Download as PDF, PPTX







![16
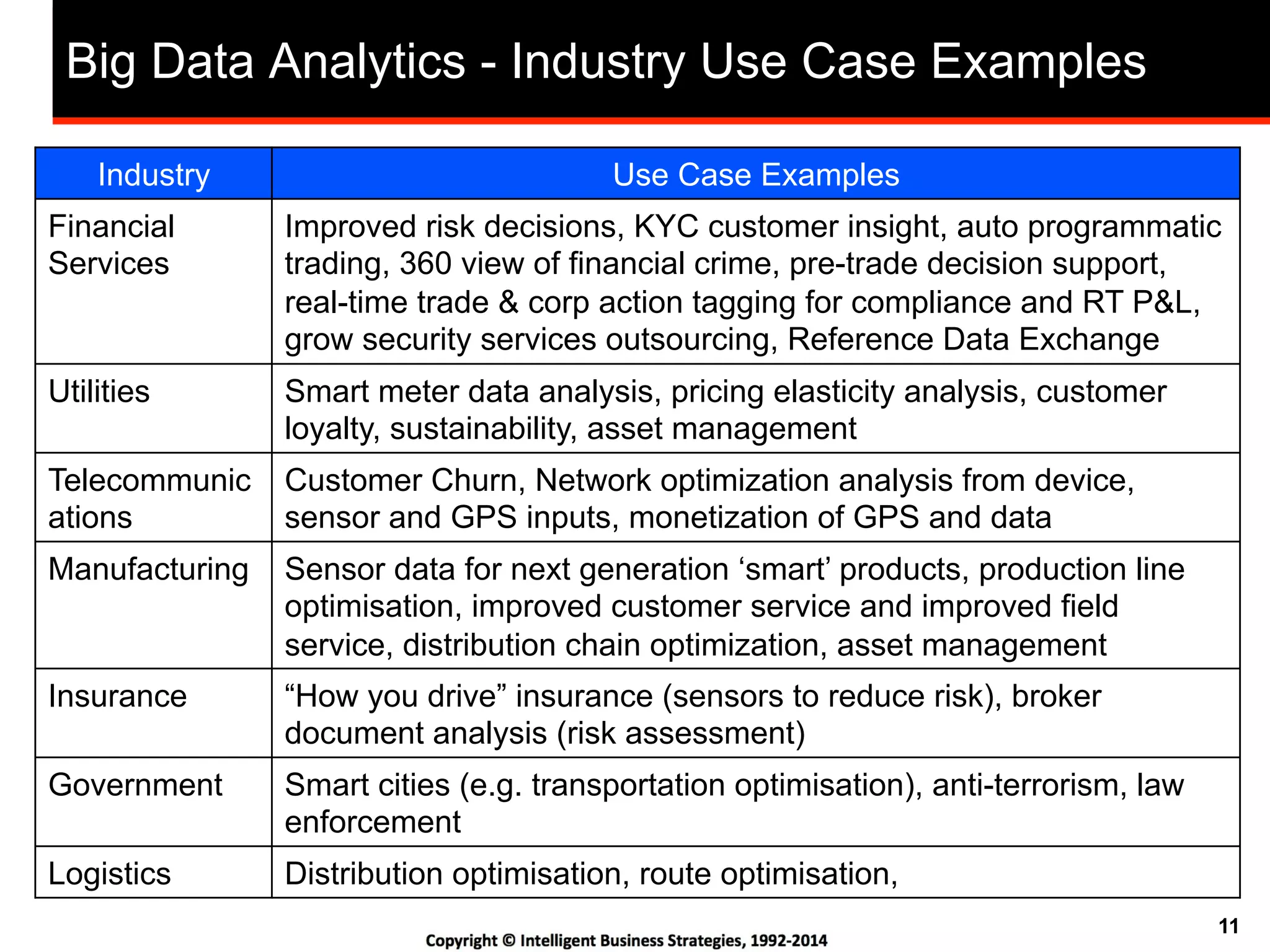
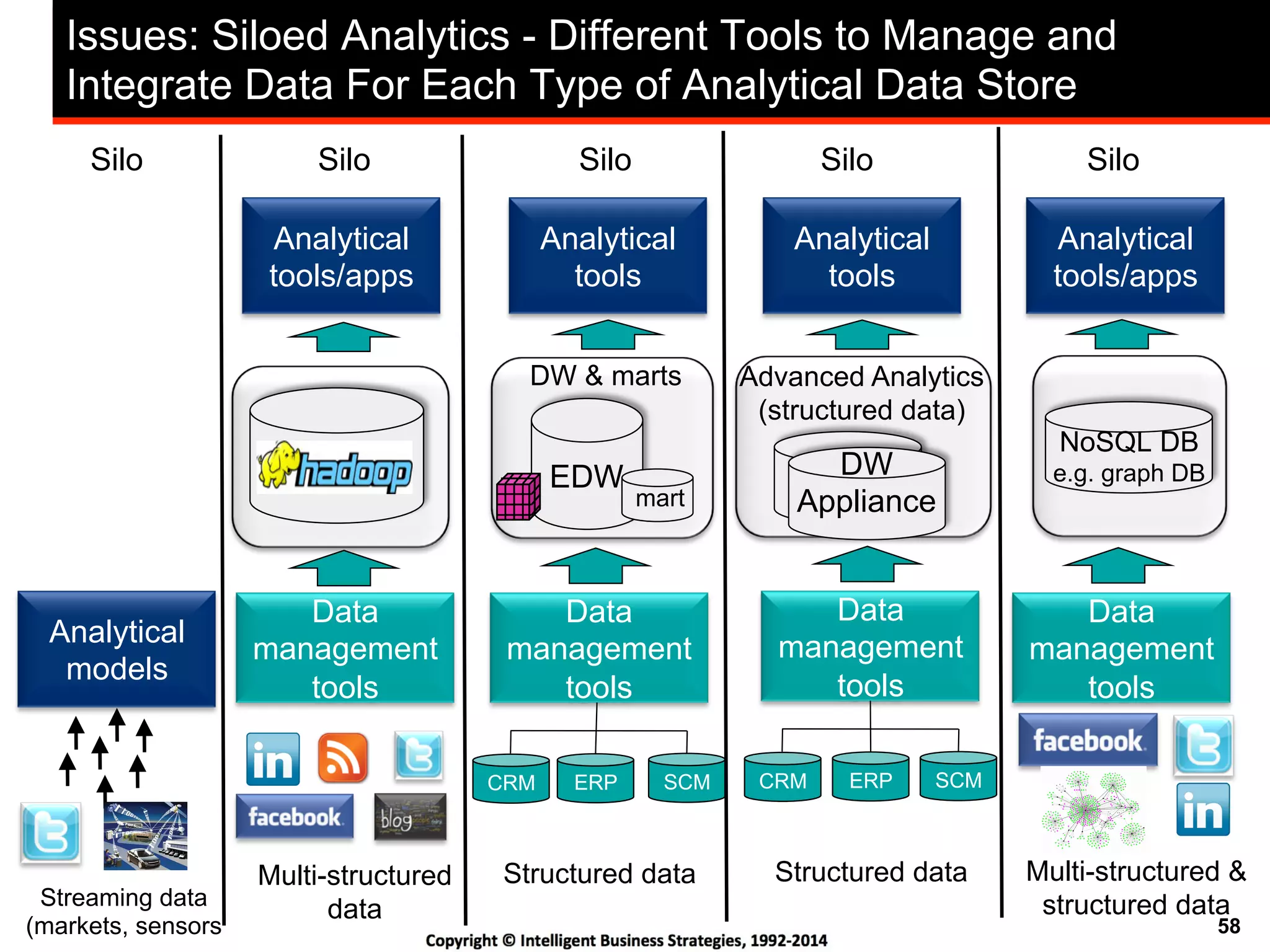
Big Data Analytics Challenges Include The Analysis of
Unstructured, Semi-structured and Structured Data
{ "firstName": ”Wayne",
"lastName": ”Rooney",
"age": 25,
"address": {
"streetAddress": "21 Sir Matt Busby Way",
"city": ”Manchester”,
“country”: “England”,
"postalCode": “M1 6DY”
},
"phoneNumbers": [
{ "type": "home”,
"number": ”0161-123-1234”
},
{
"type": ”mobile",
"number": ”07779-123234”
}
]
} JSON data
Text data
Image Data
Makes analysis more complex with new analytics and visualisations needed](https://image.slidesharecdn.com/maprentdatahubwebinar-june2014finalprotected-140618191903-phpapp01/75/MapR-Enterprise-Data-Hub-Webinar-w-Mike-Ferguson-16-2048.jpg)

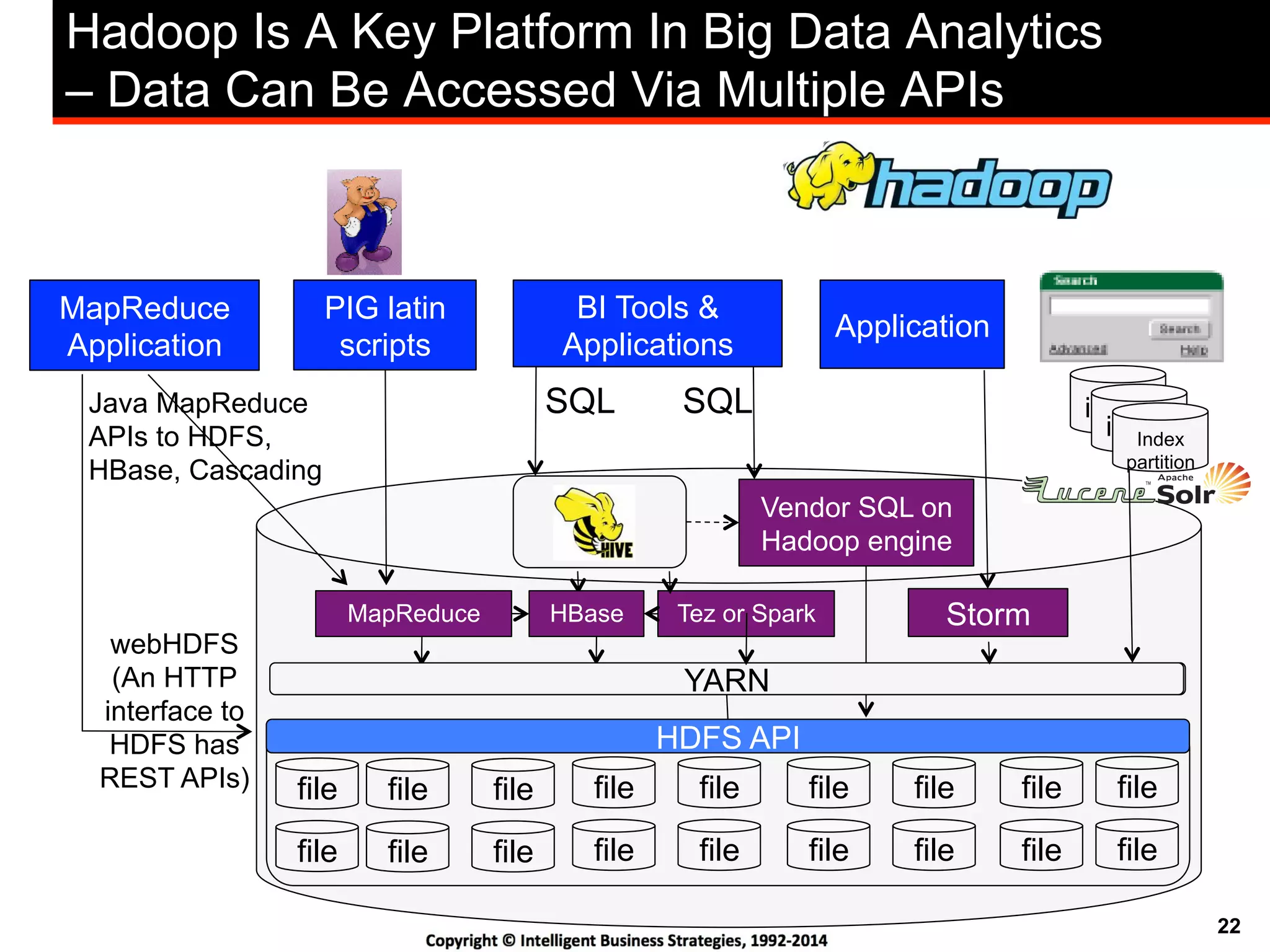
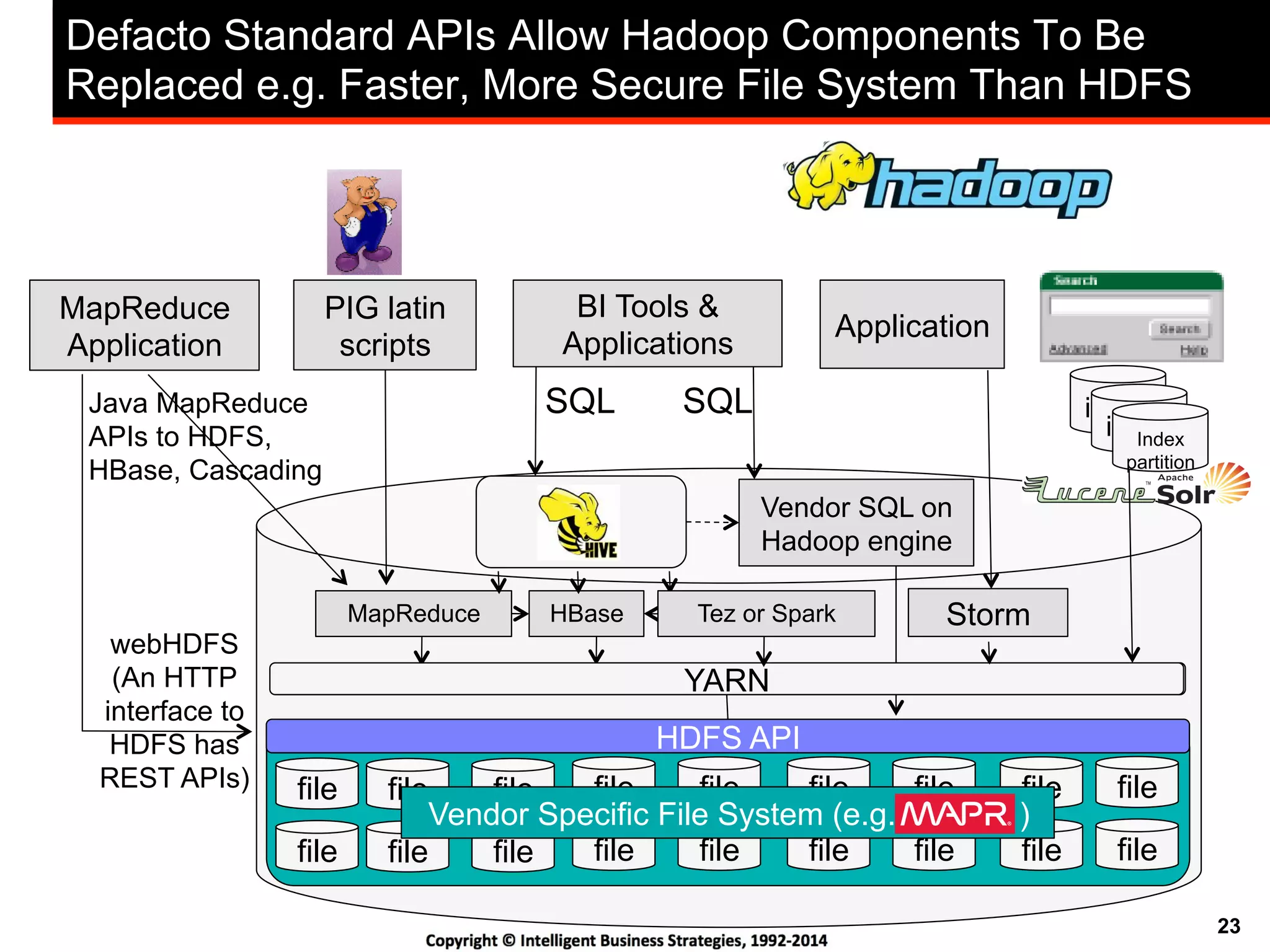

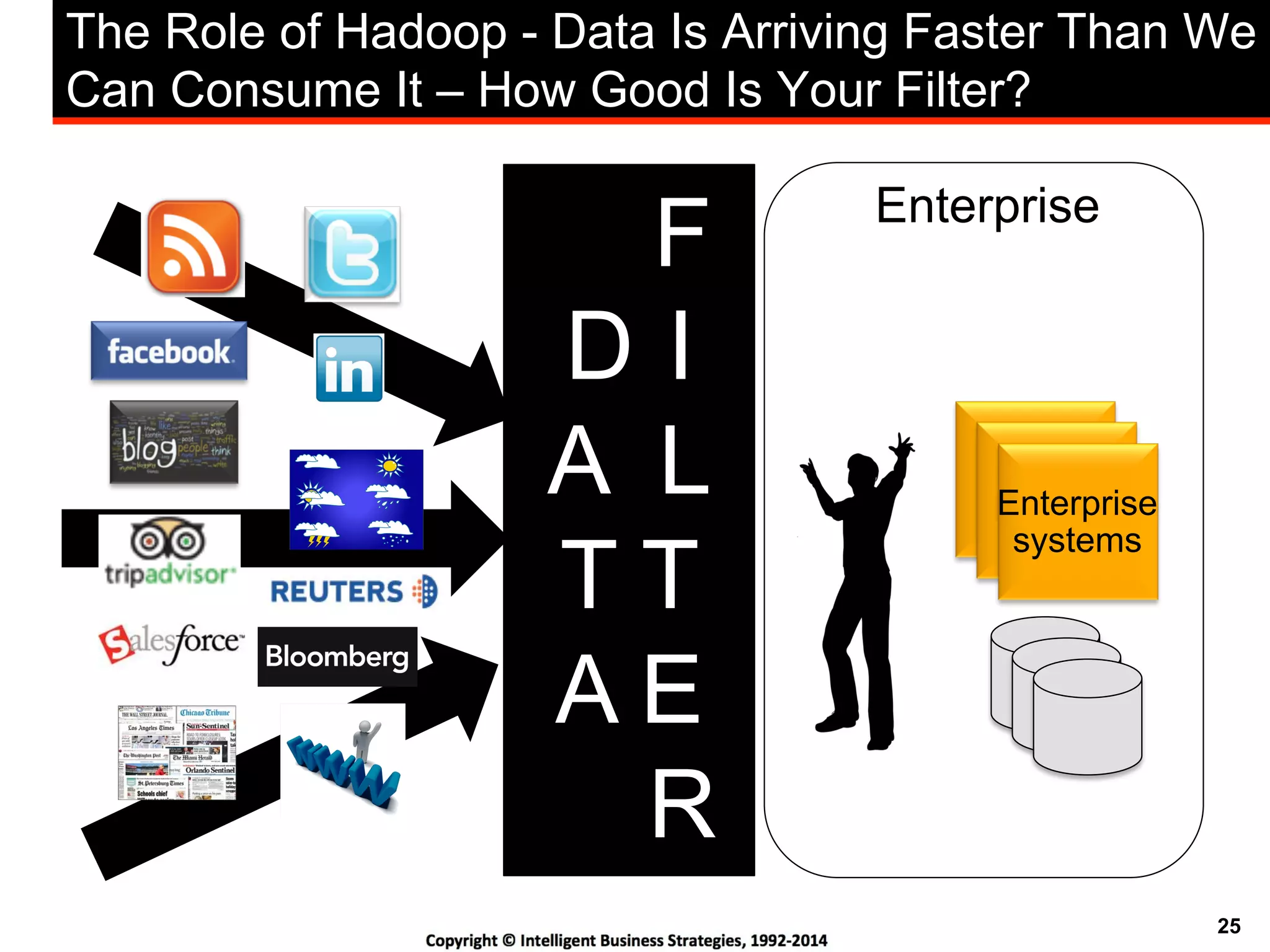
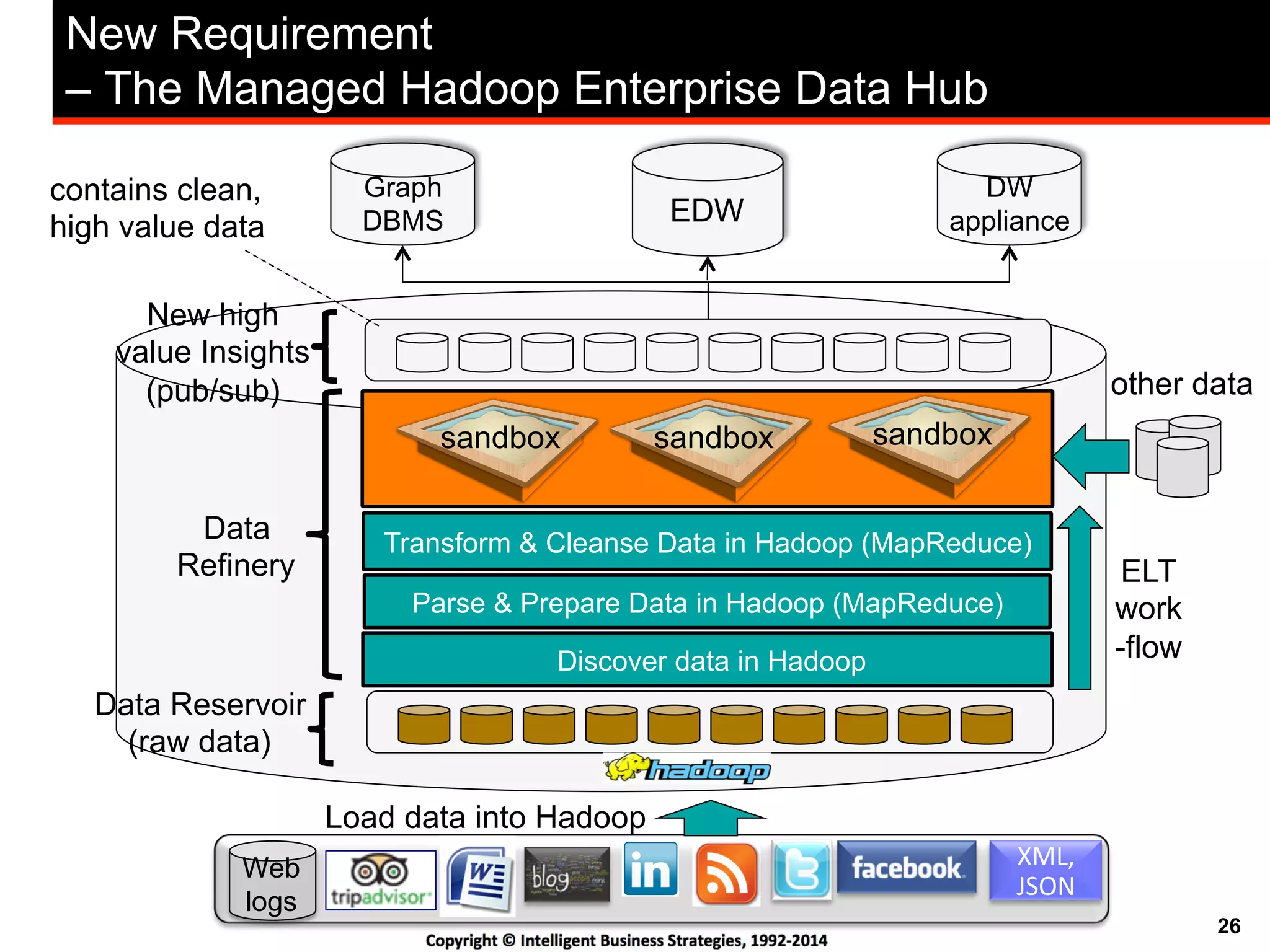

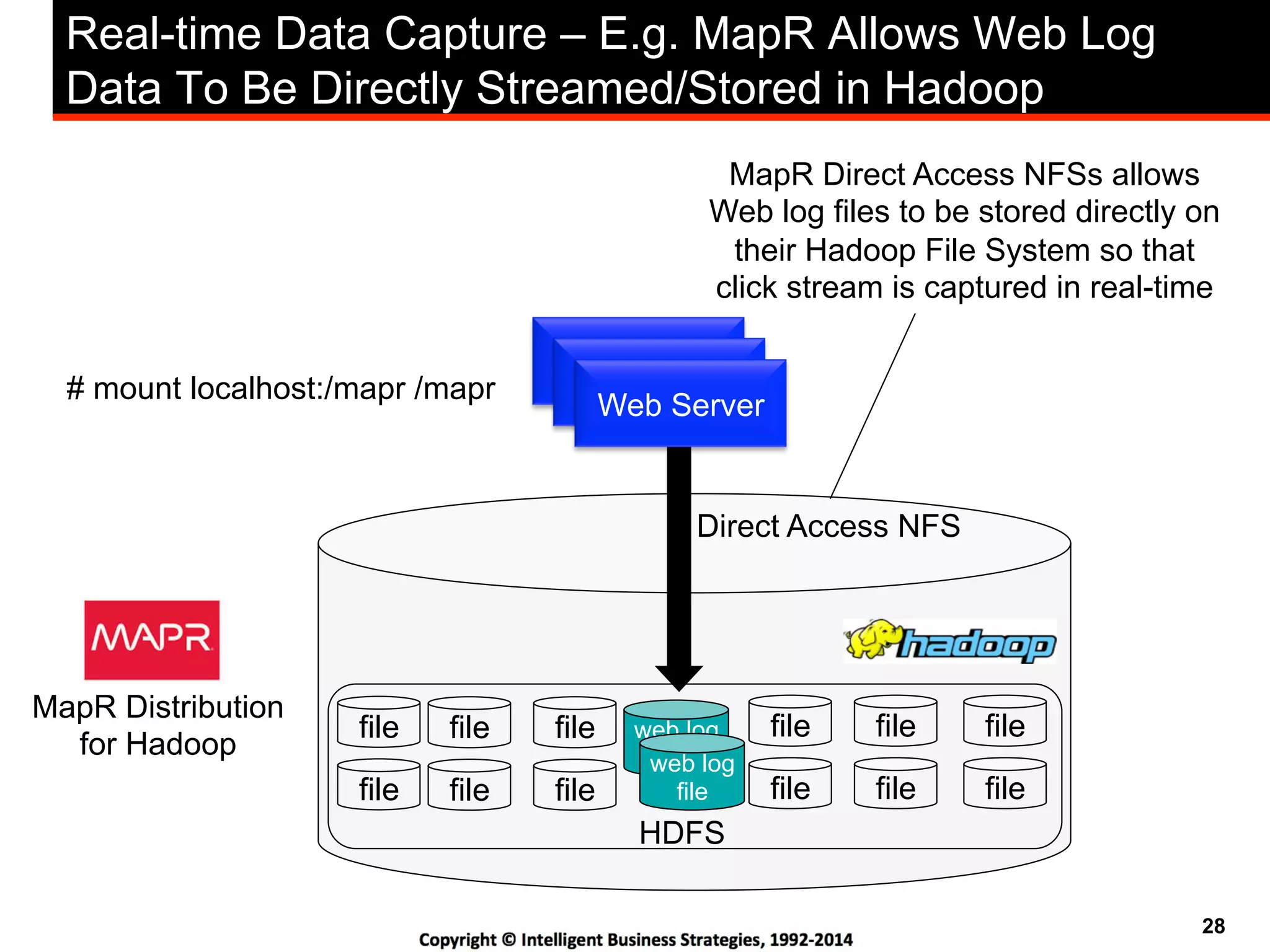

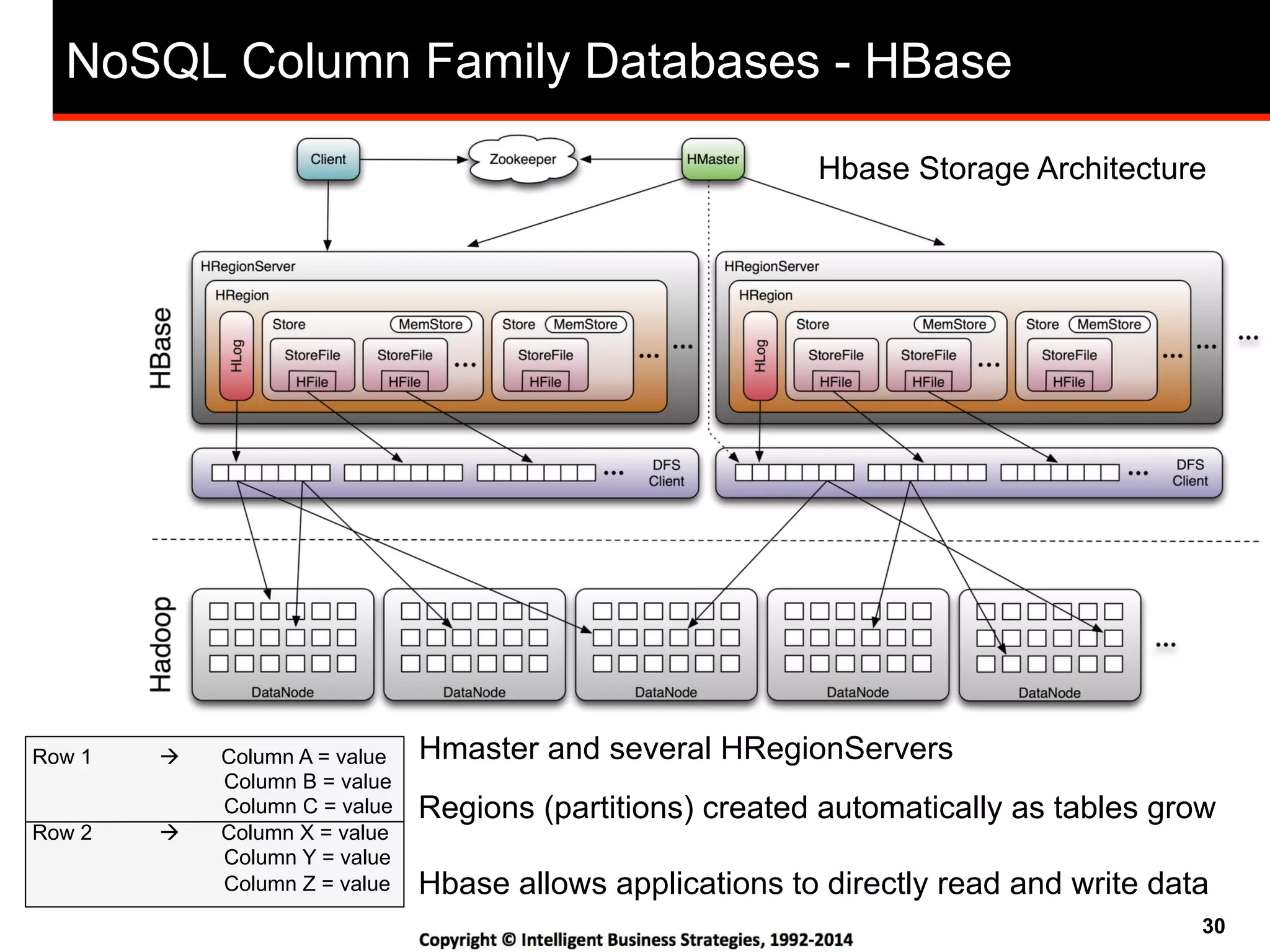
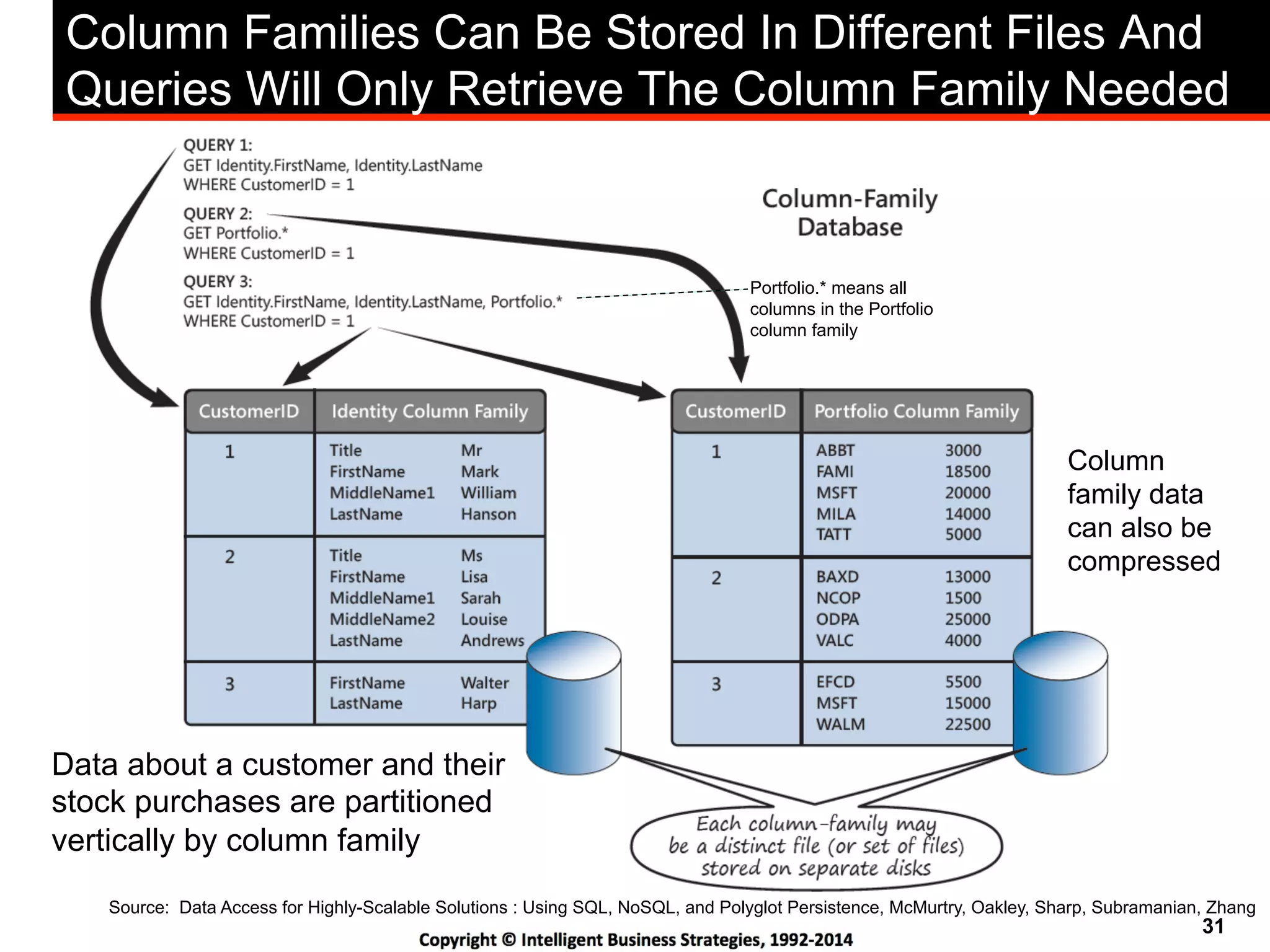
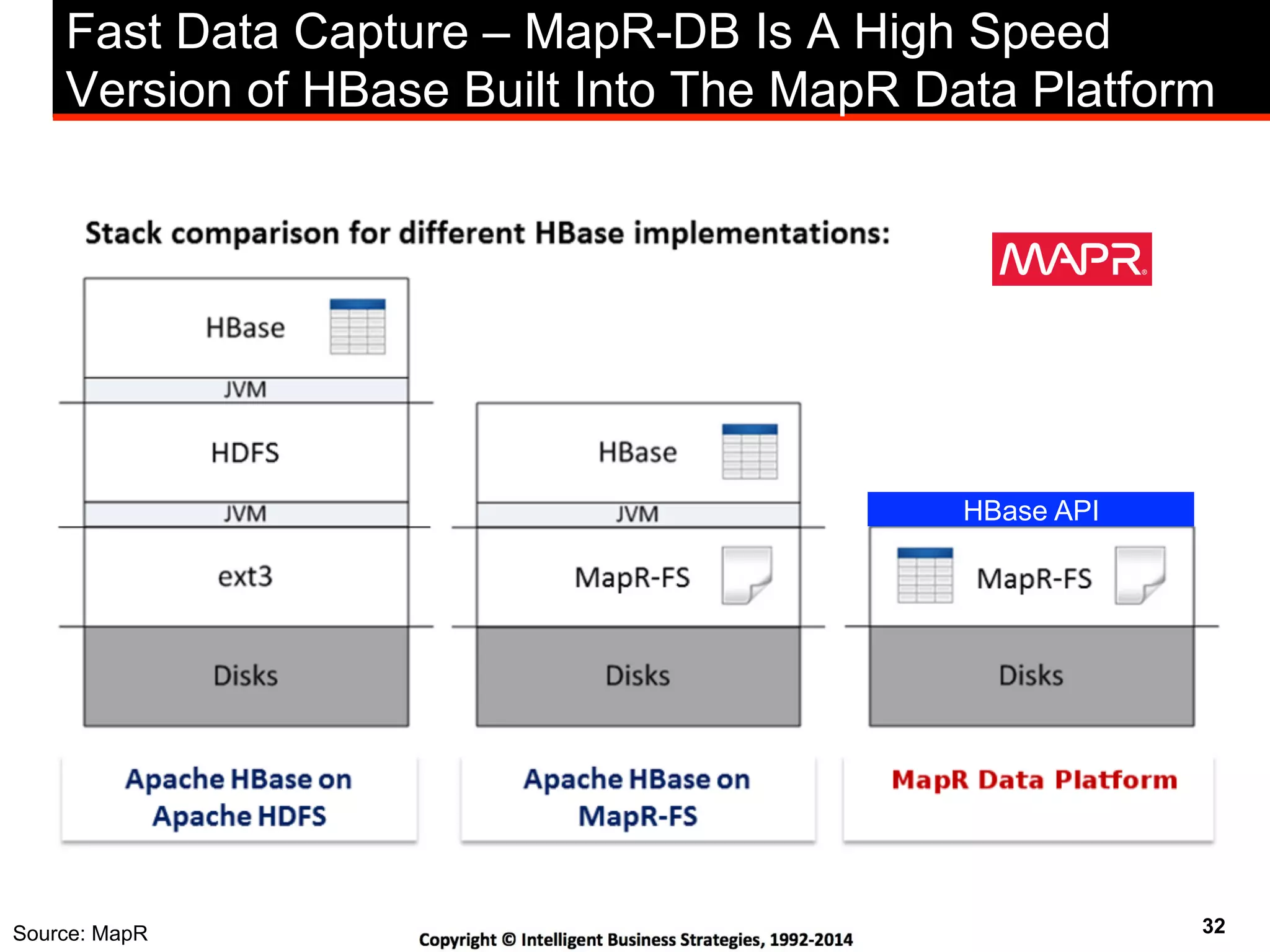

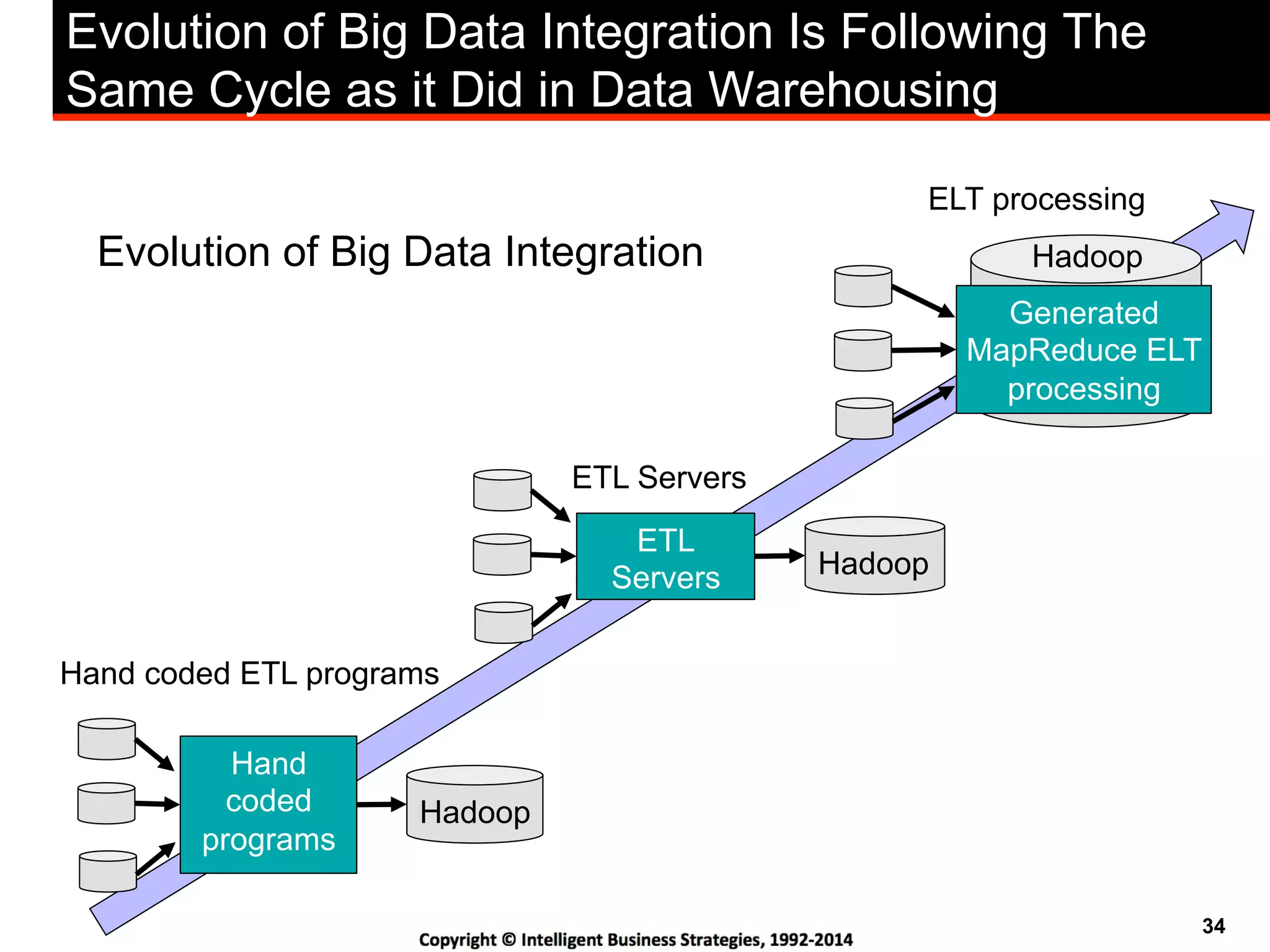
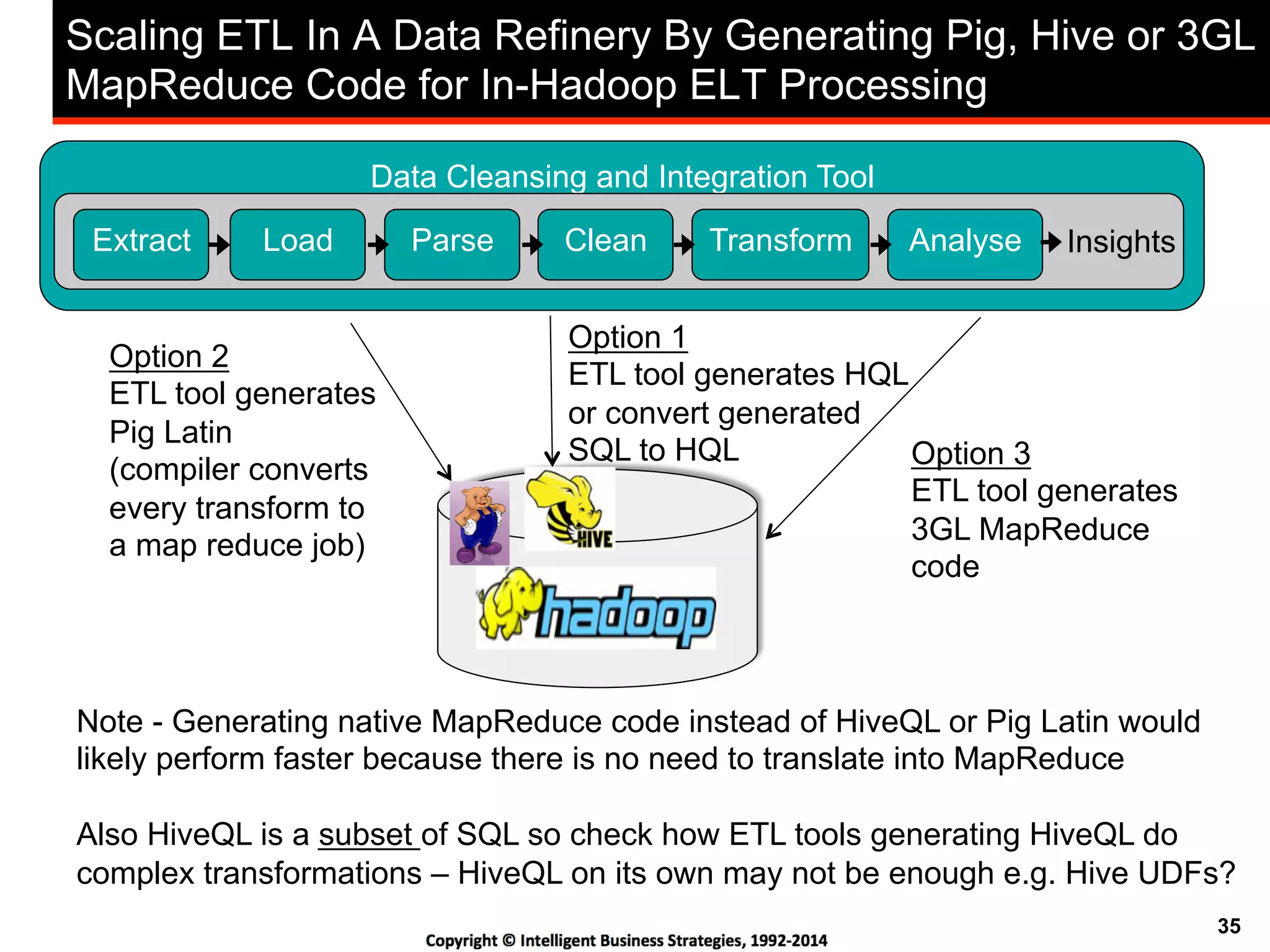
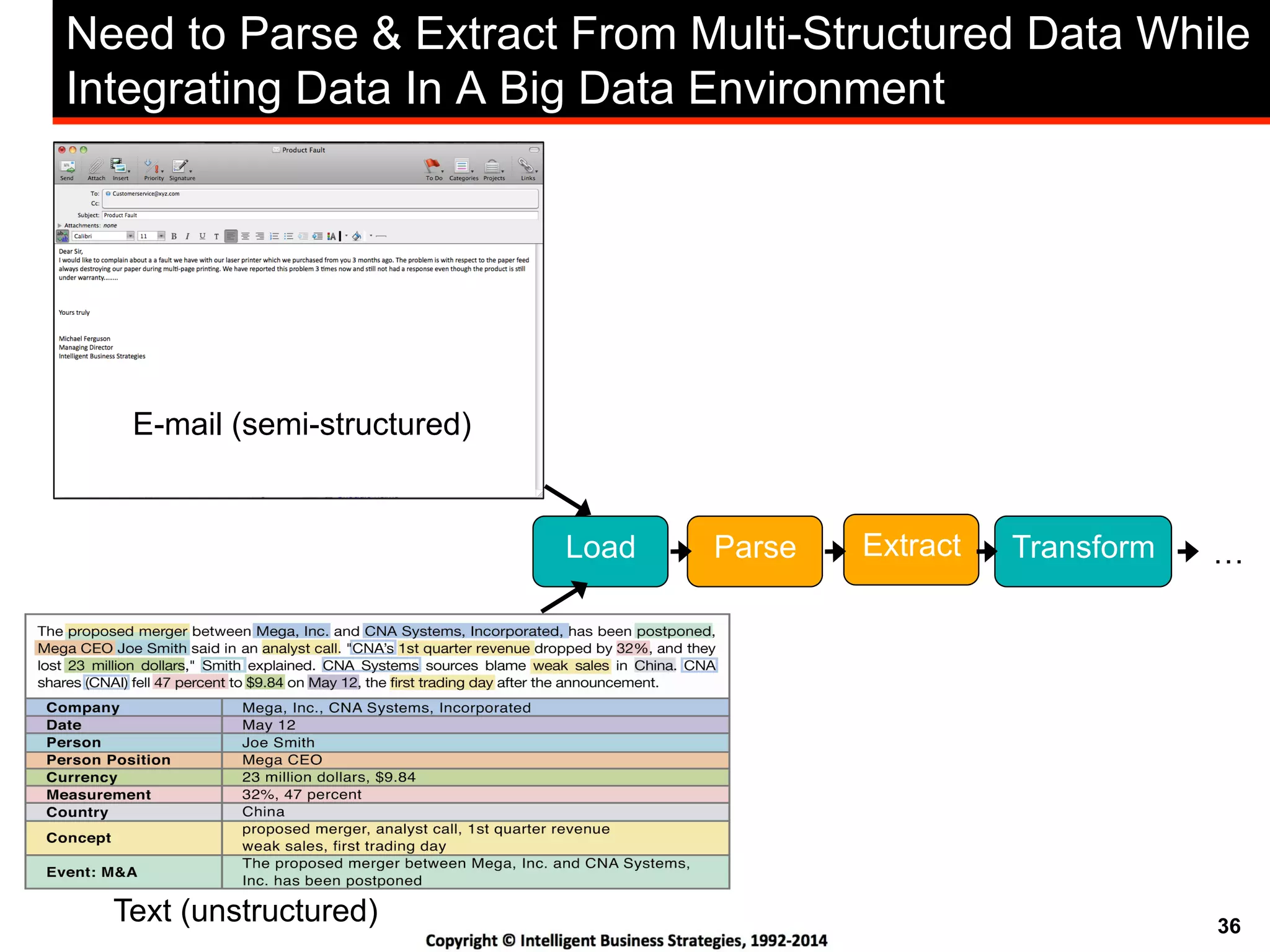
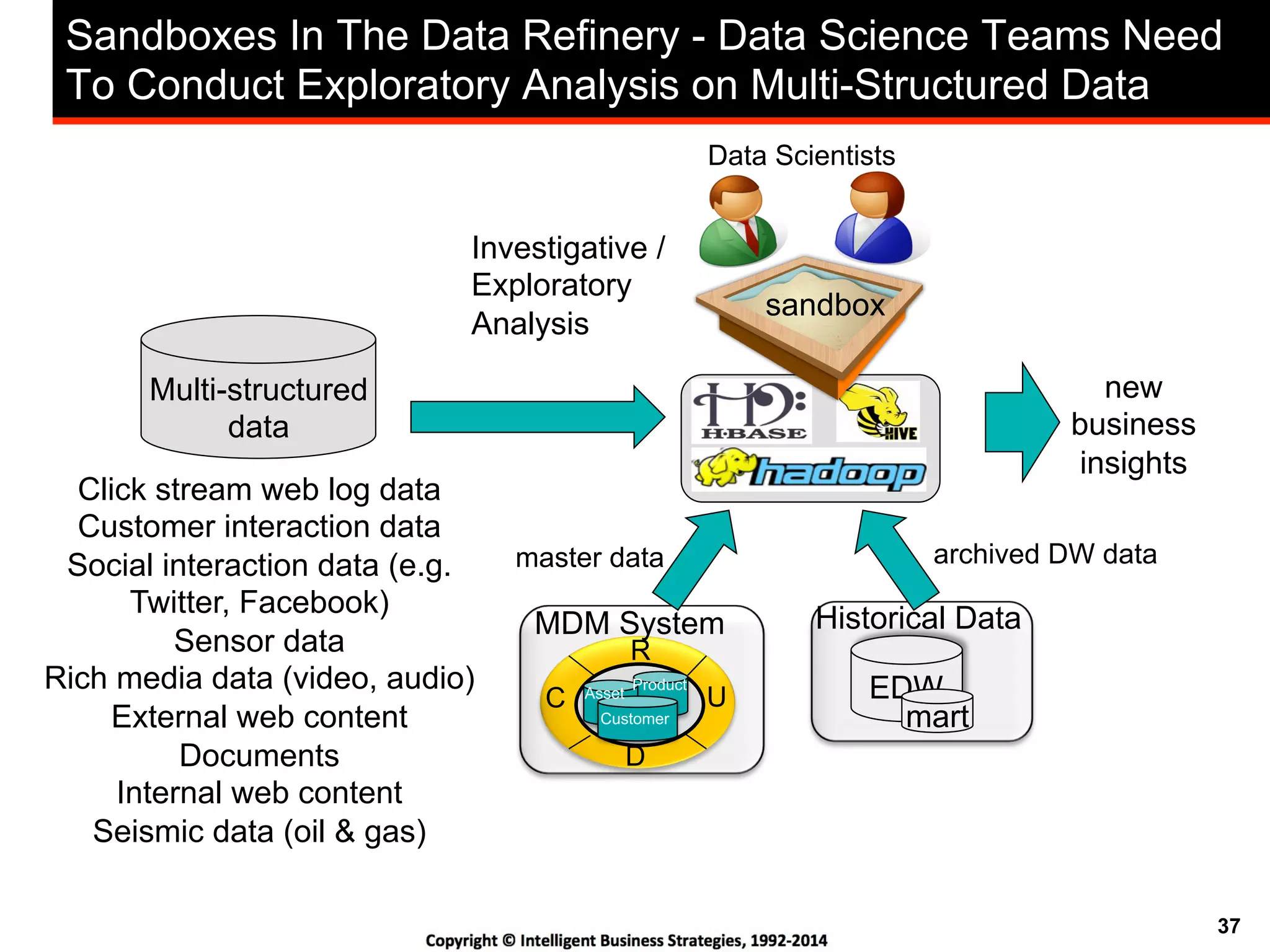


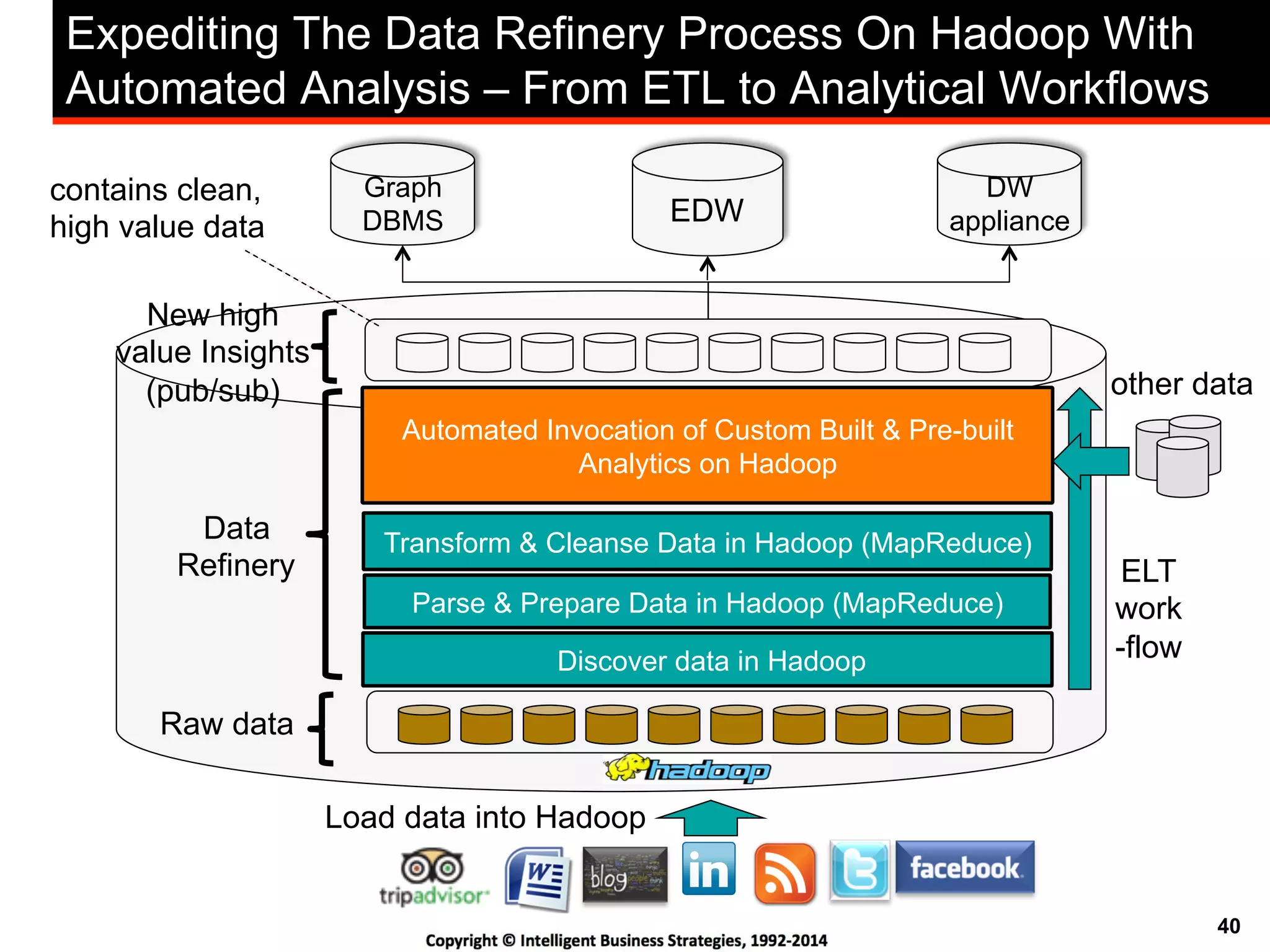
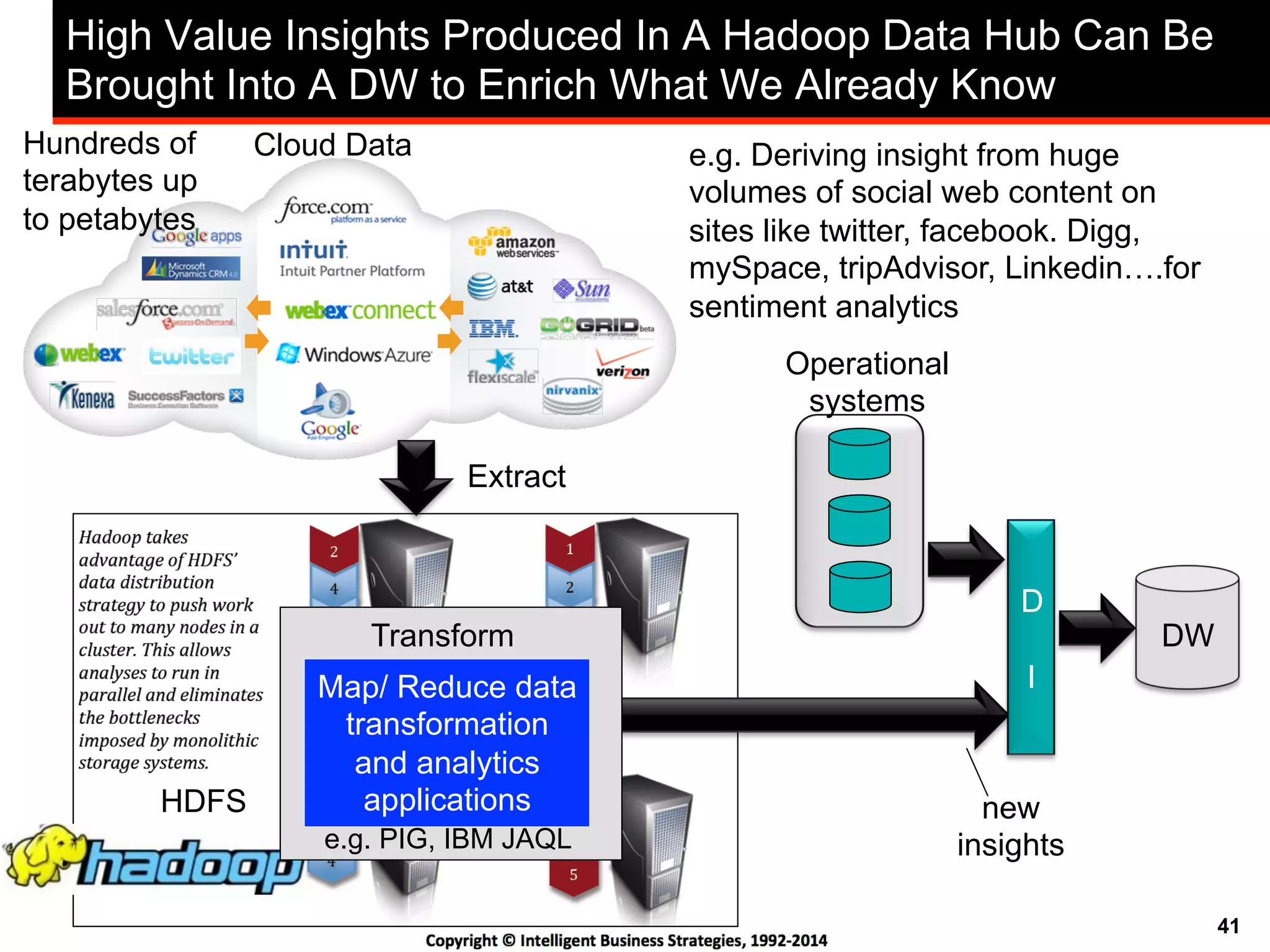
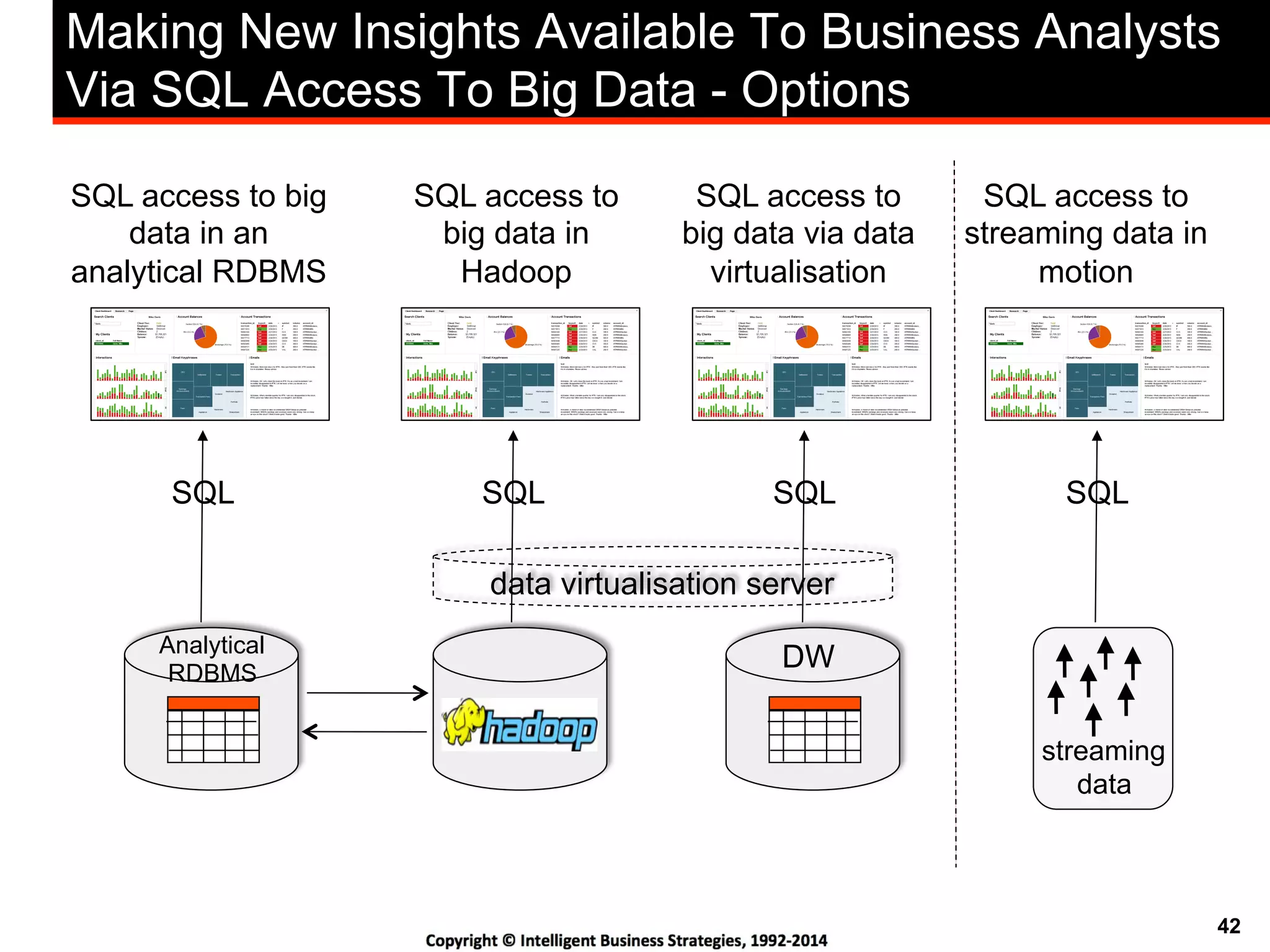
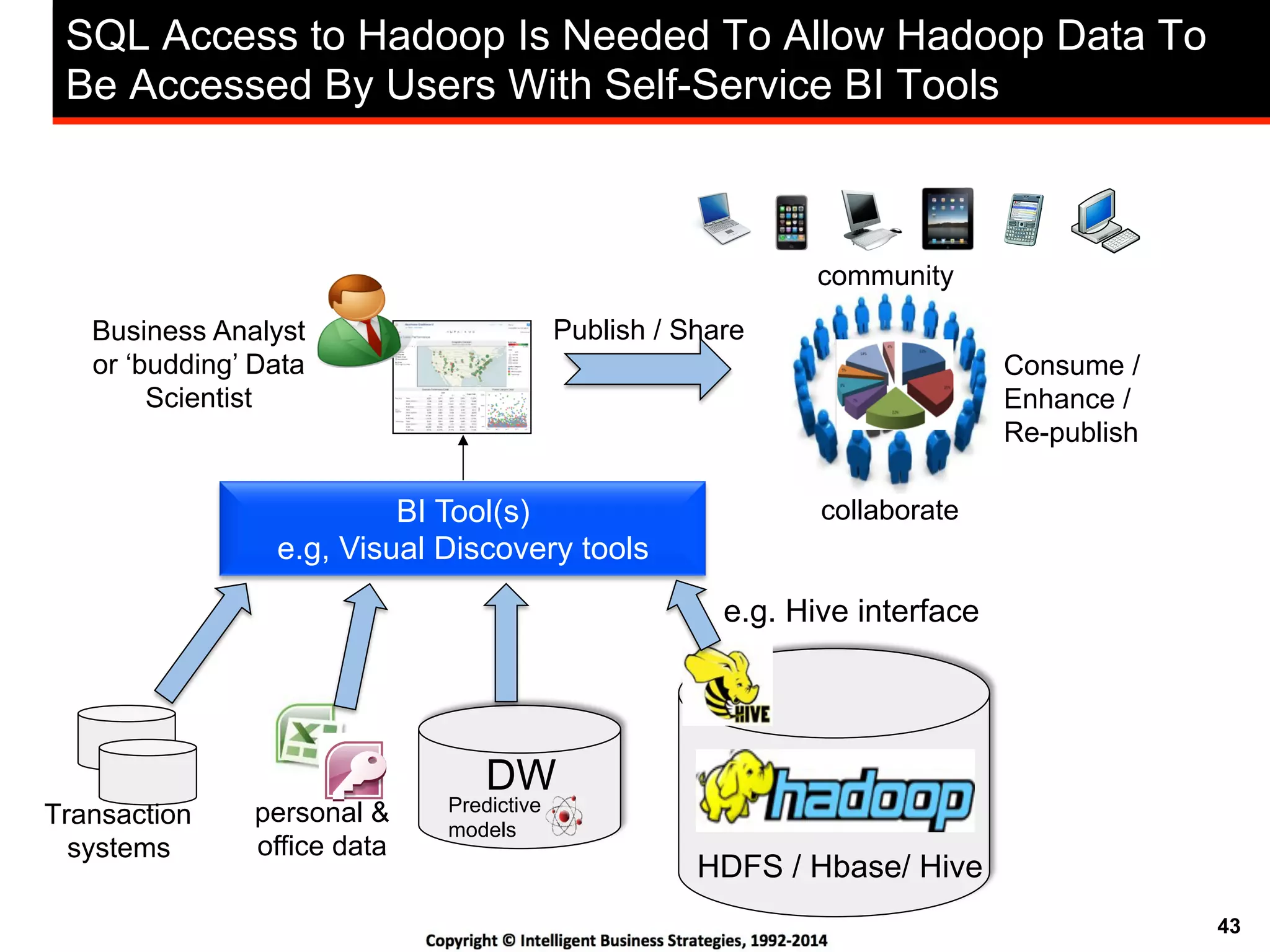


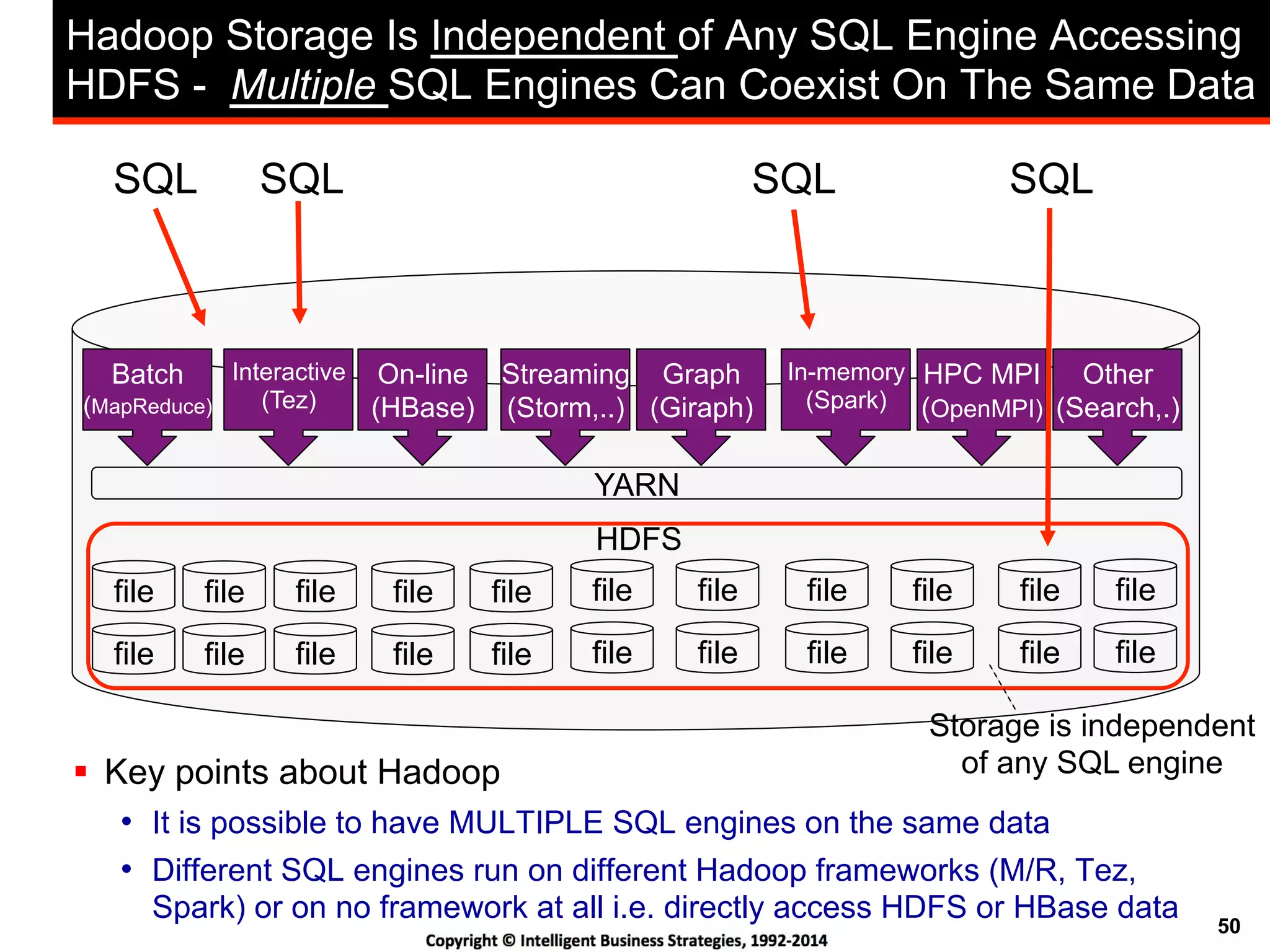
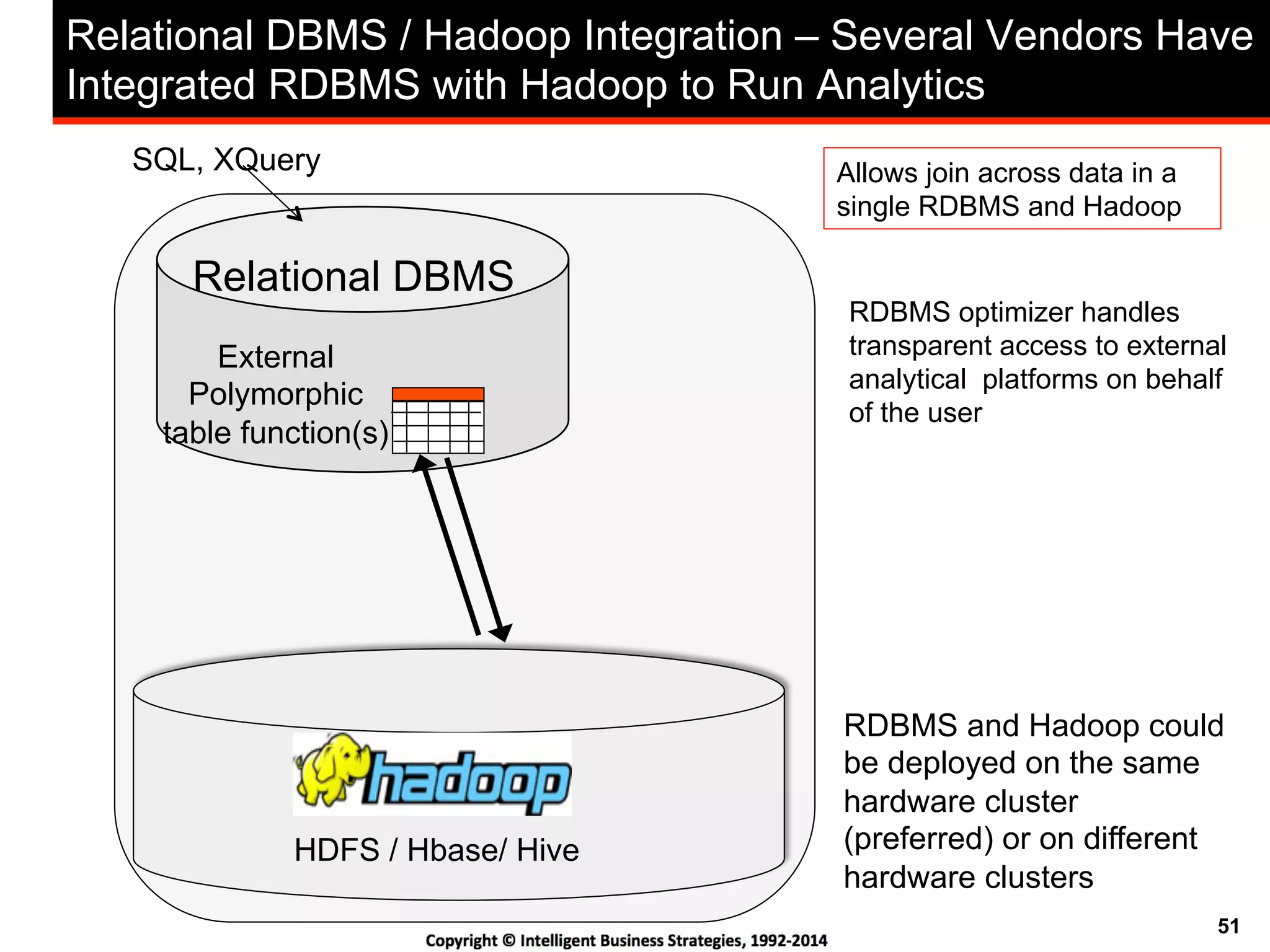
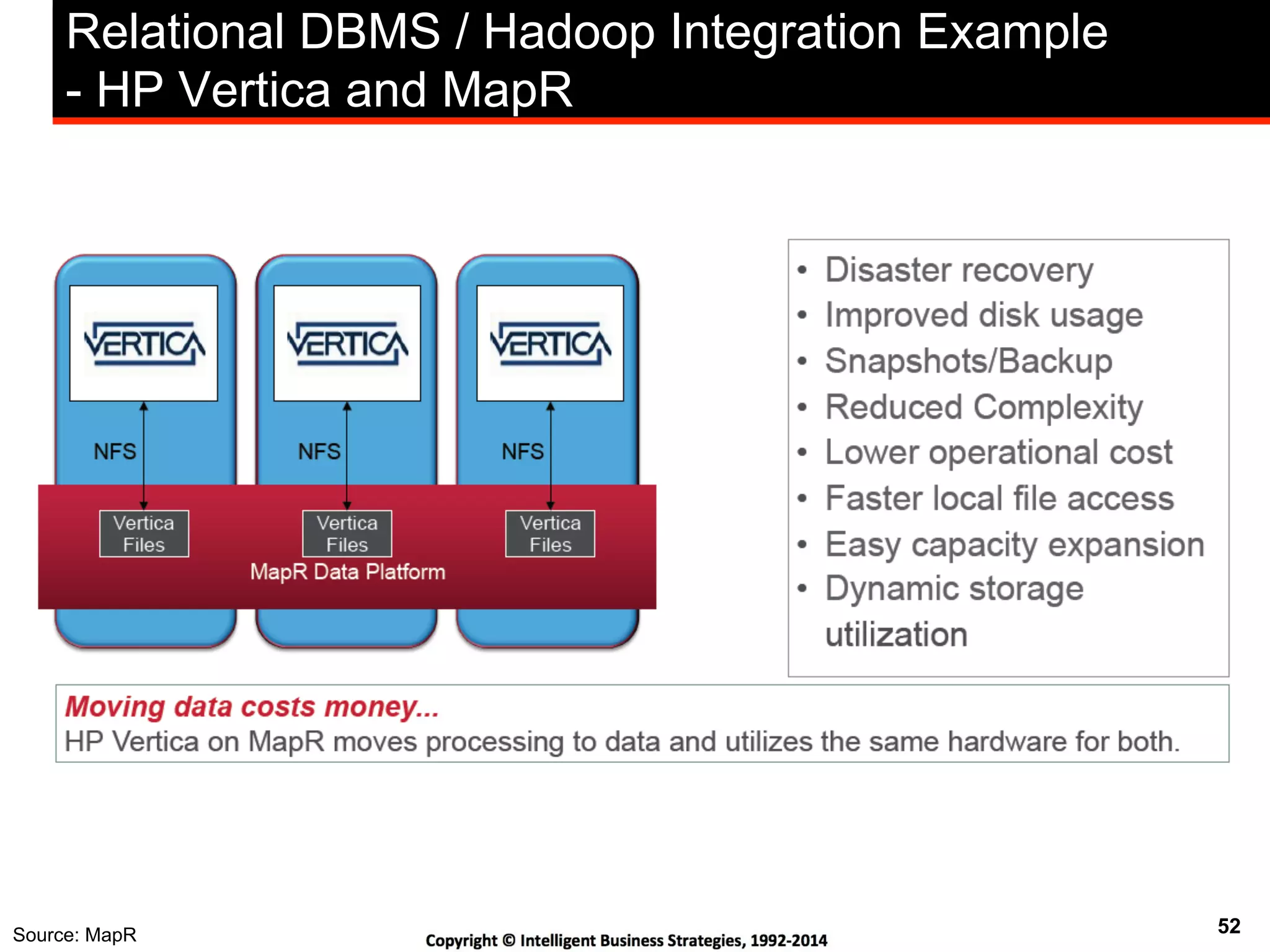
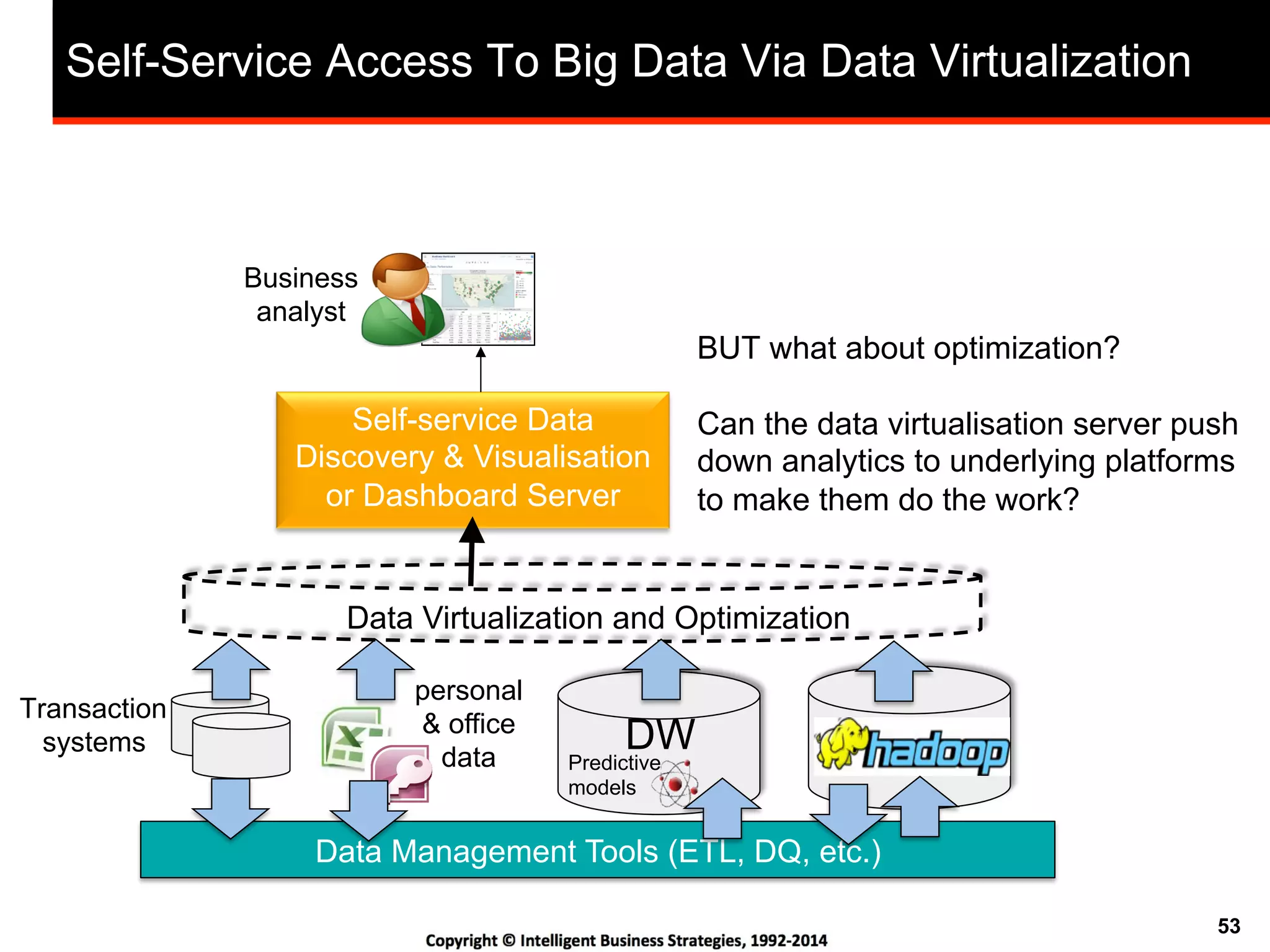
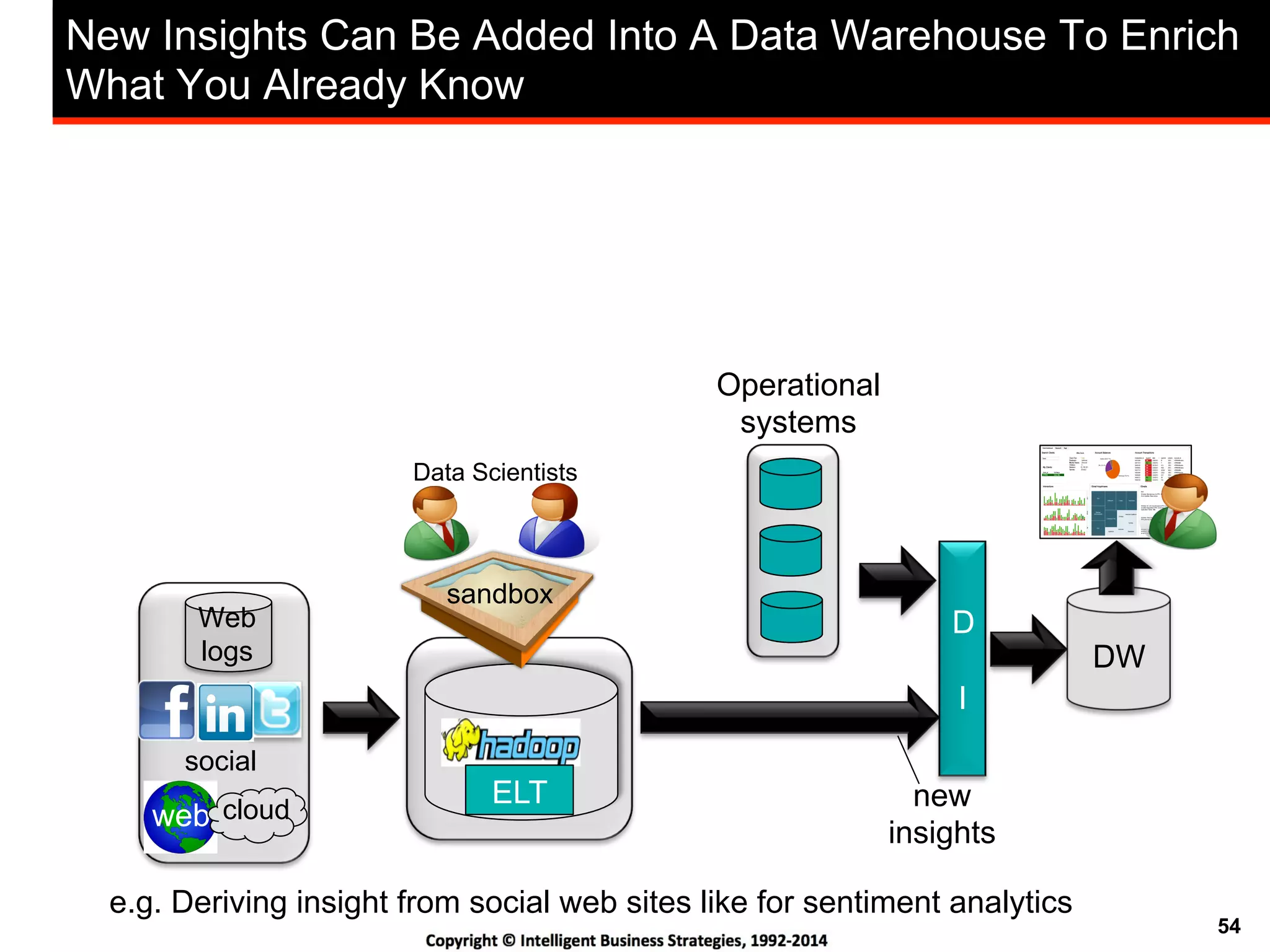
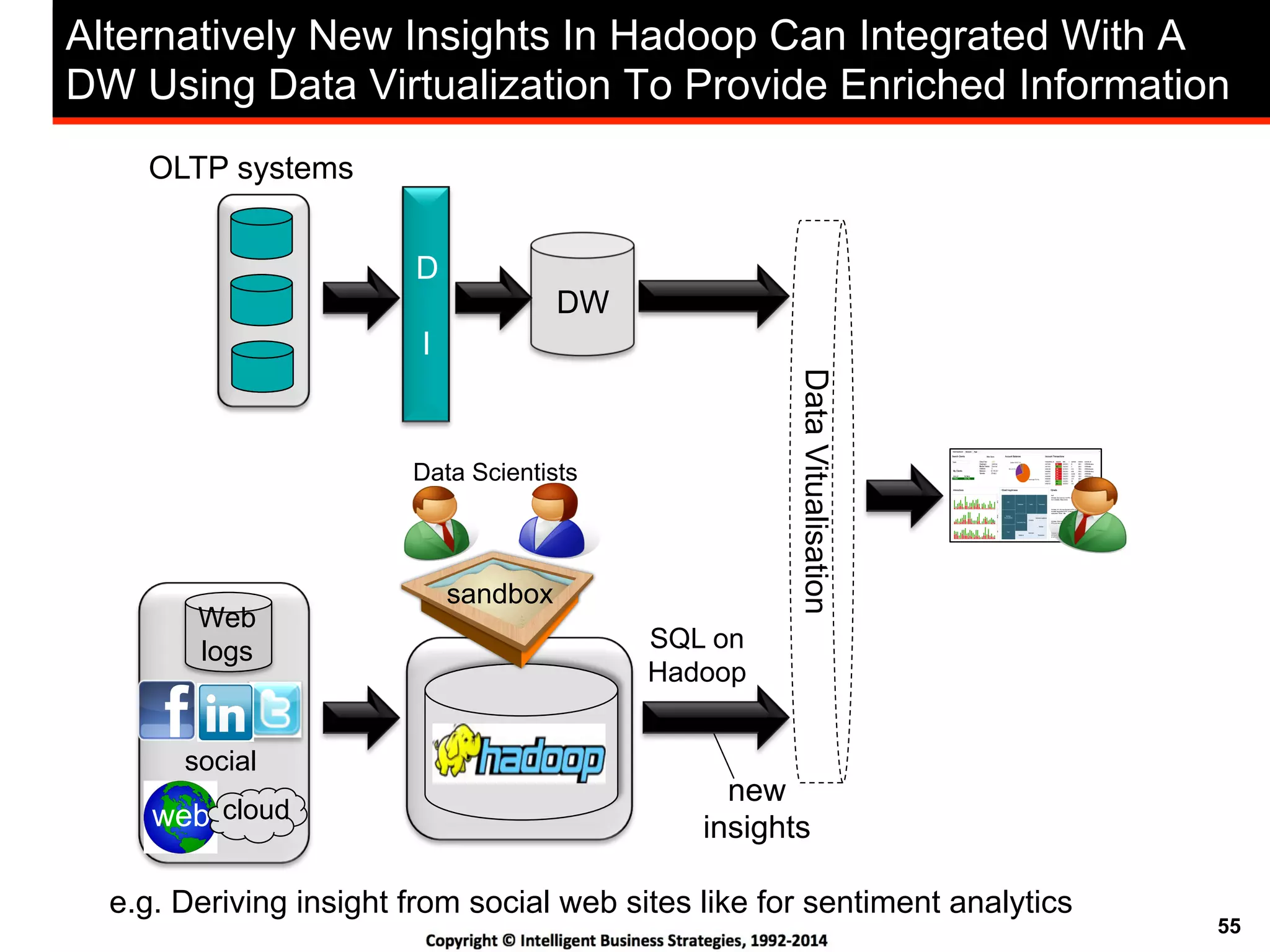
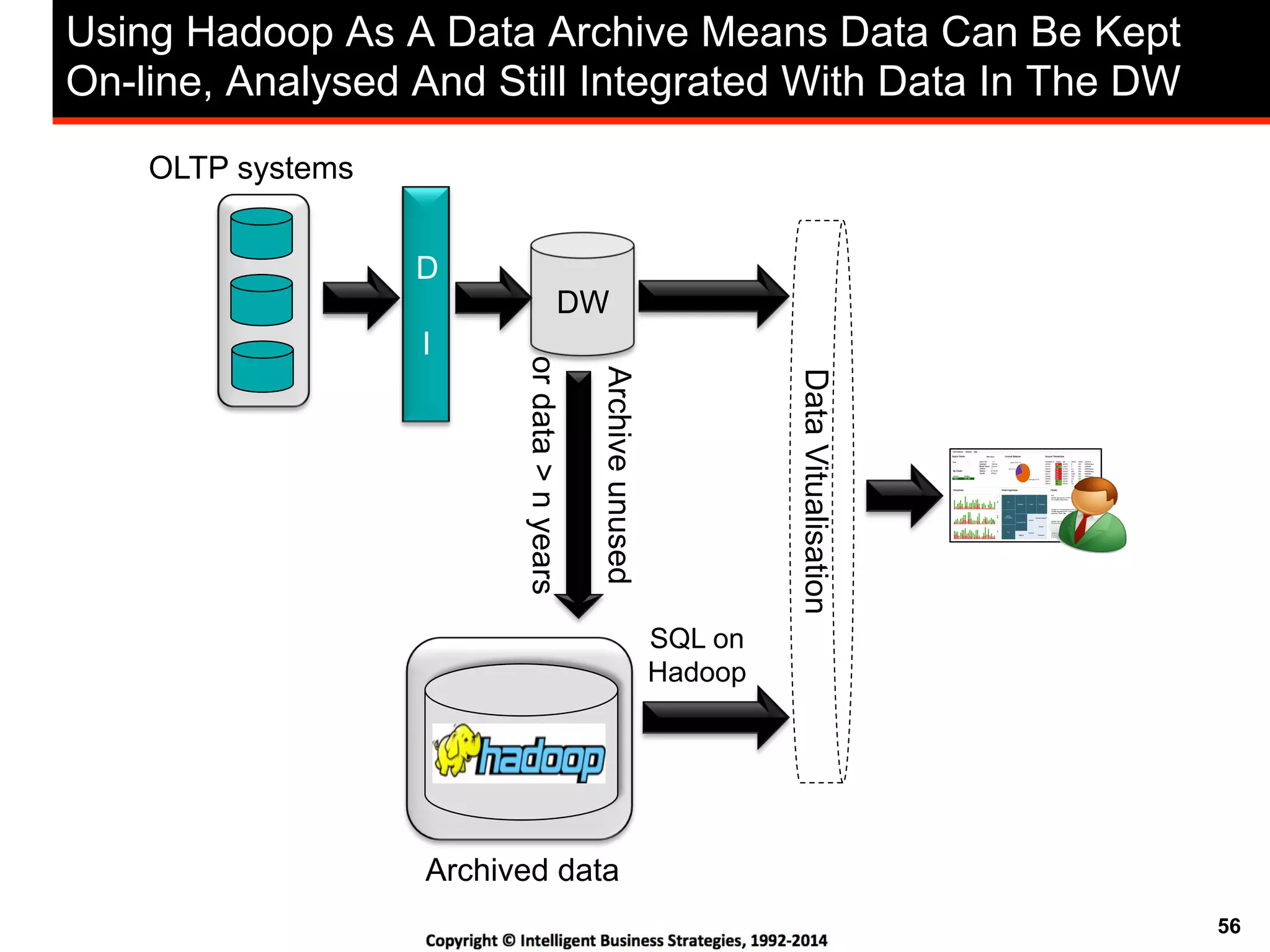
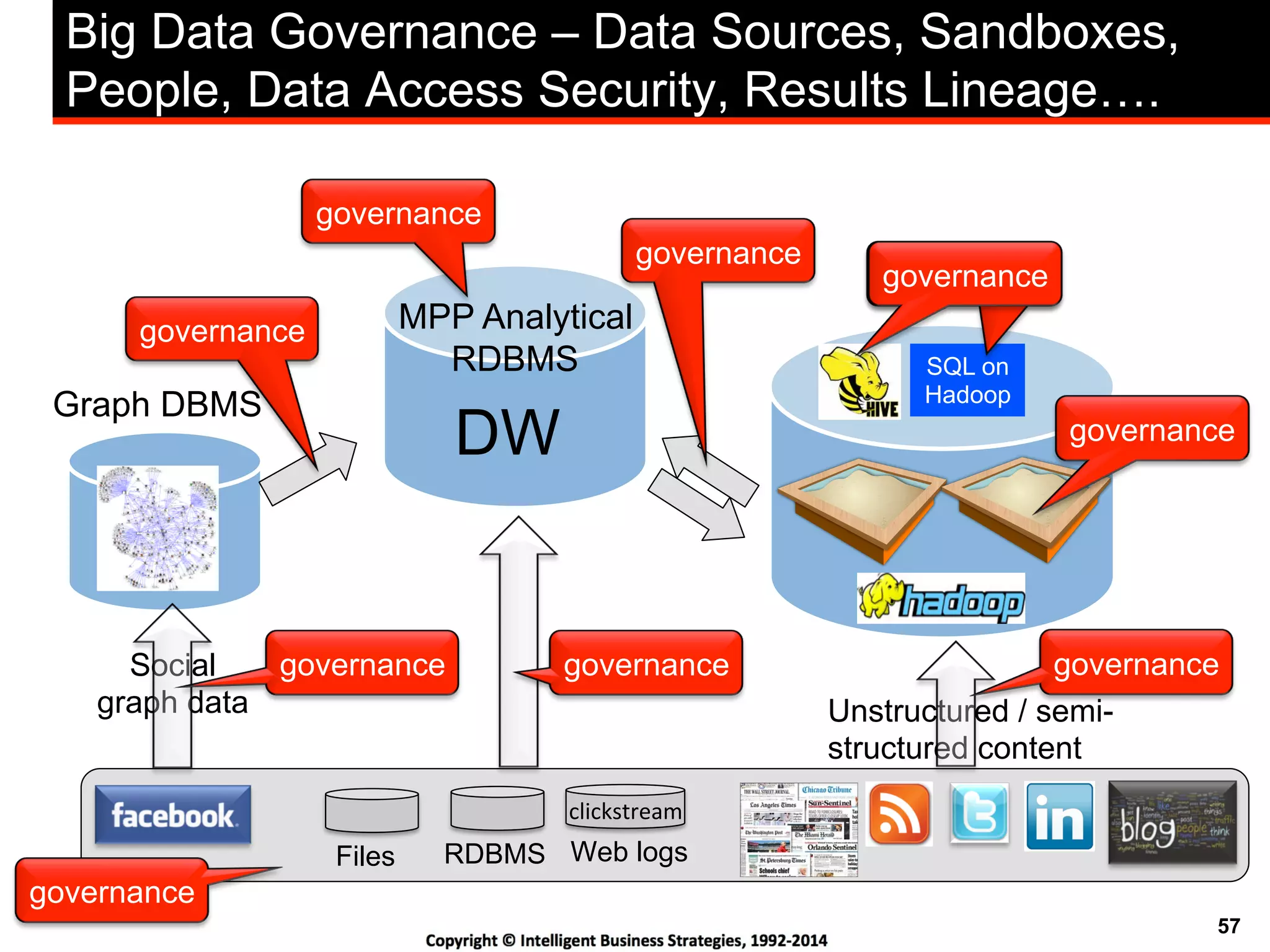
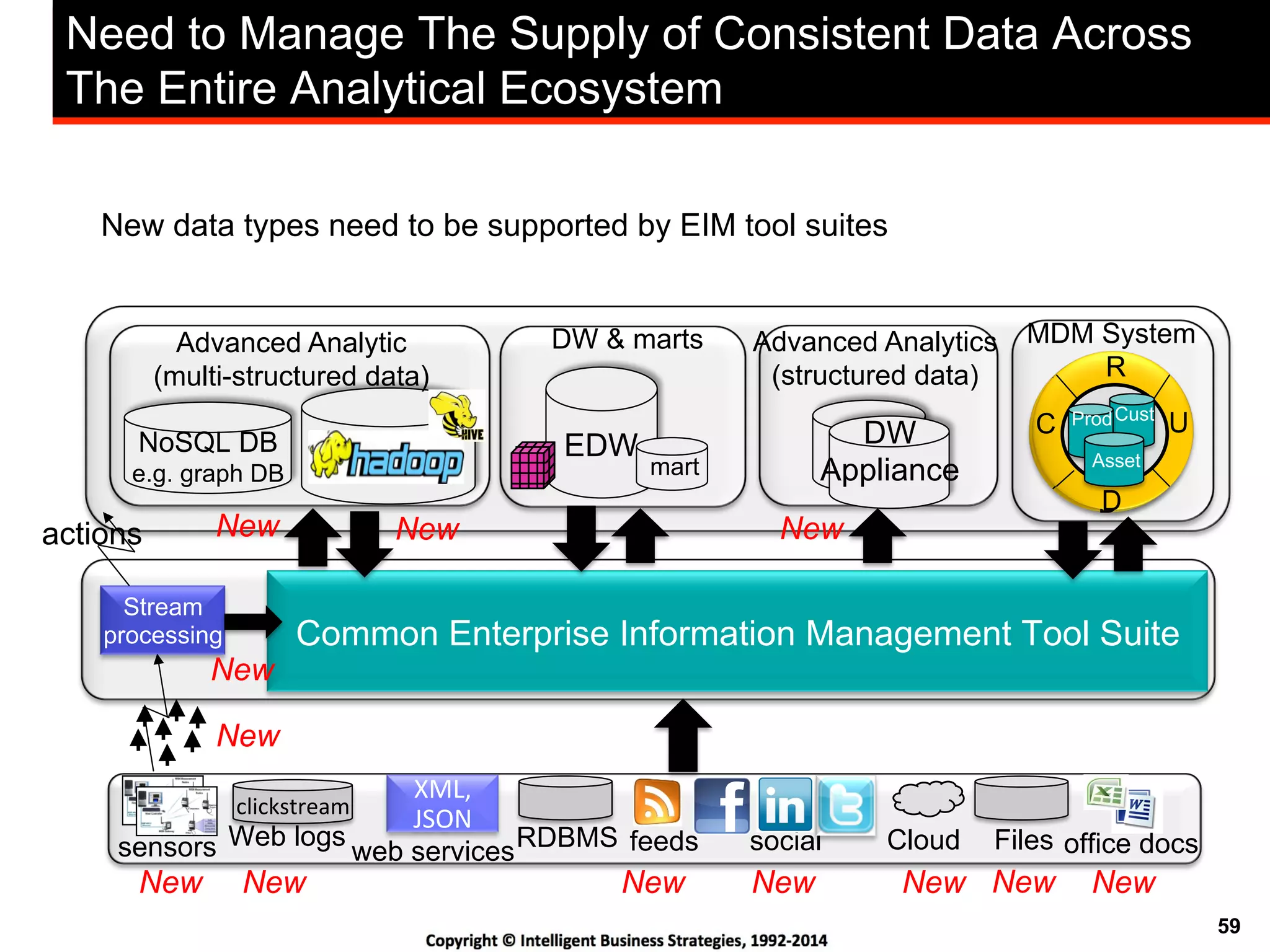
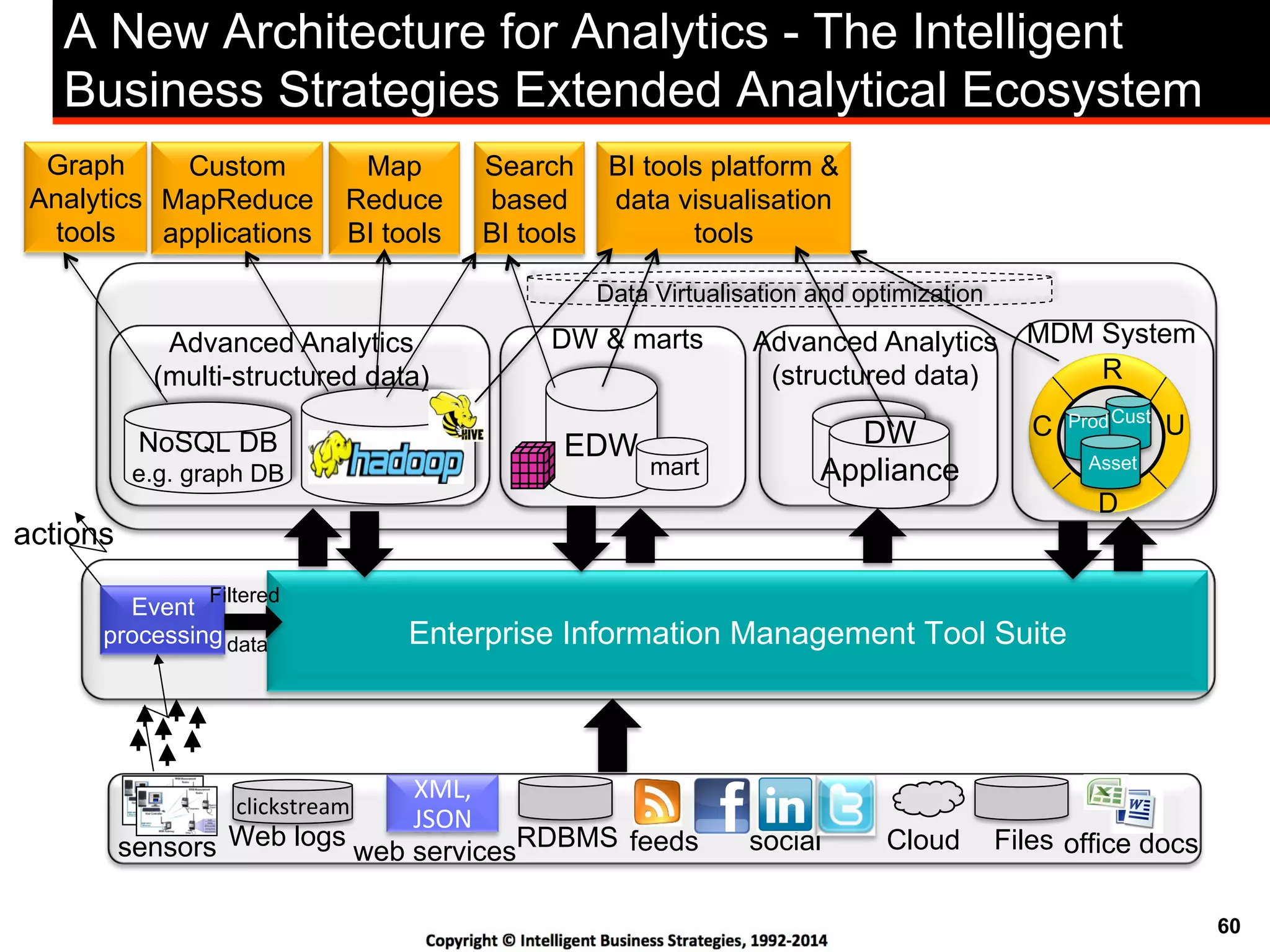


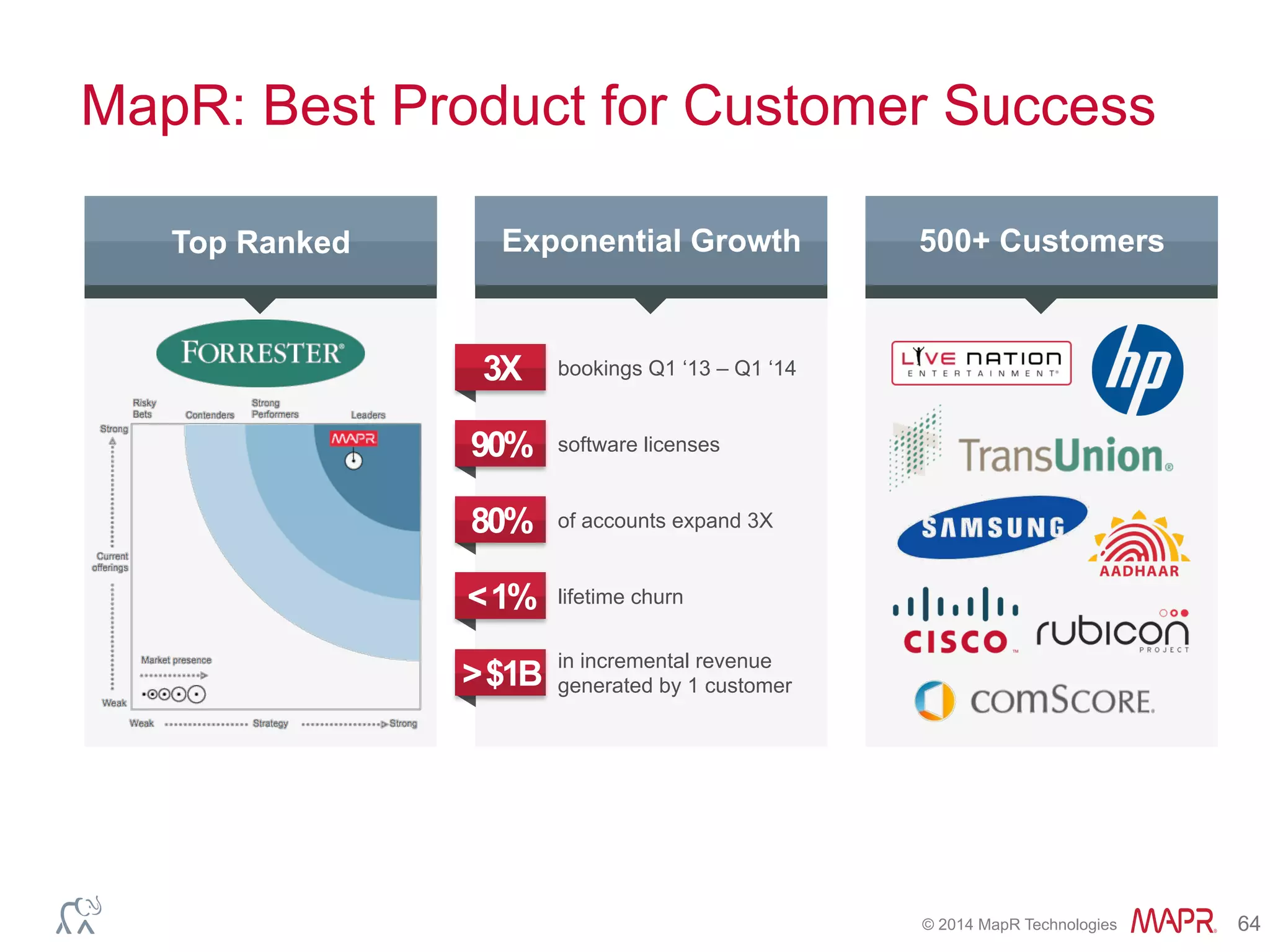

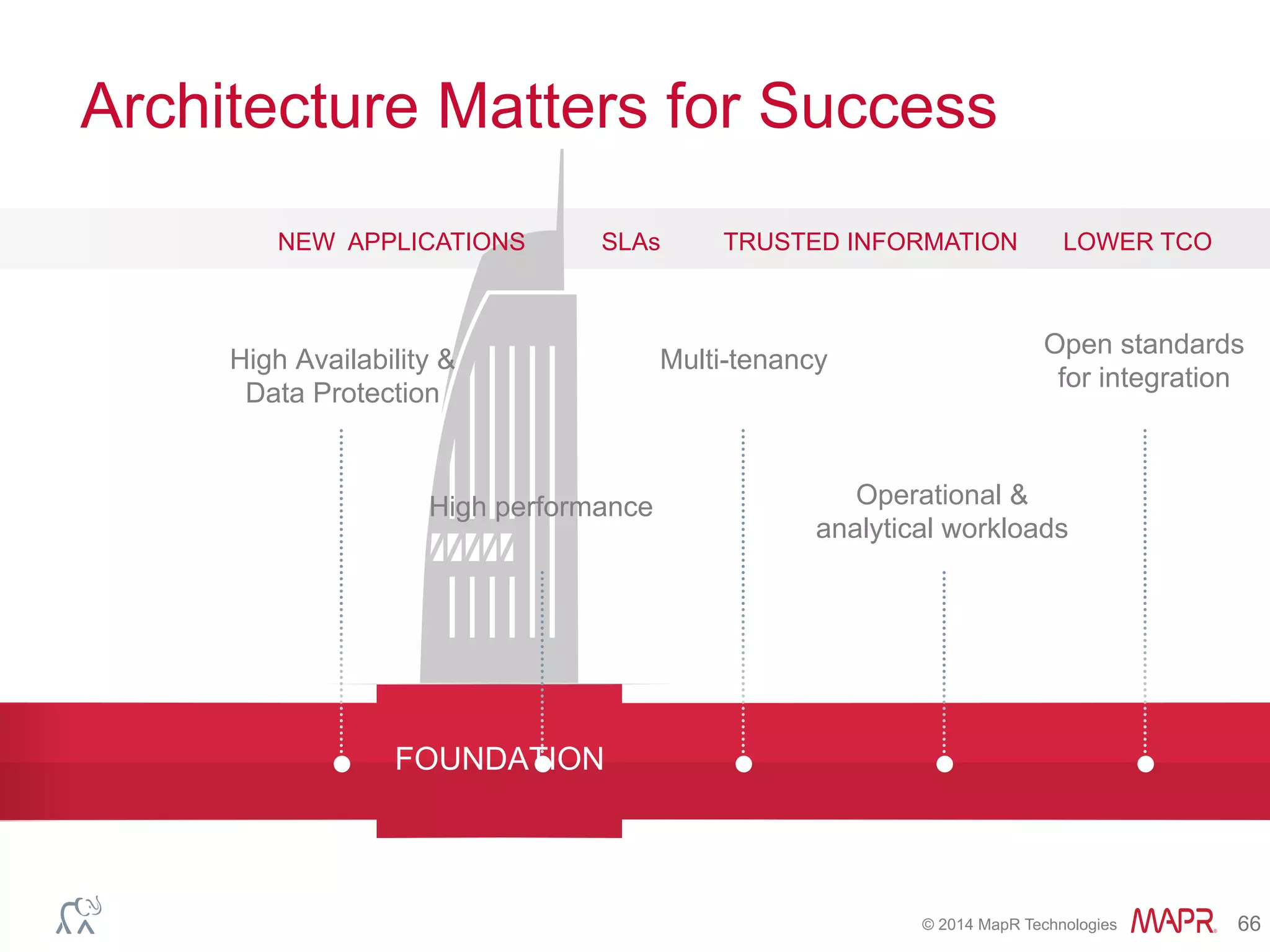
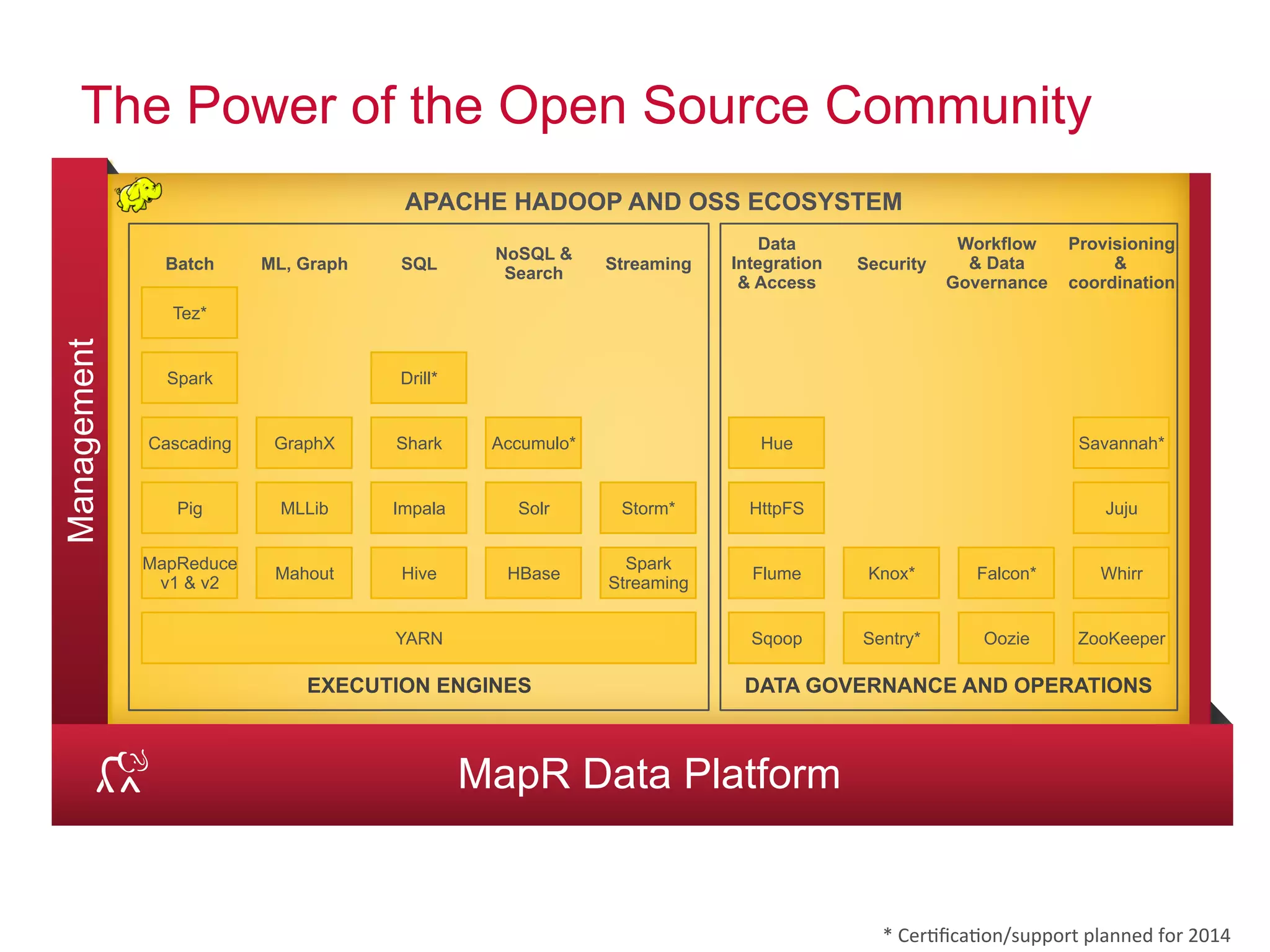
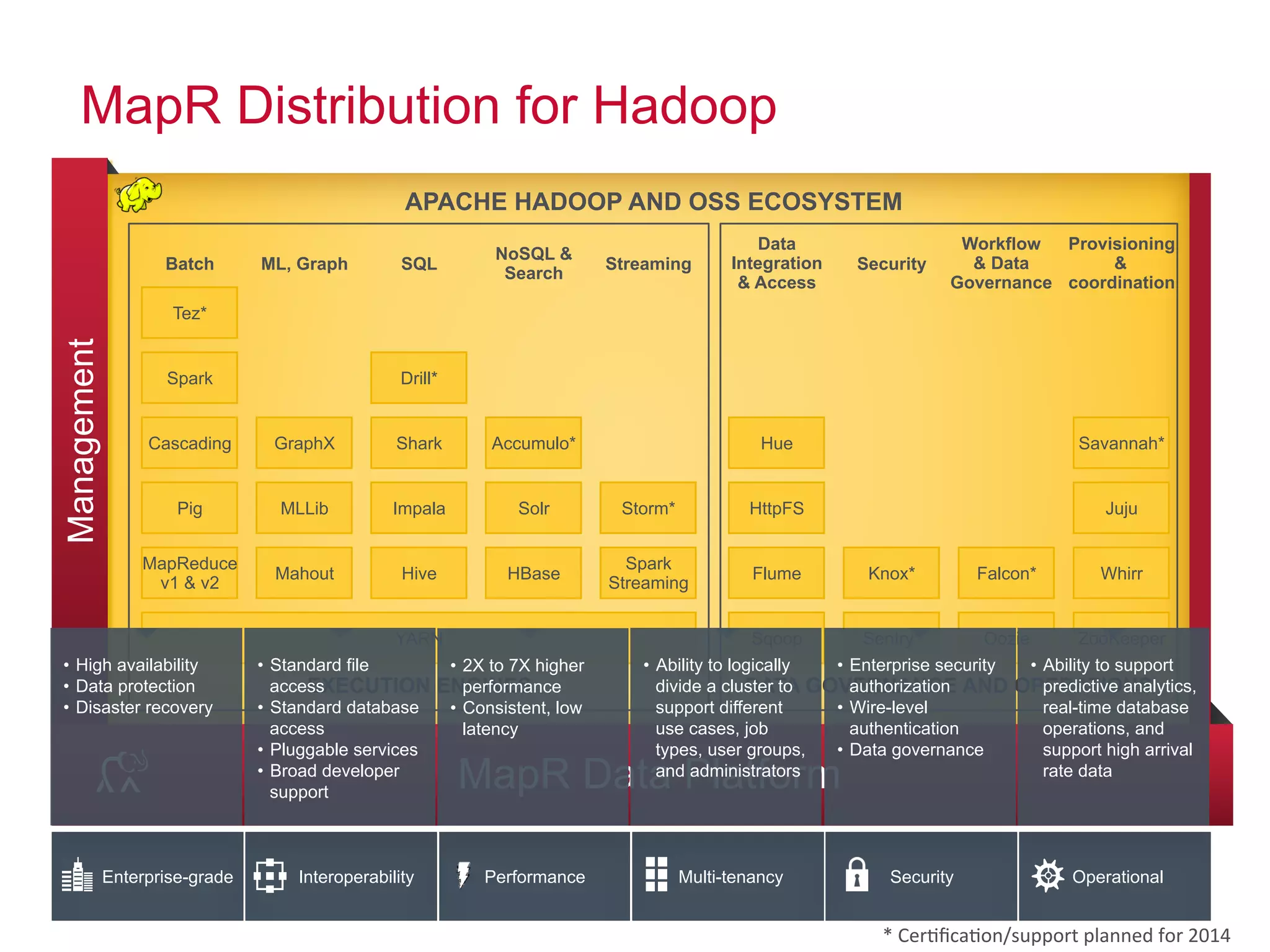



This document discusses best practices for using Hadoop as an enterprise data hub. It provides an overview of how big data is driving new analytical workloads and the need for deeper customer insights. It discusses challenges with analyzing new sources of structured, unstructured and multi-structured data. It introduces the concept of a Hadoop enterprise data hub and data refinery to simplify access to new insights from big data. Key components of the data hub include a data reservoir to capture raw data from various sources, a data refinery to cleanse and transform the data, and publishing high value insights to data warehouses and other systems.








































































































