Downloaded 48 times


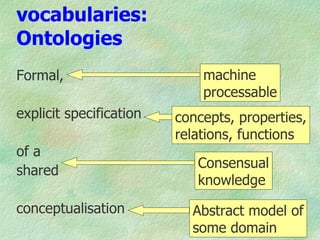

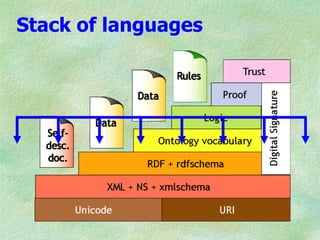

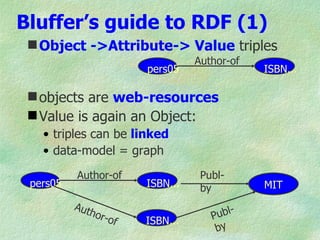

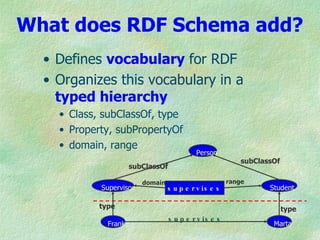





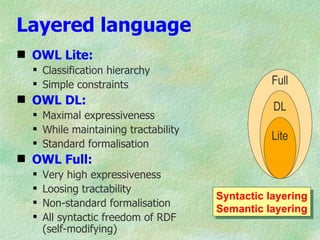
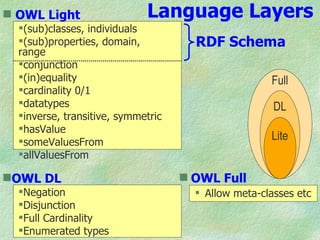














The document outlines the structure and function of ontologies, particularly in relation to the Web Ontology Language (OWL) and Resource Description Framework (RDF). It discusses components of ontologies such as classes, properties, and relationships, as well as the goals and requirements for using OWL in various applications. Additionally, it delineates the different layers of OWL languages and their expressiveness, alongside their limitations and use cases.






















































































