Download to read offline





![Declaring Priorities
Pag
e 9
Four priority levels: Critical, High, Medium, Low
Higher priority queries get served first within the
same resource sharing group
System level default priority:
SET SYSTEM DEFAULT [DEFPRIORITY | MAXPRIORITY ]
TO [CRITICAL | HIGH | NORMAL | LOW | NONE]
Set default priority per permission group:
CREATE GROUP <group name> WITH DEFPRIORITY <prio>;
Change default priority of specific user:
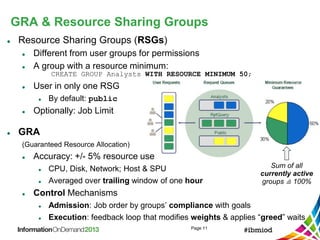
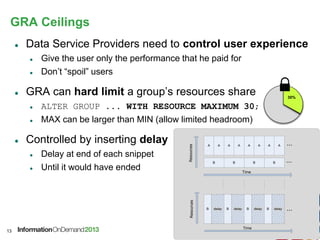
ALTER USER <user> WITH DEFPRIORITY LOW MAXPRIORITY HIGH;
Changing priority of existing session:
nzsession priority -high –u <user> -pw <pw> -id <session ID>, or
ALTER SESSION [<session ID>] SET PRIORITY TO <prio>;](https://image.slidesharecdn.com/iod20132839boomansteinbach-161204120119/85/IBM-Information-on-Demand-2013-Session-2839-Using-IBM-PureData-System-for-Analytics-Workload-Management-9-320.jpg)




















The document discusses workload management (WLM) principles and best practices for using IBM's PureData System for Analytics. It covers challenges such as concurrent workloads, resource allocation, and performance objectives while providing usage scenarios and guidelines for achieving optimal system performance. Key features include priority control, resource sharing groups, and managing user experience in a data service provider context.




















![[DSBW Spring 2009] Unit 05: Web Architectures](https://cdn.slidesharecdn.com/ss_thumbnails/unit05-architecture-090328141542-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




















































































