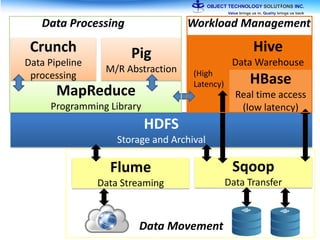
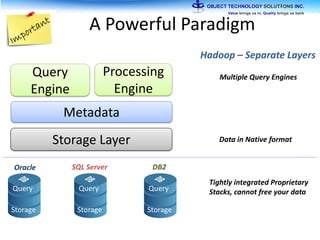
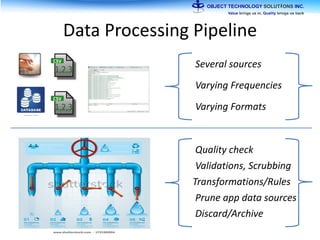
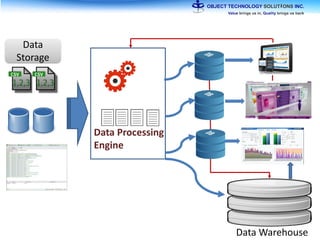
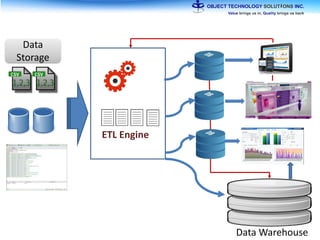
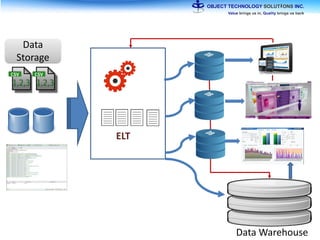
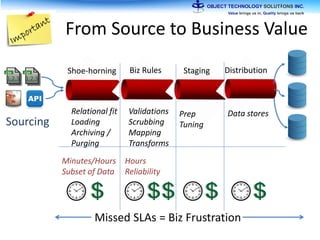
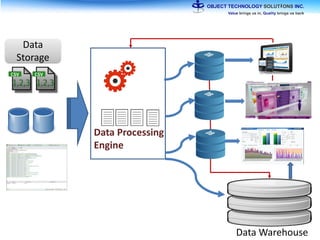
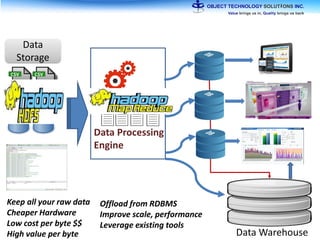
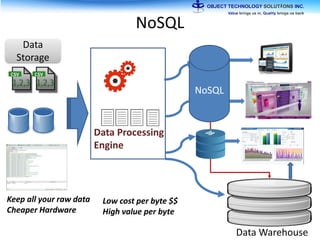
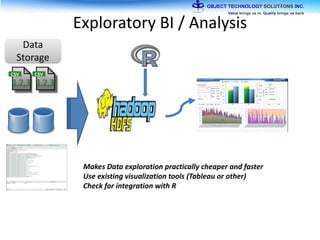
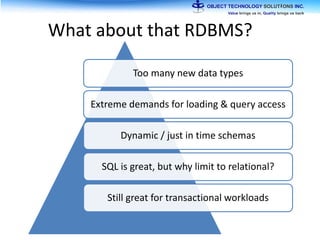
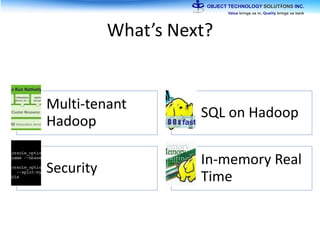
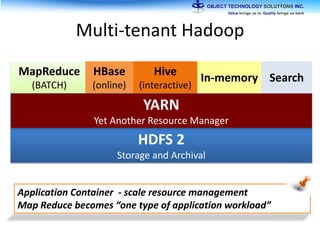
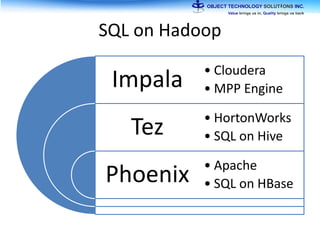
The document discusses the evolution and practical adoption of big data technologies, emphasizing their capabilities in processing and handling large scale datasets. It highlights real-world applications from various industries, and the importance of understanding data architecture for successful implementation. The text also touches on the future of big data with advancements such as SQL on Hadoop and the use of distributed computing frameworks.























































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)









