Downloaded 21 times













![Query language
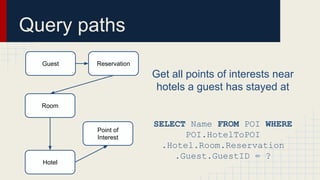
SELECT [attributes] FROM [entity]
WHERE [path](=|<|<=|>|>=) [value] AND …
ORDER BY [path] LIMIT [count]
Conjunctive queries with simple predicates and ordering
Higher level queries can be composed by the application](https://image.slidesharecdn.com/sigmod2014presentation-160523135616/85/Automated-Schema-Design-for-NoSQL-Databases-22-320.jpg)
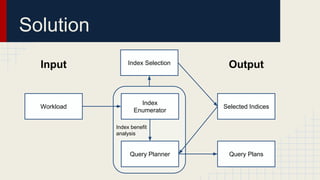



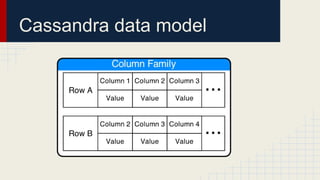
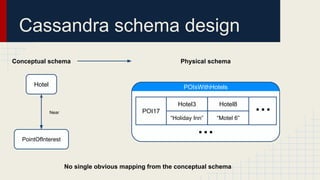
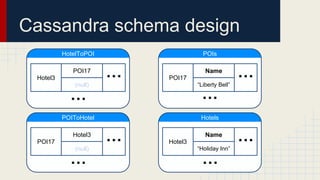
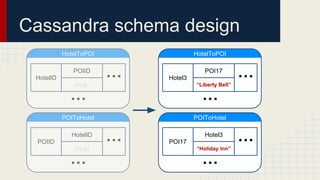
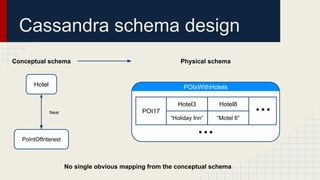
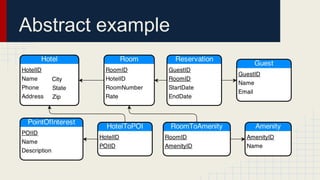
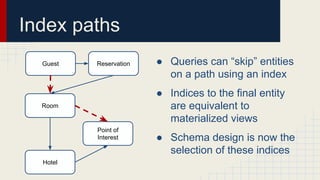
The document discusses automated schema design for NoSQL databases, particularly focusing on Cassandra, addressing challenges such as storage costs and schema optimization for specific workloads. It outlines the need for a workload-driven approach and details methods for index selection and query planning. Future work includes expanding to other NoSQL databases and improving query plan implementations.






























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)
