(i) Page size = 2^9 = 512 words
(ii) Maximum segment size = 2^11 * 512 = 64K words
(iii) Maximum number of pages = 2^9 = 512 pages per segment
(iv) Maximum number of segments = 2^11 = 2048 segments
CONSIDERATION PAG. SEG.
Needthe programmer be aware that this technique
is being used?
No Yes
How many linear address spaces are there? 1 Many
Can the total address space exceed the size of
physical memory?
Yes Yes
Can procedures and data be distinguished and
separately protected?
No Yes
Can tables whose size fluctuates be accommodated
easily?
No Yes
Is sharing of procedures between users facilitated? No Yes
7.
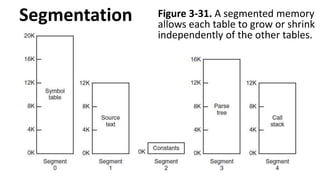
Segmentation
Why was paginginvented?
• To get a large linear address space without
having to buy more physical memory.
Why was segmentation invented?
• To allow programs and data to be broken up
into logically independent address spaces and
to aid sharing and protection.
8.
Segmentation
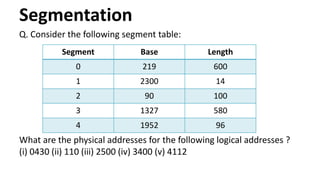
Q. Consider thefollowing segment table:
What are the physical addresses for the following logical addresses ?
(i) 0430 (ii) 110 (iii) 2500 (iv) 3400 (v) 4112
Segment Base Length
0 219 600
1 2300 14
2 90 100
3 1327 580
4 1952 96
9.
Segmentation
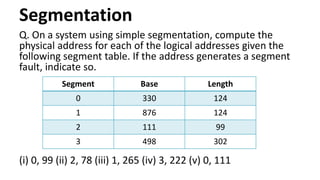
Q. On asystem using simple segmentation, compute the
physical address for each of the logical addresses given the
following segment table. If the address generates a segment
fault, indicate so.
(i) 0, 99 (ii) 2, 78 (iii) 1, 265 (iv) 3, 222 (v) 0, 111
Segment Base Length
0 330 124
1 876 124
2 111 99
3 498 302
10.
Figure 3-33. (a)-(d)Development of checkerboarding. (e) Removal of the
checkerboarding by compaction.
11.
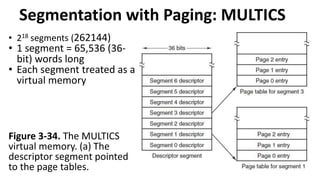
Figure 3-34. TheMULTICS
virtual memory. (a) The
descriptor segment pointed
to the page tables.
Segmentation with Paging: MULTICS
• 218 segments (262144)
• 1 segment = 65,536 (36-
bit) words long
• Each segment treated as a
virtual memory
12.
Figure 3-34. TheMULTICS virtual memory. (b) A segment descriptor.
The numbers are the field lengths.
Segmentation with Paging: MULTICS
13.
Figure 3-35. A34-bit MULTICS virtual address.
Segmentation with Paging: MULTICS
When memory reference occurs, following algorithm is carried out (Figure 3-36).
1. The segment number was used to find the segment descriptor.
2. A check was made to see if the segment’s page table was in memory. If it
was, it was located. If it was not, a segment fault occurred. If there was a
protection violation, a fault (trap) occurred.
14.
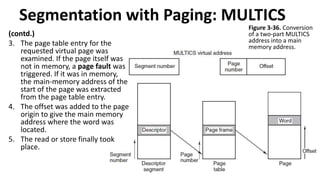
Segmentation with Paging:MULTICS
(contd.)
3. The page table entry for the
requested virtual page was
examined. If the page itself was
not in memory, a page fault was
triggered. If it was in memory,
the main-memory address of the
start of the page was extracted
from the page table entry.
4. The offset was added to the page
origin to give the main memory
address where the word was
located.
5. The read or store finally took
place.
Figure 3-36. Conversion
of a two-part MULTICS
address into a main
memory address.
15.
Figure 3-37. Asimplified
version of the MULTICS
TLB (16-word high speed).
The existence of two page
sizes made the actual TLB
more complicated.
Segmentation with Paging: MULTICS
16.
Segmentation with Paging:MULTICS
Q. In a paged-segmented system, a virtual address
consists of 32 bits of which 12 bits are
displacement, 11 bits are segment number and
9 bits are page number. Calculate the following:
(i) Page size
(ii) Maximum segment size
(iii) Maximum number of pages
(iv) Maximum number of segments