

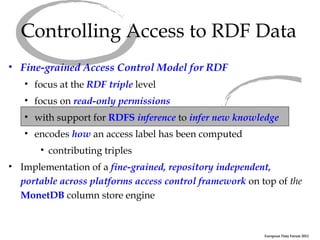




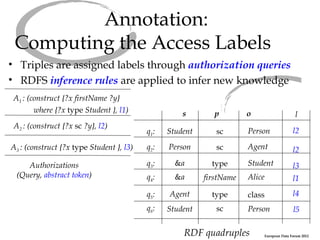


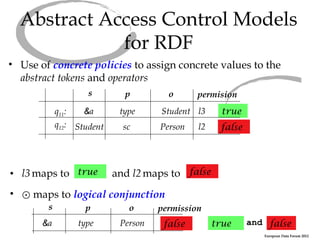




The document discusses an abstract access control model for dynamic RDF datasets, focusing on fine-grained access control at the triple level, especially for sensitive information. It emphasizes the importance of RDFS inference in managing access labels and the challenges associated with frequent updates, while proposing a framework that allows experimentation with different concrete policies. The conclusion highlights ongoing work towards a robust implementation of the model using the MonetDB column store engine.




















































































