Download as PDF, PPTX






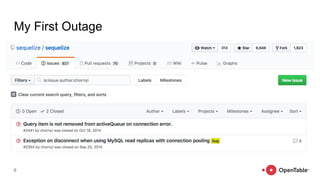














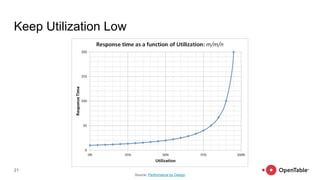












The document discusses reliability and resilience patterns in software engineering, highlighting common causes of service outages and lessons learned from incidents. It emphasizes designing systems to anticipate and recover from failures rather than merely eliminating them, and outlines strategies such as bulkheads, timeouts, load shedding, and graceful degradation. Additionally, it touches upon the importance of organizational culture in fostering innovation and adaptation in complex systems.





























































