Downloaded 55 times




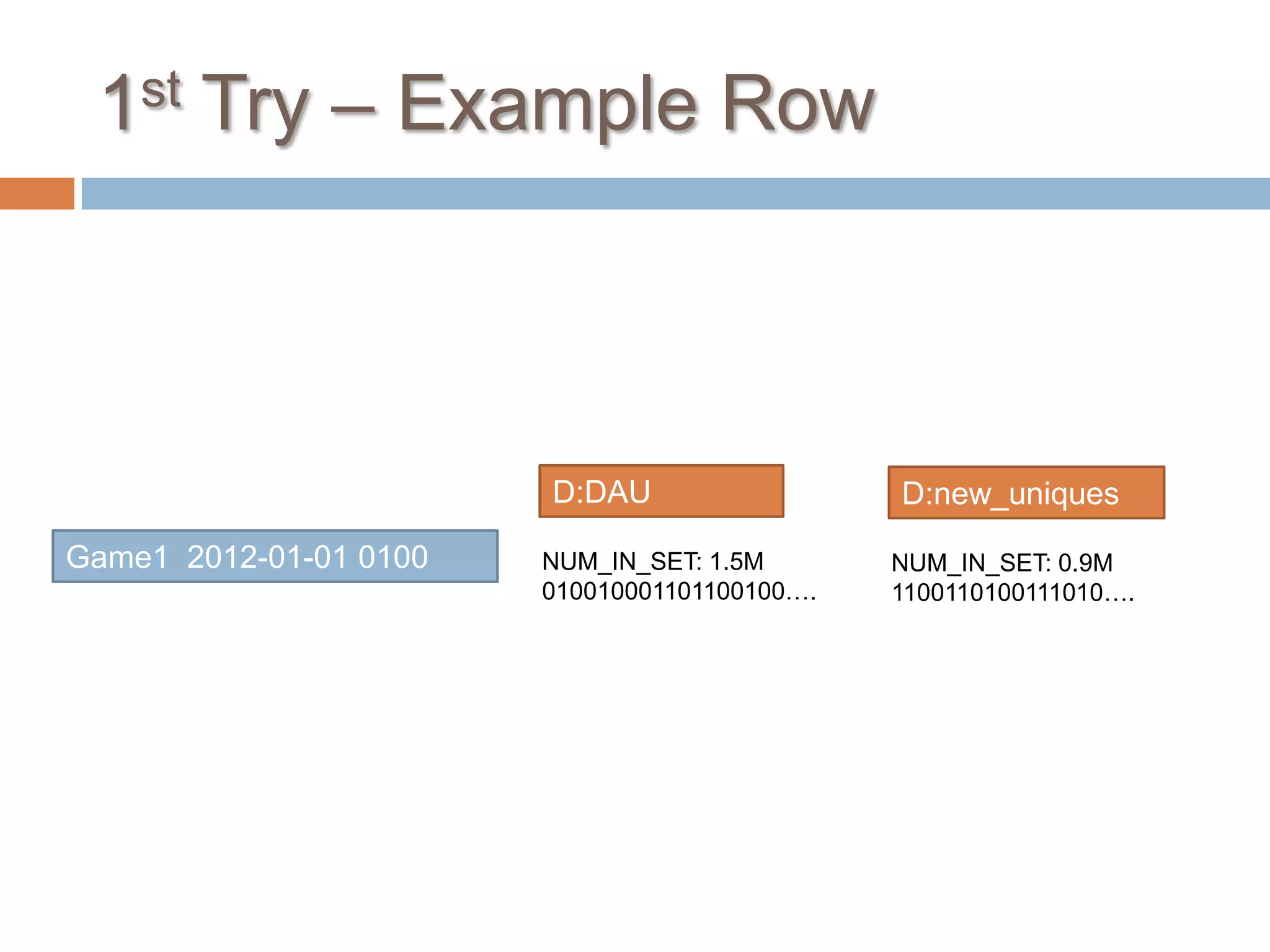





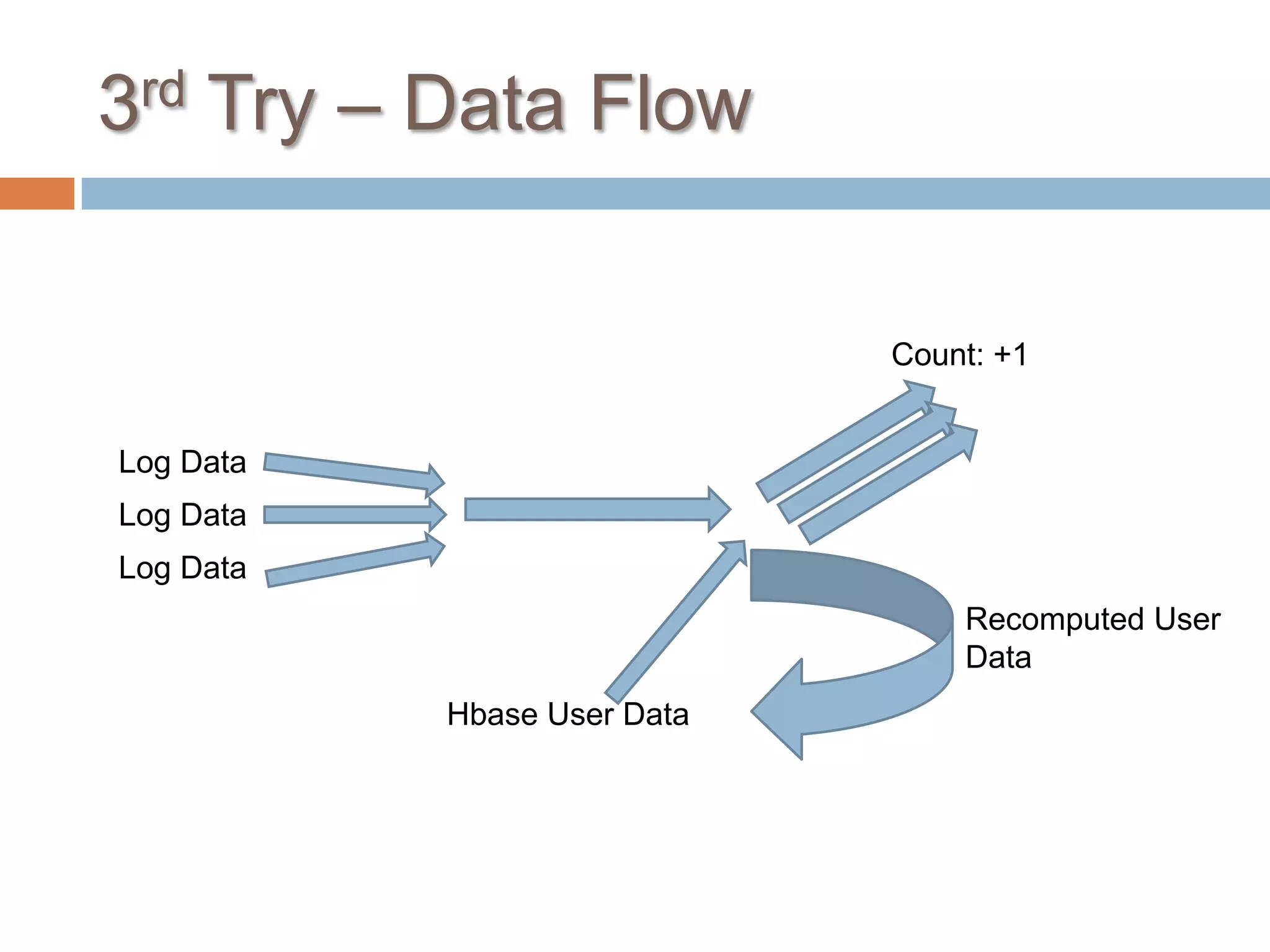




The document outlines various strategies for counting unique users in an HBase system, considering factors like data size, accuracy, and ease of debugging. Three approaches are discussed: the first attempts to utilize bit sets per hour for accuracy but struggles with scalability and debugging; the second involves individual user bit sets, improving debuggability but complicating data correction; the third groups log data by user ID and integrates historic data for holistic insights while requiring significant data management. Ultimately, the document emphasizes the importance of runtime optimization, data handling, and future flexibility in development.


















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















