Downloaded 38 times
















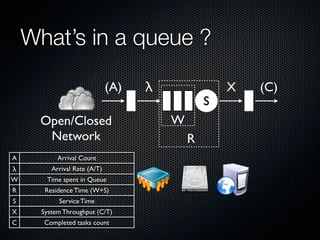




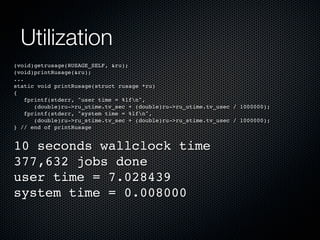





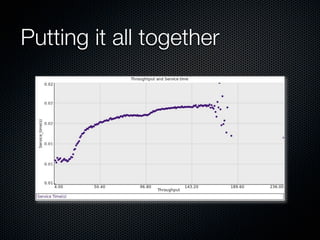
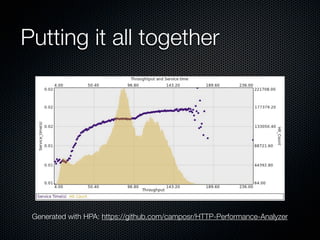




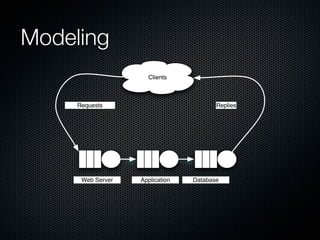
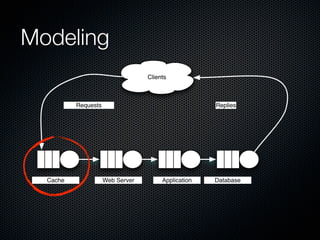


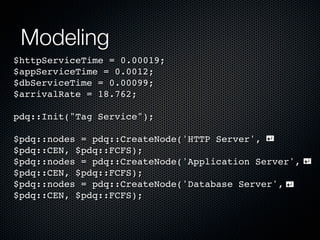
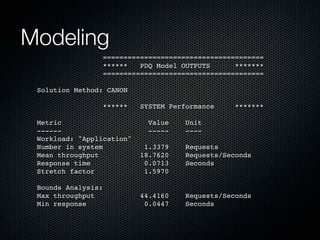
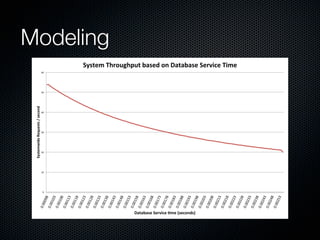


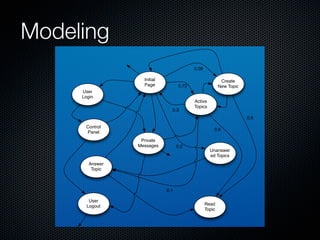




Rodrigo Campos presented on Linux systems capacity planning. He discussed performance monitoring tools like Sysstat and common metrics like CPU usage. He explained concepts from queueing theory like utilization, Little's Law, and using modeling tools like PDQ to create what-if scenarios of system performance. Campos provided an example of modeling a web application using a customer behavior model to understand and optimize performance bottlenecks.




















































































