Downloaded 12 times






















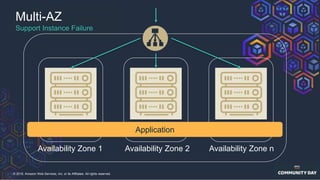
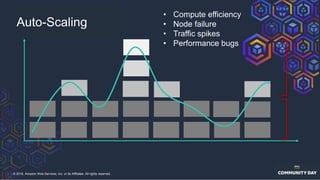



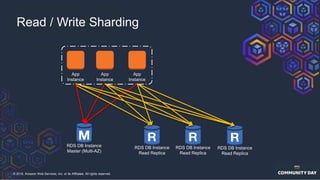
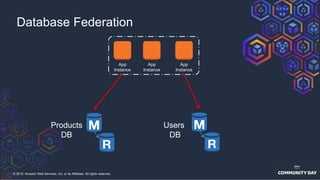
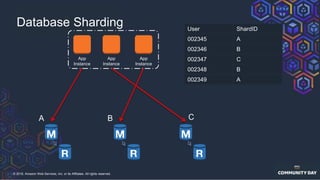
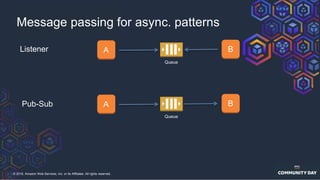
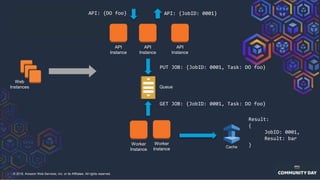
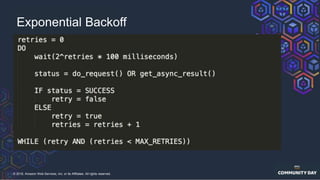
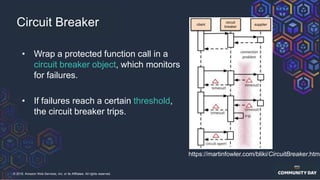
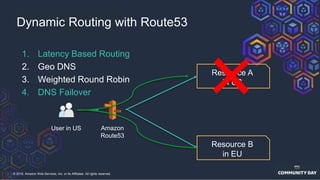
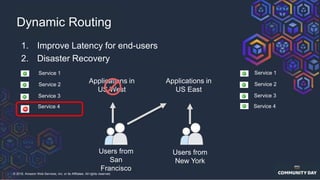

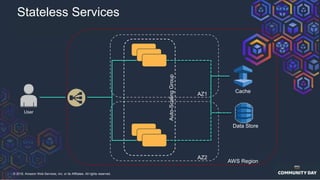

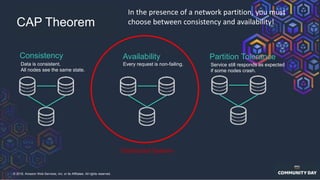




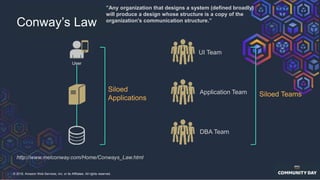
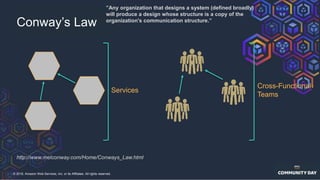












The document discusses chaos engineering, which is an experimental approach to improving system reliability by intentionally breaking components to identify and address weaknesses before actual failures occur. It emphasizes the importance of cultural change within organizations to effectively implement chaos engineering practices and includes various methodologies and resources for executing such experiments. Additionally, it covers various technical strategies and concepts related to system resilience, availability, and testing in distributed systems.



































































