














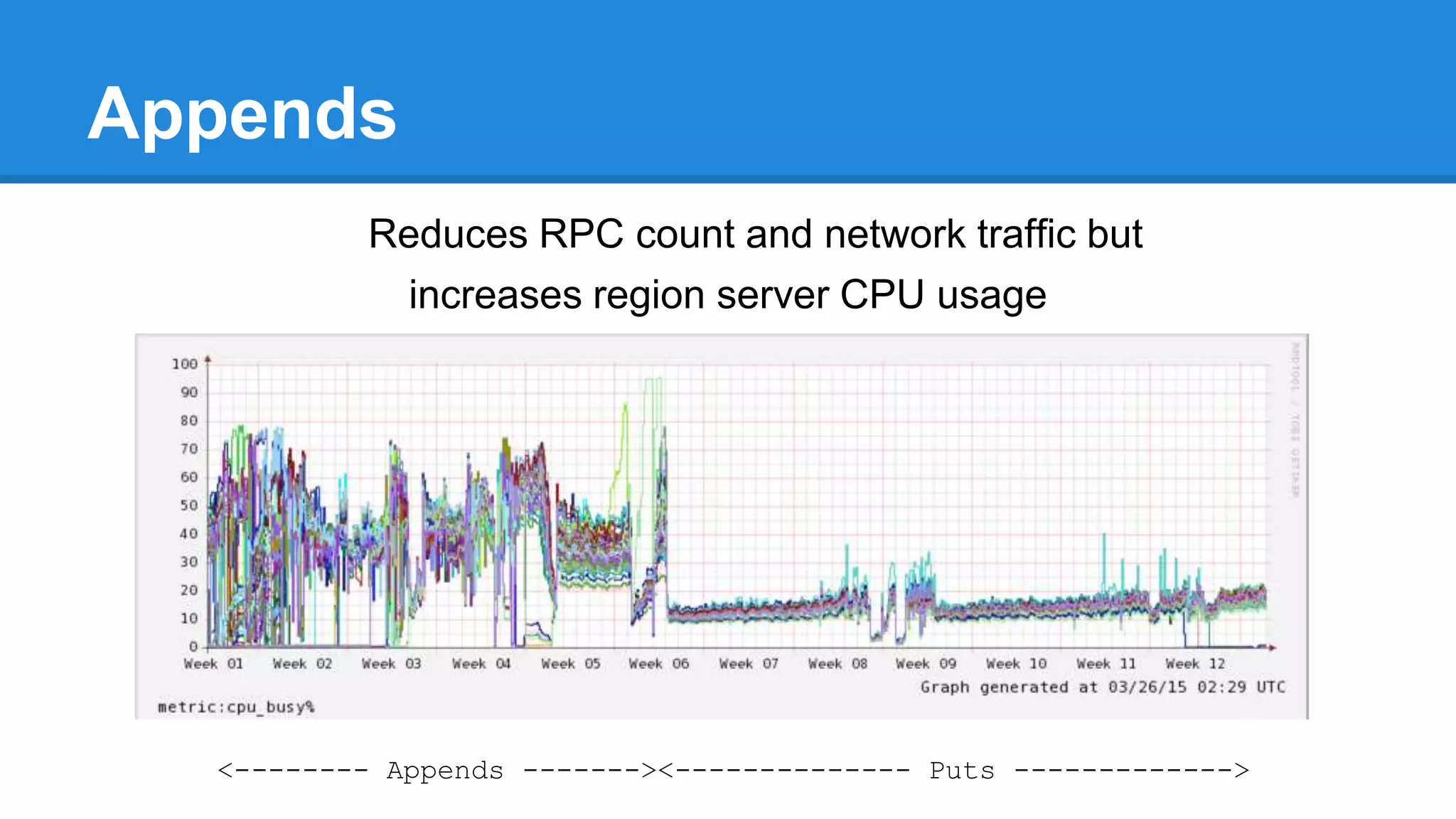
![Appends
● Qualifiers encode
○ offset from row base time
○ data type (float or integer)
○ value length (1 to 8 bytes)
● Timestamp = 4 bytes
● Row key >= 13 bytes to 55 bytes
● 1 serialized column >= 20 to 69 bytes
[ 0b00001111, 0b11000111 ]
<---------------->^<->
delta (seconds) type value length](https://image.slidesharecdn.com/operations-session3-150605170218-lva1-app6892/75/HBaseCon-2015-OpenTSDB-and-AsyncHBase-Update-20-2048.jpg)
![Appends
Compact it into one column!
● Concatenate qualifiers
● Concatenate values
● 1 row key, 1 timestamp
● 1 row from 69K to 14K, 83% savings
Qualifier: [ 0b00000000, 0b00000000, ... 0b00000000, 0b00010000 ]
Value: [ 0b00000001, ... 0b00000002 ]
Key: [ x00x00x00x01x49x95xFBx70x00x00x01x00x00x01 ]
Timestamp: [ x49x95xFBx70 ]](https://image.slidesharecdn.com/operations-session3-150605170218-lva1-app6892/75/HBaseCon-2015-OpenTSDB-and-AsyncHBase-Update-21-2048.jpg)

![Appends
Try HBase Appends
● Qualifier special prefix
● Concatenate offsets and values in value array
● Still one key, one timestamp, one column
Qualifier: [ 0b00000004 ]
Value: [ 0b00000000, 0b00000000, 0b00000001,
<-Offset/type/length-> <-value ->
...0b00000000, 0b00010000, 0b00000002 ]](https://image.slidesharecdn.com/operations-session3-150605170218-lva1-app6892/75/HBaseCon-2015-OpenTSDB-and-AsyncHBase-Update-23-2048.jpg)












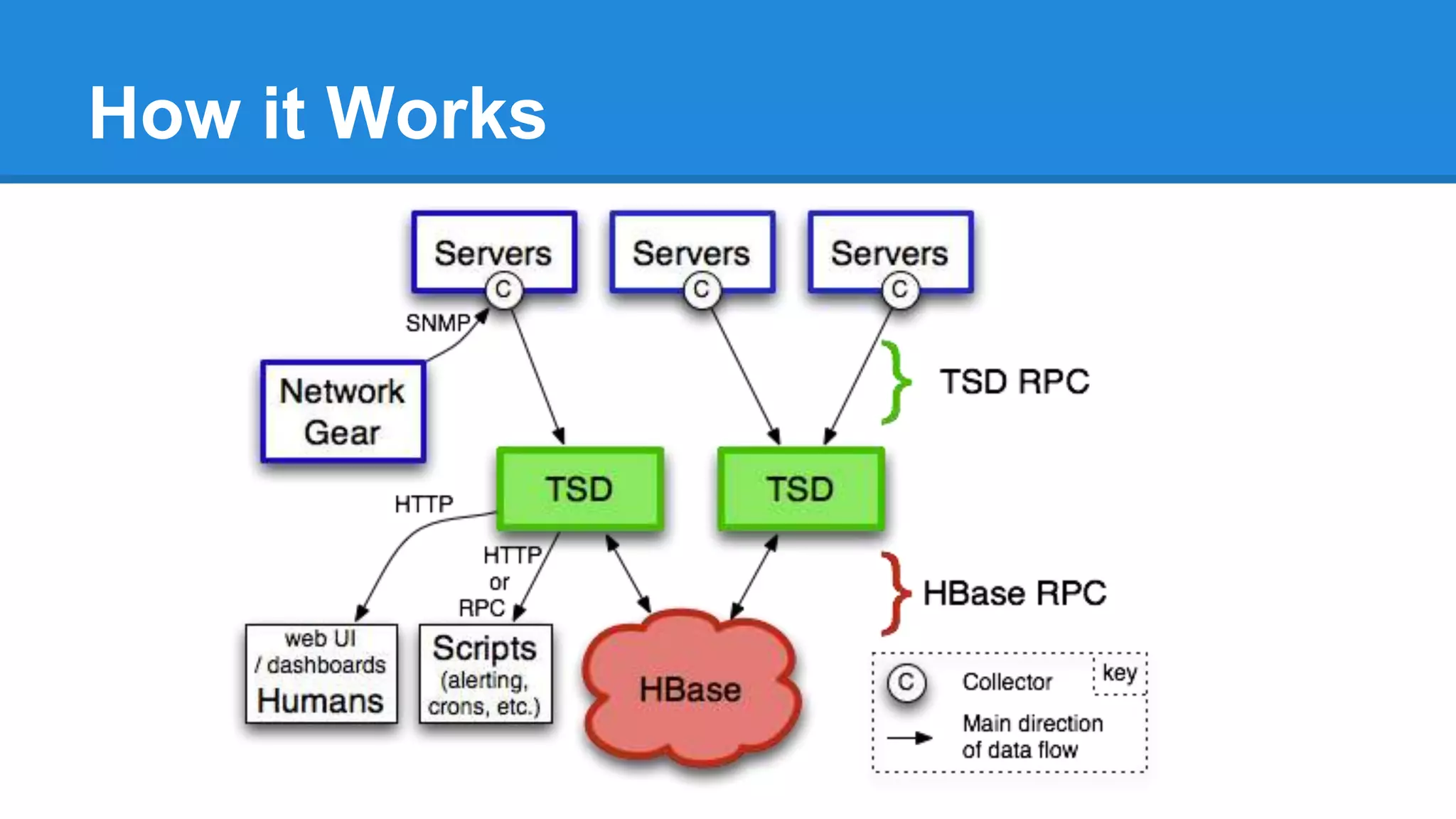
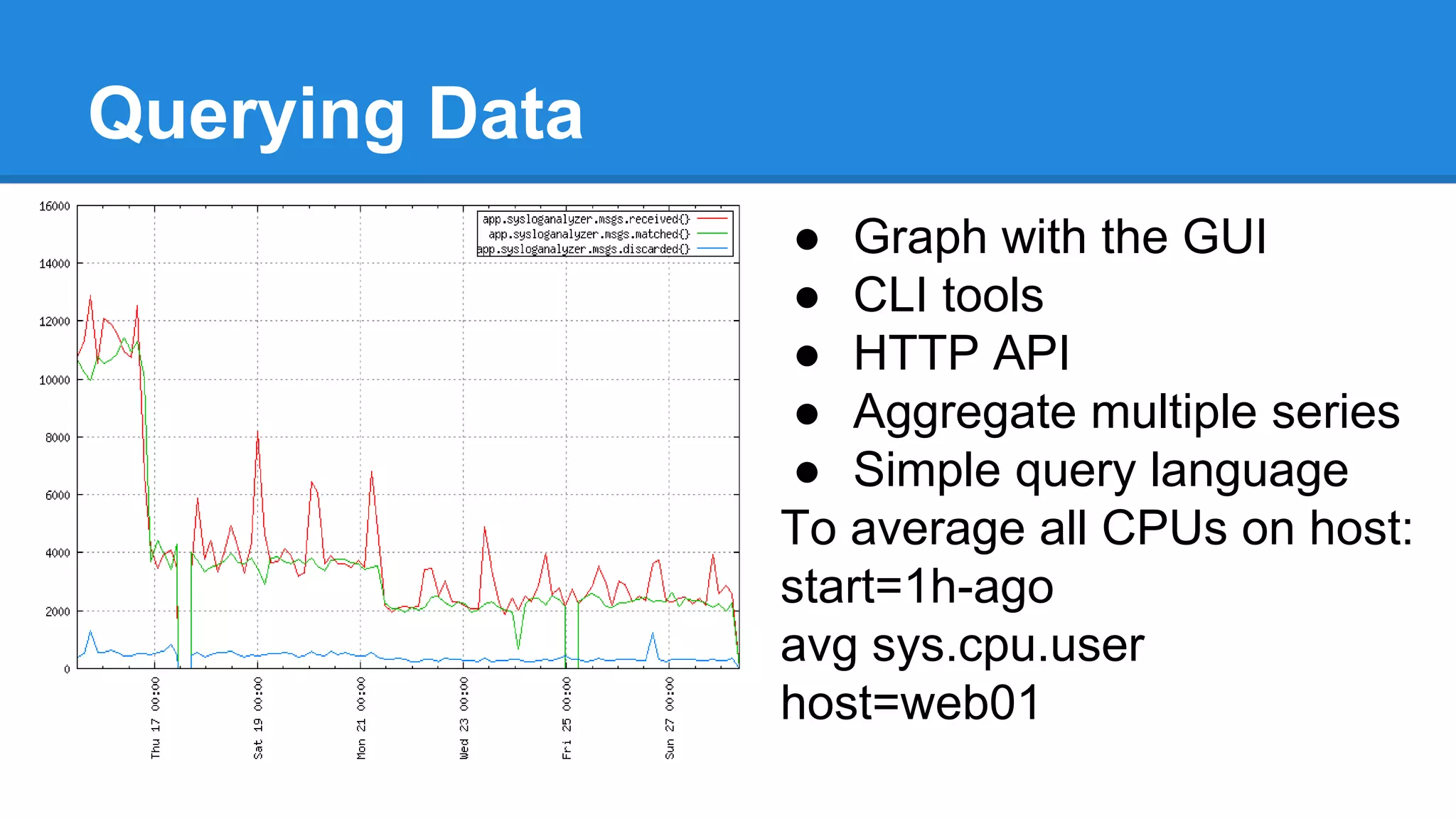
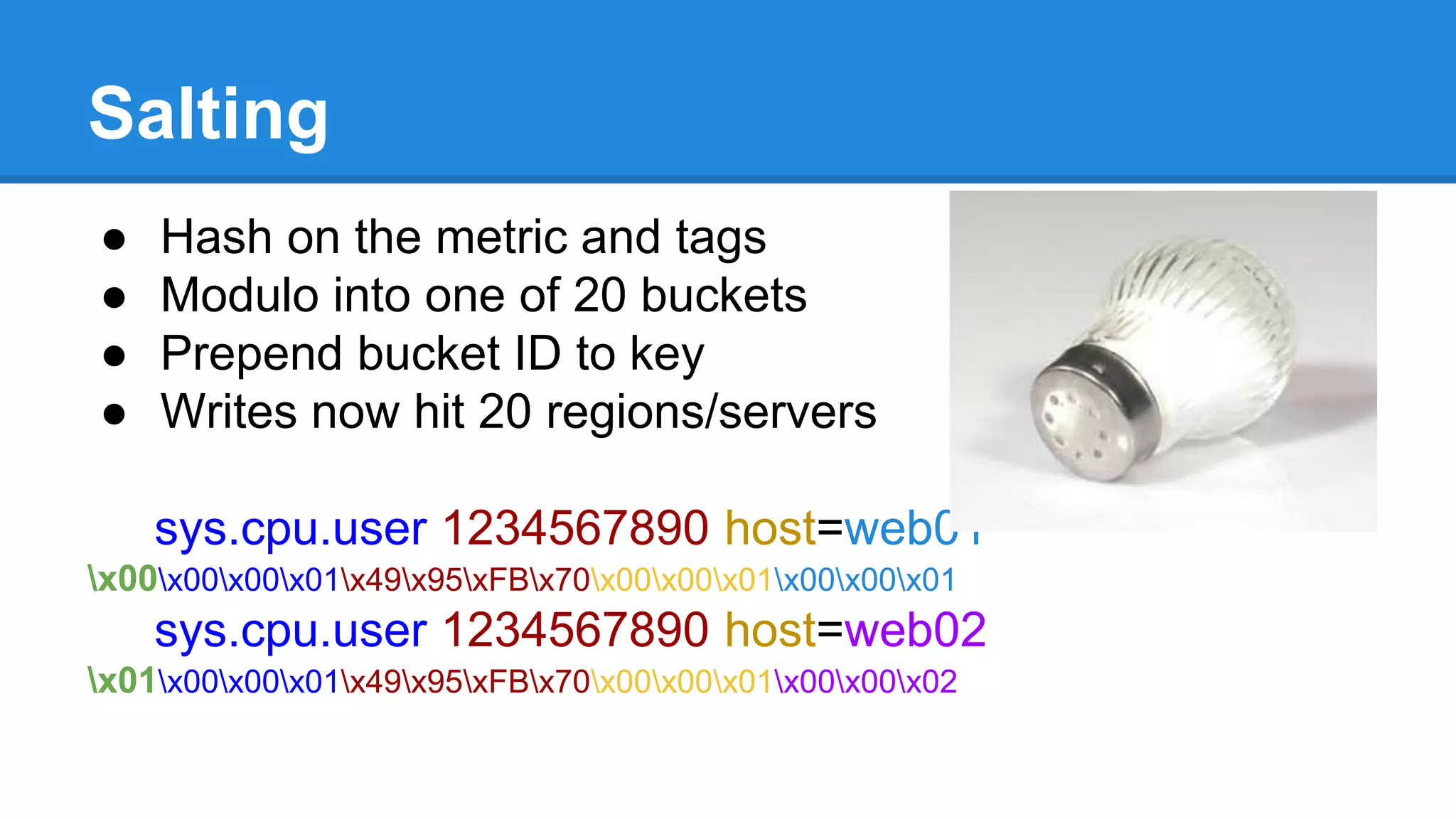
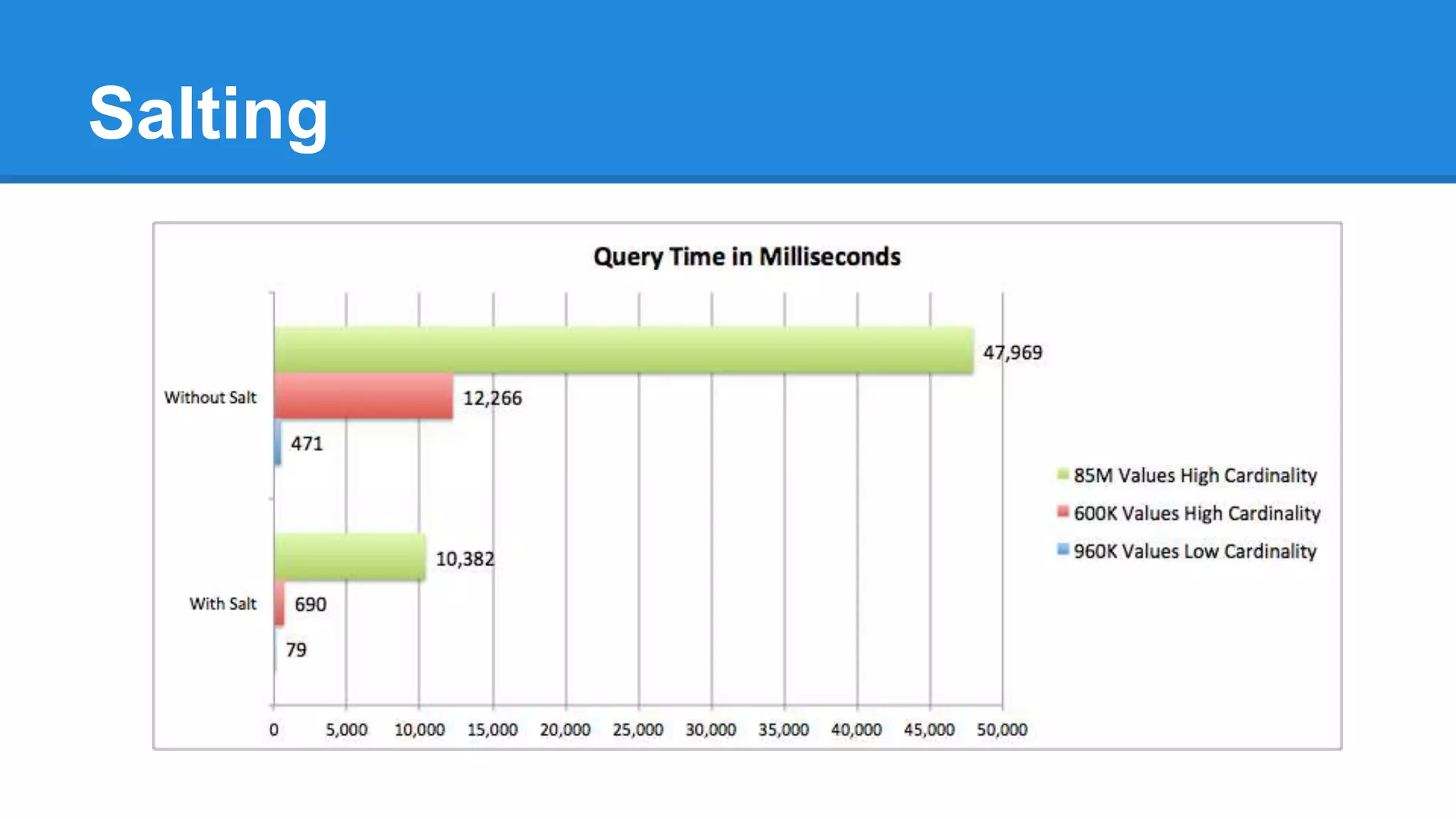
OpenTSDB is an open source distributed time series database for storing large amounts of metrics data and performing fast queries. It is scalable and can store trillions of data points across multiple servers. Data is stored in HBase and queries are performed using a simple query language. OpenTSDB 2.x includes new features like salting to distribute writes across servers, compact storage formats using column appends, and downsampling to fill in missing data during aggregation.














































![[FR] Timeseries appliqué aux couches de bébé](https://cdn.slidesharecdn.com/ss_thumbnails/breizhcamp-2016-160325163719-thumbnail.jpg?width=640&height=640&fit=bounds)


![Paul Dix [InfluxData] The Journey of InfluxDB | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/2022-11-02influxdays-journeyofinfluxdb-221020214252-ff7c76c5-thumbnail.jpg?width=640&height=640&fit=bounds)
























































