Download as PDF, PPTX











![>>> clf.set_params(svm__C=10)
Pipeline(steps=[('reduce_dim', PCA(copy=True, n_components=None, whiten=False)),
('svm', SVC(C=10, cache_size=200, class_weight=None,
coef0=0.0, degree=3, gamma=0.0, kernel='rbf', max_iter=-1,
probability=False, random_state=None, shrinking=True, tol=0.001,
verbose=False))])
>>> from sklearn.grid_search import GridSearchCV
>>> params = dict(reduce_dim__n_components=[2, 5, 10],
... svm__C=[0.1, 10, 100])
>>> grid_search = GridSearchCV(clf, param_grid=params)](https://image.slidesharecdn.com/buildingmlpipelines-150624085901-lva1-app6891/85/Building-Machine-Learning-Pipelines-15-320.jpg)







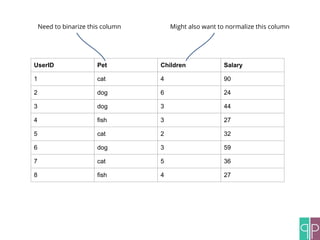
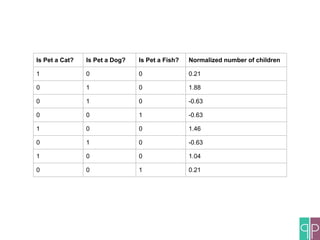

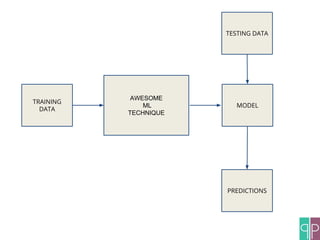
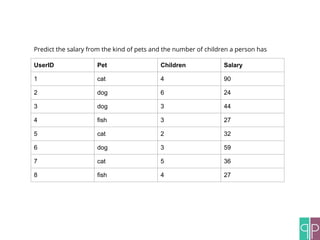
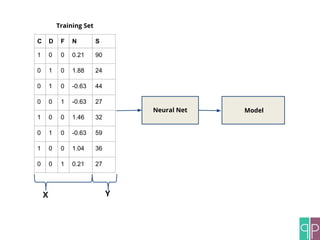
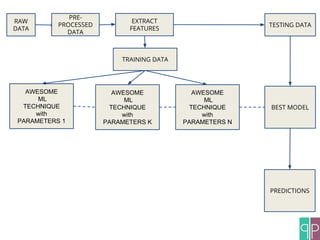
The document discusses the construction of machine learning (ML) pipelines, detailing steps such as data normalization, noise removal, and feature extraction before training models. It emphasizes the importance of cross-validation and hyper-parameter optimization to ensure the effectiveness of the models used. Additionally, it highlights customizable metrics and configurable data sources that enhance ML pipeline performance.




























































































