Download as PDF, PPTX















![Query Hint By Sybase: Example
Some of the hint used by Sybase in query are:
1. set forceplan [on|off] Hint to optimizer to choose the same join
ordering as the table names are given in FROM clause, if it is on.
2. We can specify the index to use for a query using the (index
index_name) clause in select, update, and delete statements](https://image.slidesharecdn.com/optimizerhint-150708080638-lva1-app6891/85/Optimizer-Hints-17-320.jpg)
![Query Hint By MySQL: Example
Some of the hint used by MySQL in query are:
1. /*! STRAIGHT_JOIN */ This hint tells optimizer to join the tables in the
order that they are specified in the FROM clause. (MySQL hint is similar
to oracle except it uses ‘!’ instead of ‘+’.
2. USE {INDEX|KEY} (index_list)] Provide hints to give the optimizer
information about how to choose indexes during query processing](https://image.slidesharecdn.com/optimizerhint-150708080638-lva1-app6891/85/Optimizer-Hints-18-320.jpg)












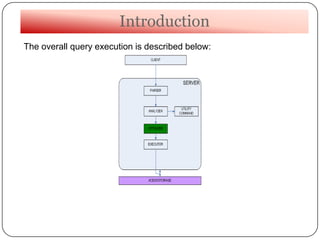
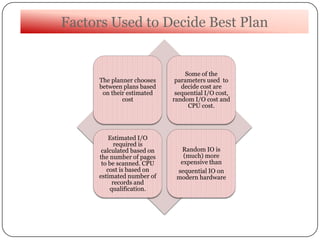
This document summarizes a talk on optimizer hints in databases. It begins with introducing the speaker and their background. It then covers the basics of query optimization in databases and how hints can provide additional information to the optimizer. Specifically, it discusses query hints to force a plan, statistics hints to provide join selectivity, and data hints about column dependencies. It notes that PostgreSQL does not support hints directly but similar control is possible through configuration parameters. It concludes by listing some drawbacks of hints.























































![Introduction to MySQL Query Tuning for Dev[Op]s](https://cdn.slidesharecdn.com/ss_thumbnails/qtdevops-191005204425-thumbnail.jpg?width=640&height=640&fit=bounds)


















































