Download as PDF, PPTX






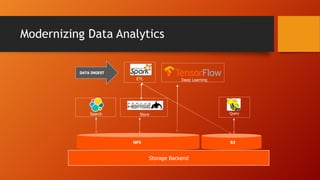
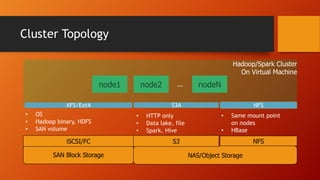







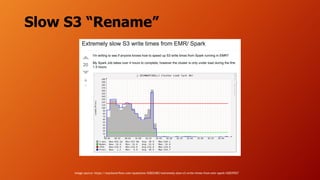




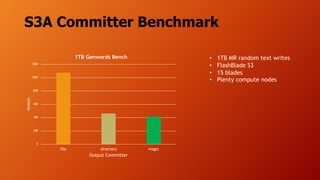
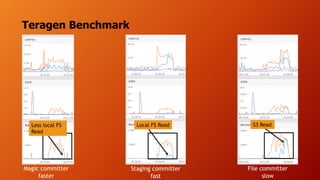










- The document discusses running Hive/Spark on S3 object storage using S3A committers and running HBase on NFS file storage instead of HDFS. This separates compute and storage and avoids HDFS operations and complexity. S3A committers allow fast, atomic writes to S3 without renaming files. Benchmark results show the magic committer is faster than the file committer for S3 writes. HBase performance tests show FlashBlade NFS providing low latency for random reads/writes compared to Amazon EFS.























































































