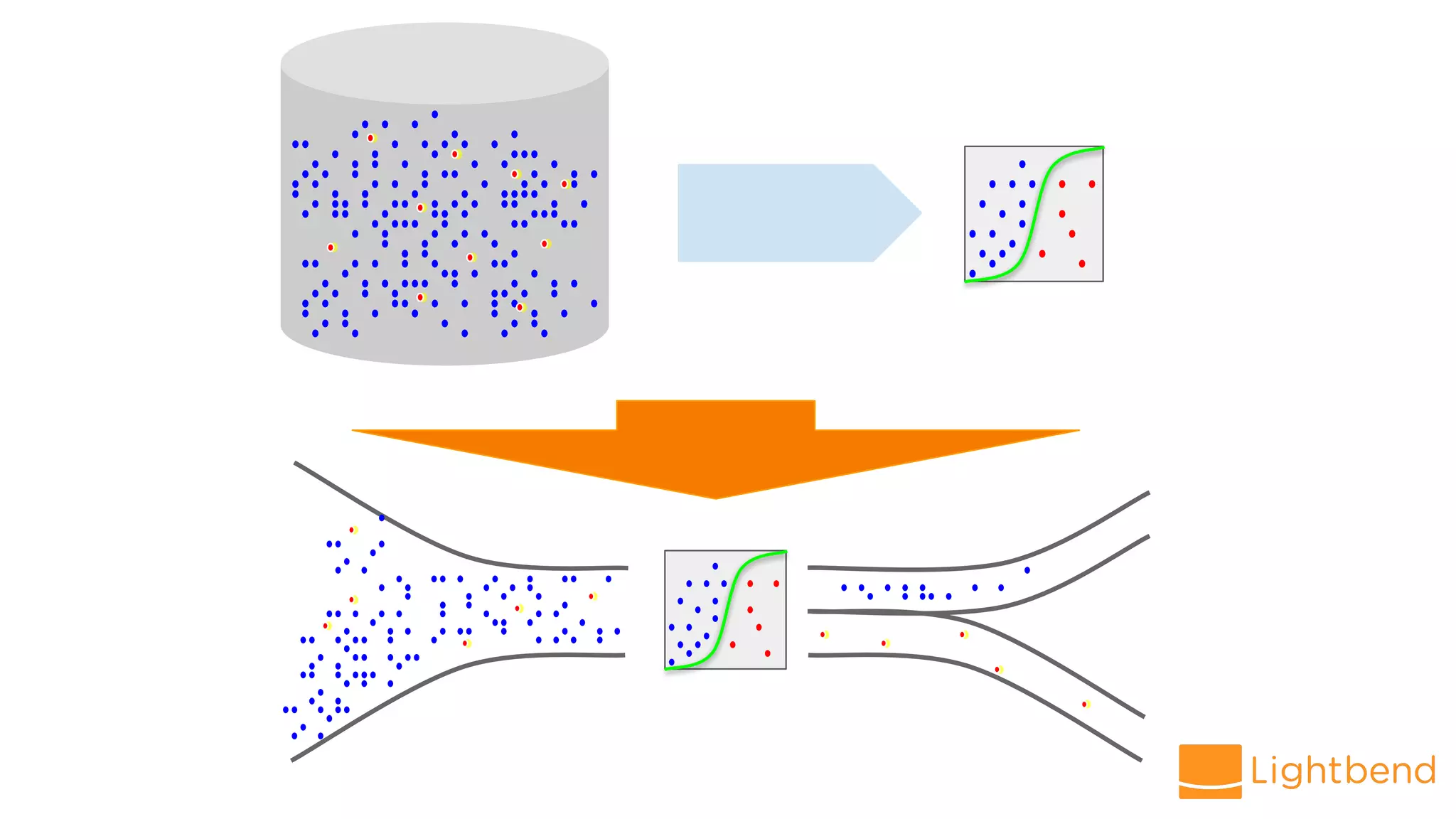
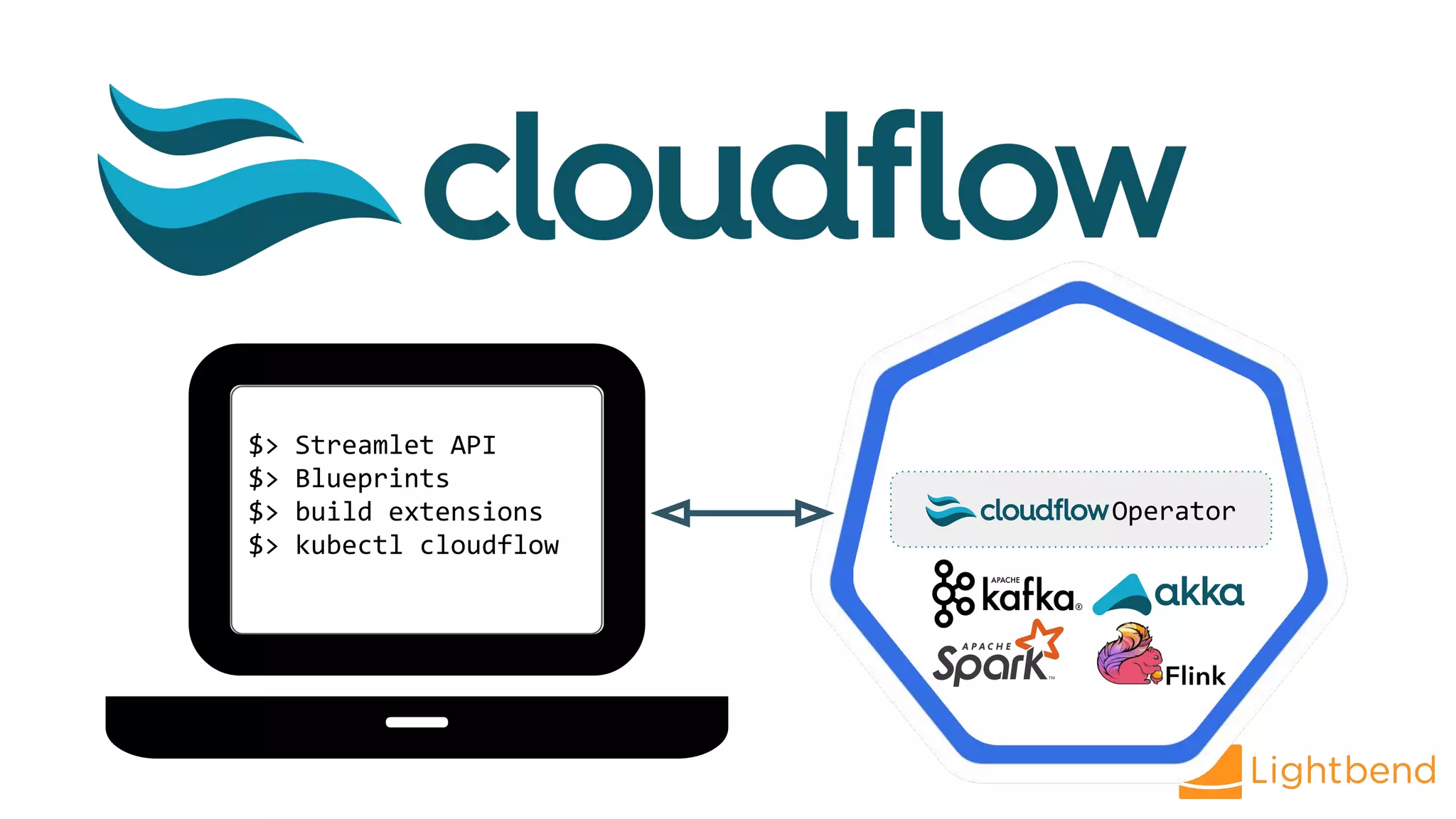
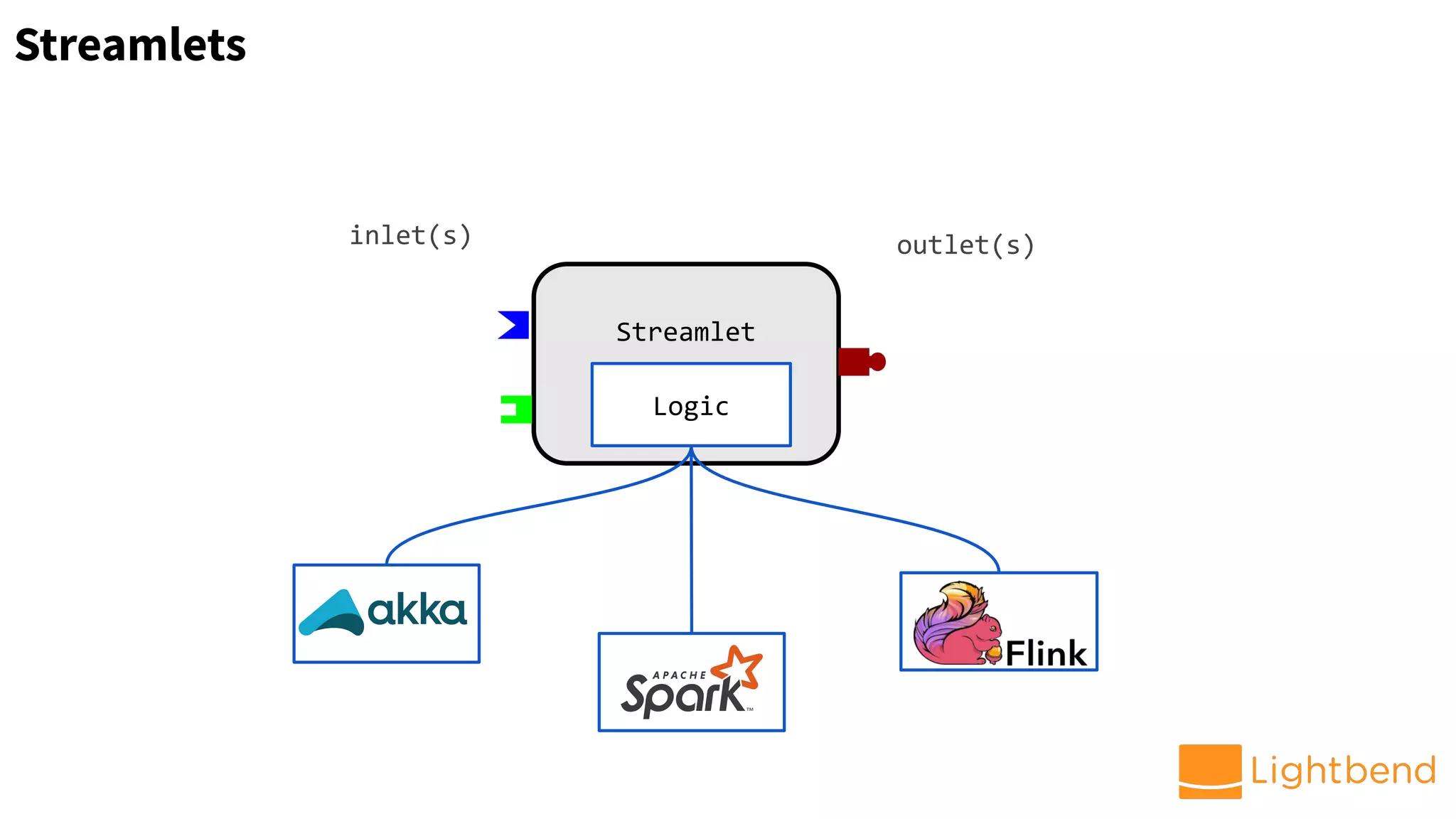
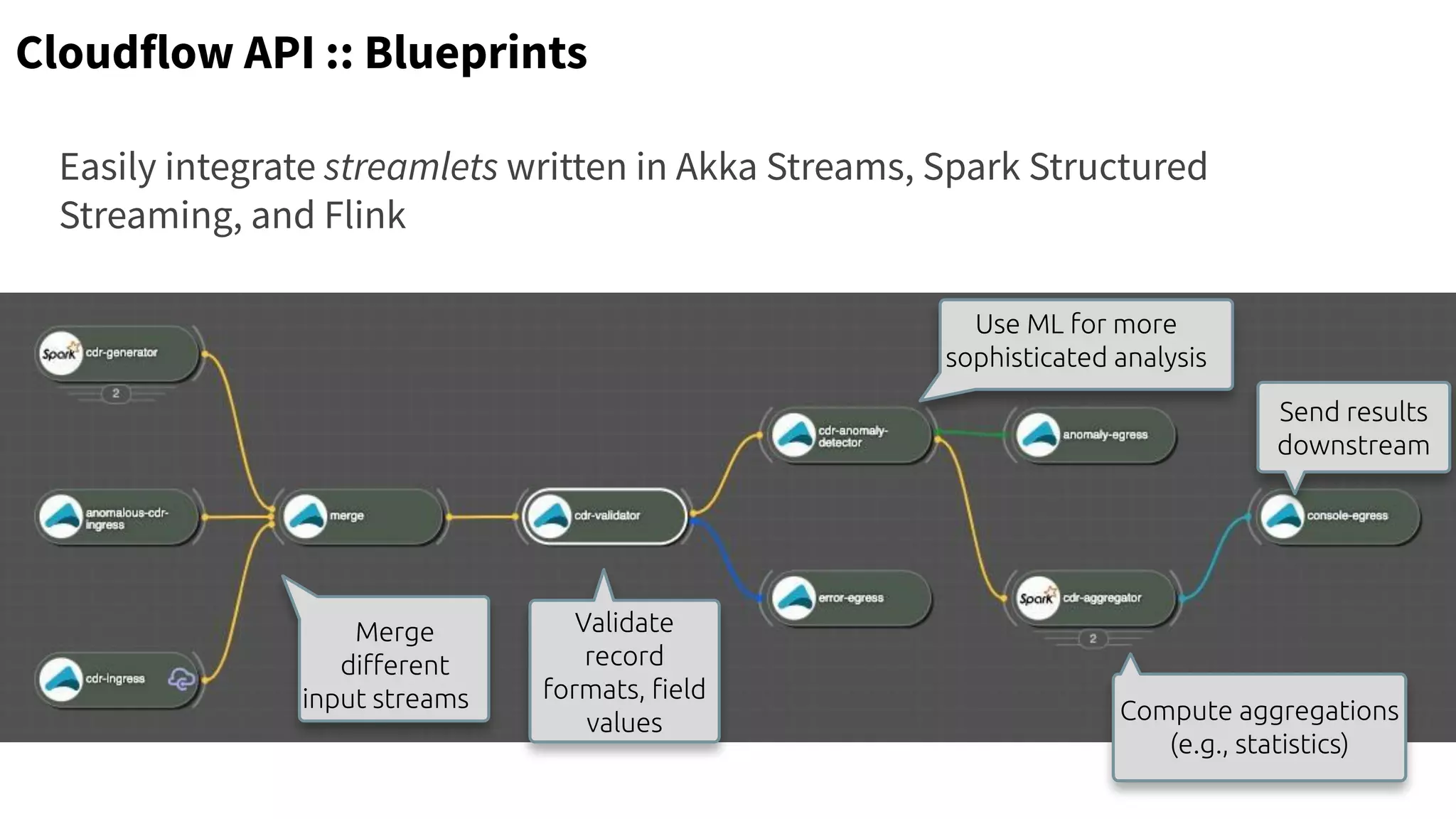
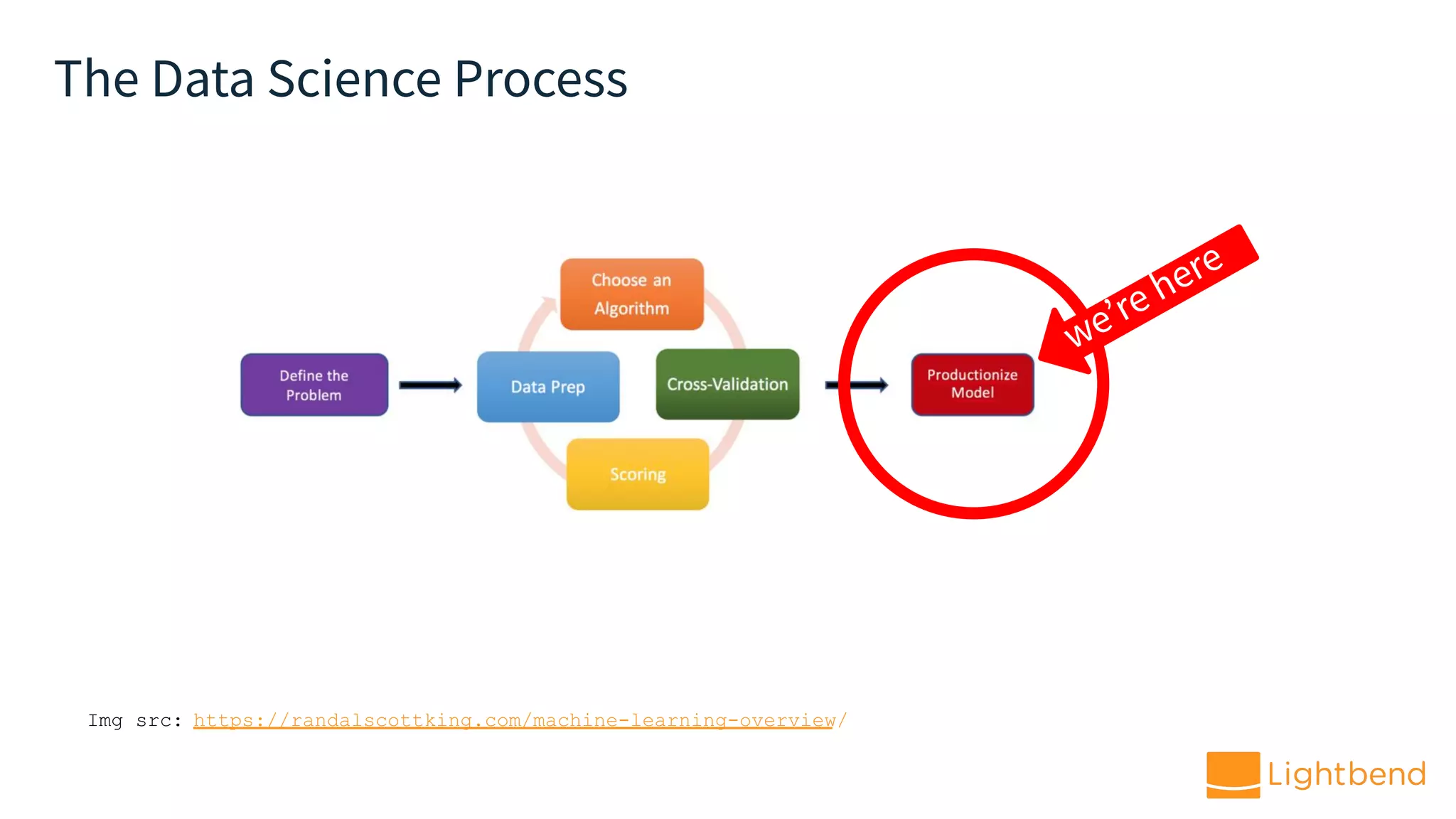
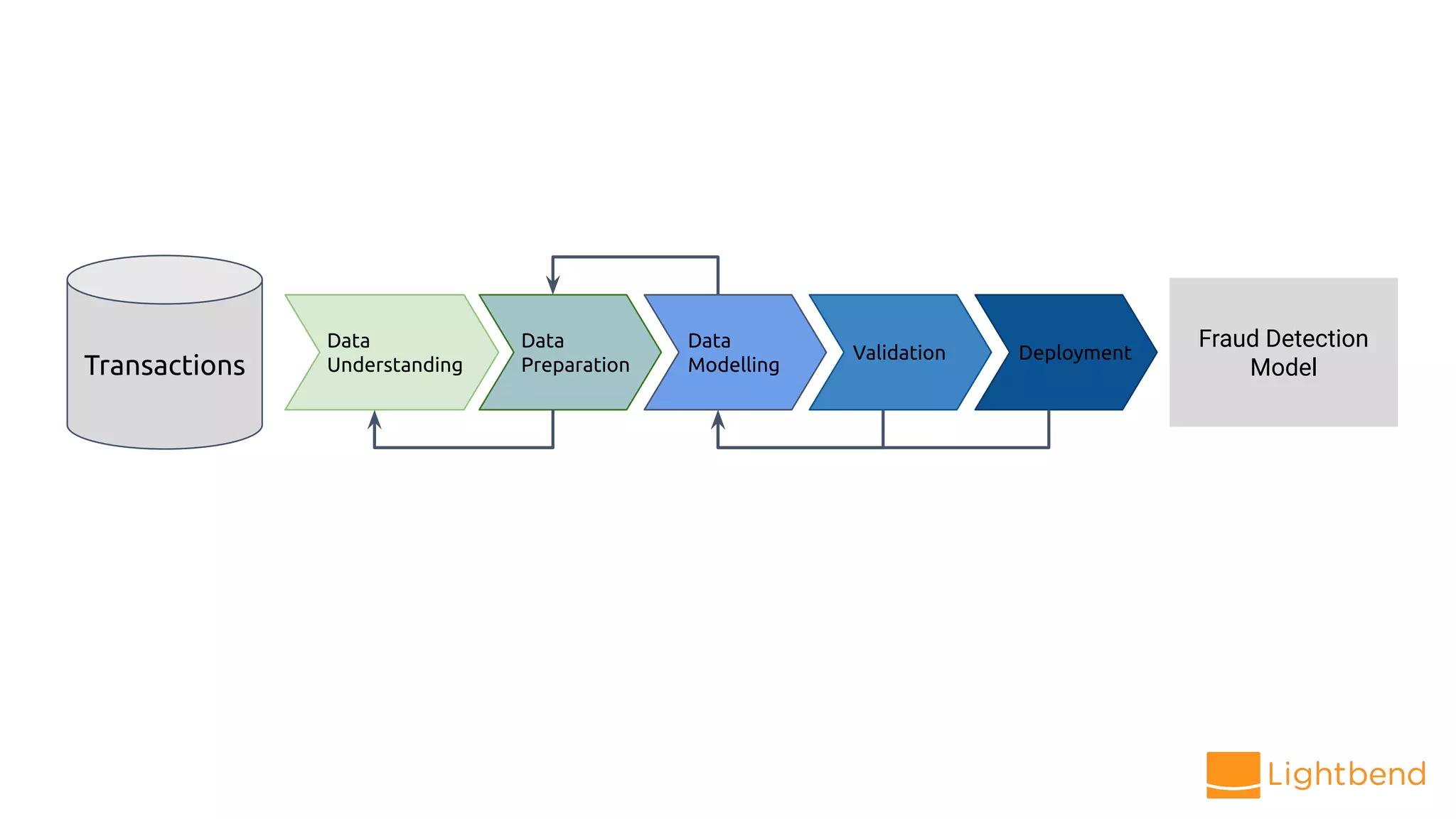
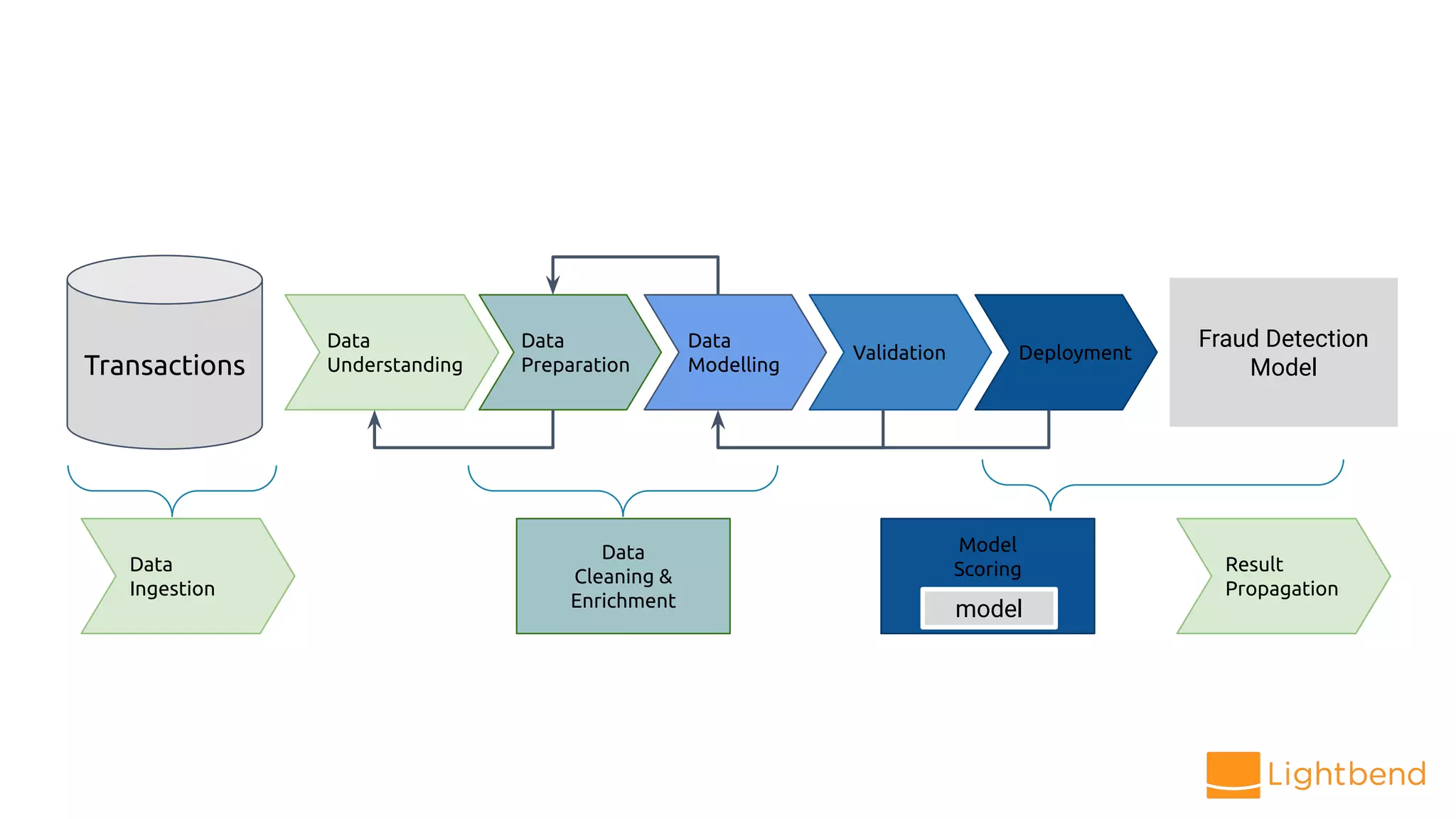
The document discusses the use of Cloudflow, a toolkit for developing and operating distributed streaming applications on Kubernetes, specifically for real-time financial fraud detection. It outlines the data science process, including model development and deployment, and highlights the integration of machine learning for enhanced analysis. The aim is to streamline the collaboration between data science and data engineering to create smarter applications in enterprises.




















































































