Downloaded 15 times





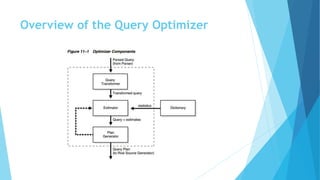











































This document provides an overview of query optimization and execution plan generation in Oracle Database. It discusses key concepts like the query optimizer, access paths, cost-based optimization, and join ordering. The optimizer generates potential execution plans based on statistics and cost. It evaluates plans and chooses the lowest cost plan based on estimated I/O, CPU, and memory costs. Index scans, full table scans, and rowid scans are common access paths. The optimizer also performs transformations like subquery unnesting and view merging to improve performance.















































