Download as PDF, PPTX










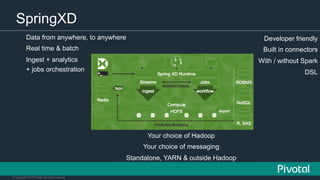

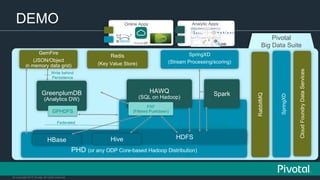


The document discusses the evolution of data architectures from Hadoop to data lakes, emphasizing the importance of becoming data-driven through modern applications and agile development. It highlights the collaboration between Pivotal and Hortonworks to standardize the Hadoop ecosystem and the open sourcing of various data suite components. The text also outlines innovations like the Pivotal Big Data Suite, which includes tools for data ingestion, analytics, and application development in a cloud-oriented environment.







































































































