Downloaded 62 times


















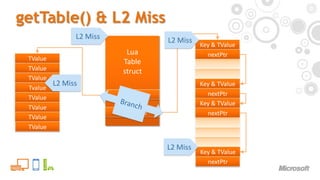













Optimizing Lua for consoles is challenging due to performance penalties from console CPU architectures. Lua performance suffers from load-hit-store issues in data handling, numerous L2 cache misses when accessing tables and during garbage collection, and high branch misprediction penalties in the virtual machine main loop due to unpredictable opcode values. The document outlines approaches to address these issues, such as compacting hash tables to reduce cache misses, custom block allocation to optimize garbage collection, and removing branches in the virtual machine loop. Overall, the document emphasizes that L2 cache misses in particular can drastically impact performance on console hardware.

















































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)
















