Download to read offline









![#Connecting to a BioSQL database -http://biopython.org/wiki/BioSQL
from Bio import Entrez
from Bio import SeqIO
from BioSQL import BioSeqDatabase
#db= pymysql.connect(host = "localhost",port=8889,user="root",passwd="root",db="db")
server = BioSeqDatabase.open_database(driver = "pymysql",host = "localhost",port=8889,user="root",passwd="root",db="db")
#db = server.new_database("test")
db = server["test"]
import pprint
Entrez.email = "A.N.Other@example.com"
handle = Entrez.efetch(db="nucleotide", rettype="gb", retmode="text", id="6273291,6273290,6273289")
print ("Loading into BIOSQL")
count = db.load(SeqIO.parse(handle, "genbank"))
print ("Loaded %i records" % count)
server.adaptor.commit()
for seq_record in SeqIO.parse(handle, "genbank"):
print (seq_record.id, seq_record.description[:50] + "...")
print ("Sequence length %i," % len(seq_record))
print ("%i features," % len(seq_record.features))
print ("from: %s" % seq_record.annotations["source"])
pprint.pprint(seq_record)
# pprint ("Loading")
#load into BIOSQL
# db.load_seqrecord(seq_record)](https://image.slidesharecdn.com/20180320biologicaldatabasespart3-180321074857/85/2018-03-20_biological_databases_part3-13-320.jpg)
















![example
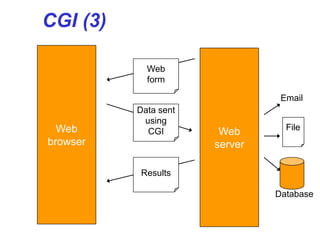
• HTML file greet.html has
<form action="greet.php" method="get"><p>
your last name: <input type="text"
name="lastname"/></p></form>
• PHP file greet.php has
<?php
print "Hello ";
print $_GET['lastname'];
?>
in addition to the usual HTML stuff.](https://image.slidesharecdn.com/20180320biologicaldatabasespart3-180321074857/85/2018-03-20_biological_databases_part3-33-320.jpg)


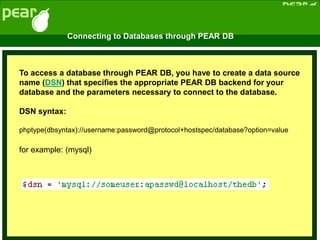







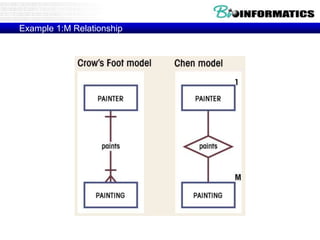
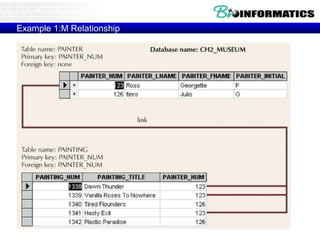
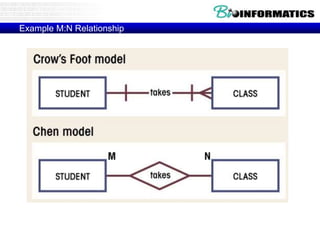
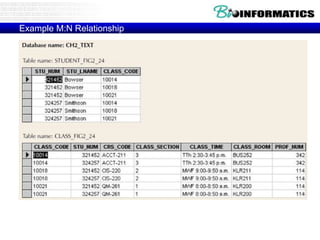
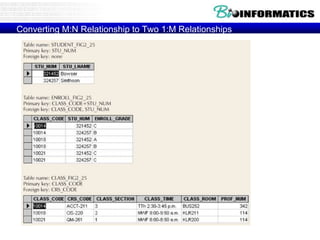
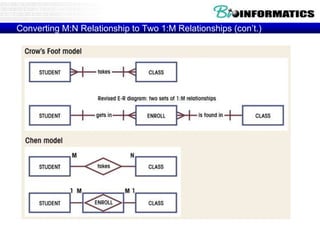
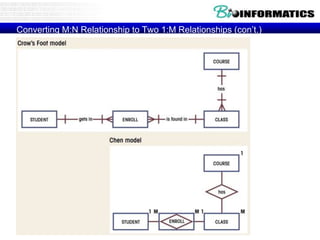
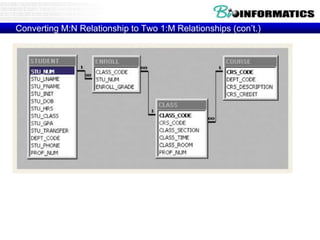
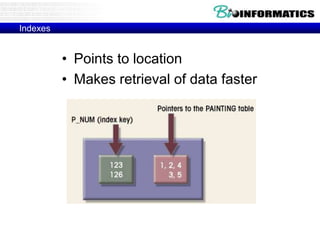


















![Commit
• A transaction reaches its commit point when all of its
operations that access the database have been
executed successfully and the effect of all transaction
operations on the database have been recorded in the
log
• Beyond the commit point, the effect of a transaction
is assumed to be permanently recorded in the
database
• If a transaction does not reach its commit point and
there is no [commit, T ]
record in the log file, this transaction has to be rolled
back
• Read committed protocol:
– If a transaction T updates a database item A, other transactions can read A only after T
has committed](https://image.slidesharecdn.com/20180320biologicaldatabasespart3-180321074857/85/2018-03-20_biological_databases_part3-72-320.jpg)


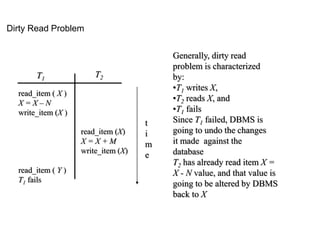



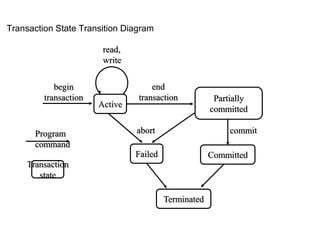
![Log File
• To be able to recover from failures
DBMS maintains a log file
• Typically, a log file contains records
with following contents:
[start_transaction, T ] (*T is transaction
id*)
[write_item, T, X, old_value, new_value]
[read_item,T, X ] (*optional*)
[commit, T ]
[abort, T ]](https://image.slidesharecdn.com/20180320biologicaldatabasespart3-180321074857/85/2018-03-20_biological_databases_part3-80-320.jpg)

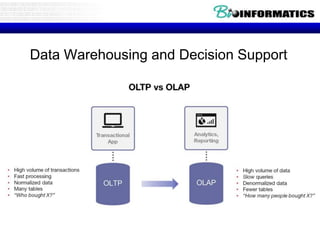


![View Materialization (Precomputation)
• Suppose we precompute RegionalSales and store
it with a clustered B+ tree index on
[category,state,sales].
– Then, previous query can be answered by an index-
only scan.
SELECT R.state, SUM(R.sales)
FROM RegionalSales R
WHERE R.category=“Laptop”
GROUP BY R.state
SELECT R.state, SUM(R.sales)
FROM RegionalSales R
WHERE R. state=“Wisconsin”
GROUP BY R.category
Index on precomputed view
is great!
Index is less useful (must
scan entire leaf level).](https://image.slidesharecdn.com/20180320biologicaldatabasespart3-180321074857/85/2018-03-20_biological_databases_part3-85-320.jpg)



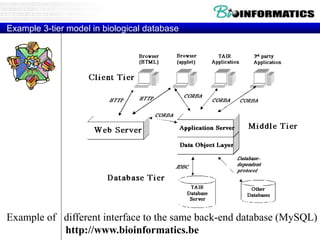
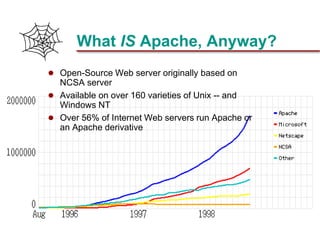
This document discusses biological databases and PHP. It begins with an overview of biological databases and examples using BIOSQL to load genetic data from GenBank into a MySQL database. It then provides examples of building a basic 3-tier model with Apache, PHP, and a MySQL backend database. The document also includes a brief introduction to PHP, covering its history, why it is commonly used, and basic syntax like conditional statements.




























































![Bio ontologies and semantic technologies[2]](https://cdn.slidesharecdn.com/ss_thumbnails/bioontologiesandsemantictechnologies2-180509123734-thumbnail.jpg?width=640&height=640&fit=bounds)


























