Downloaded 36 times




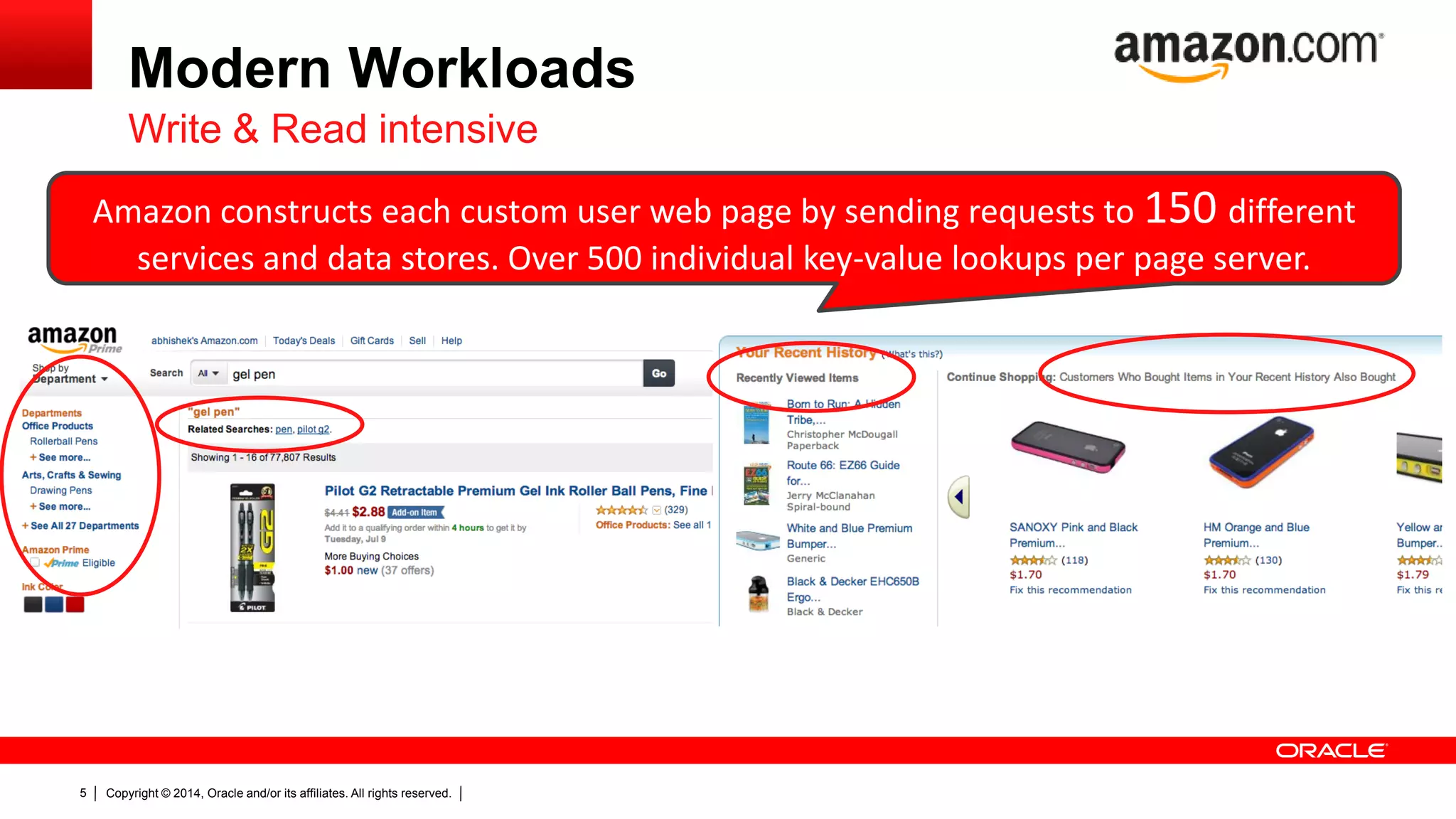
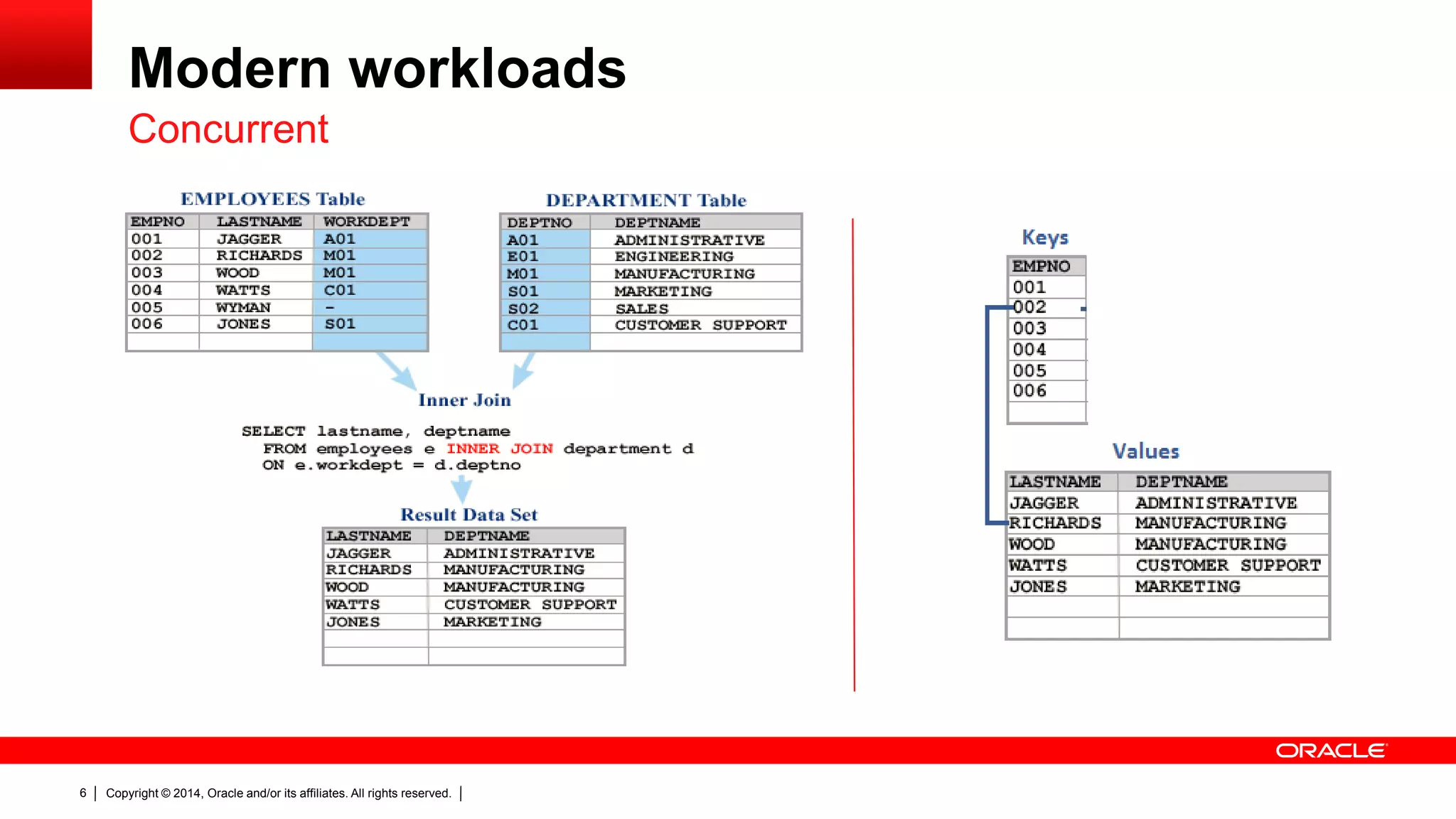
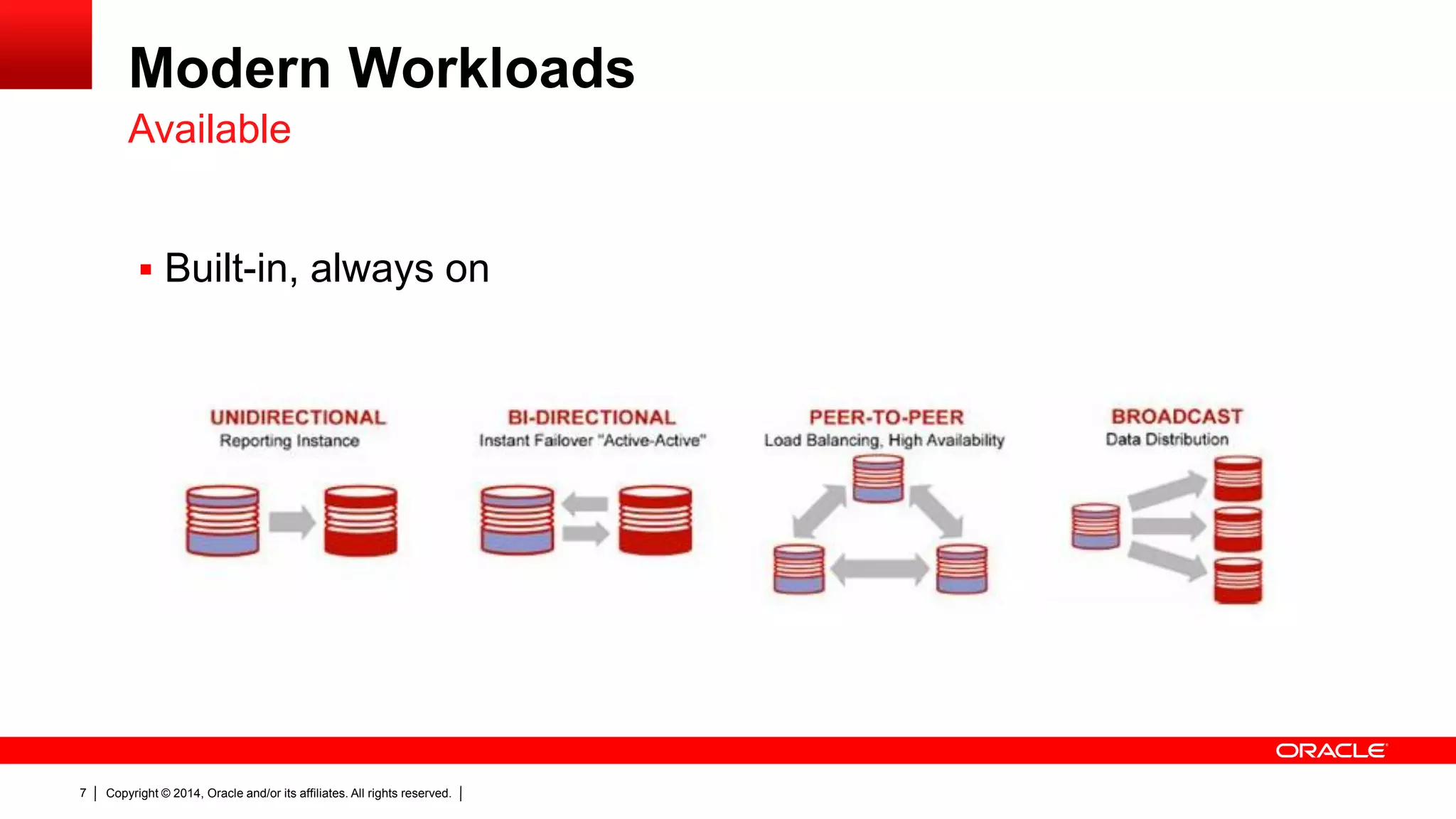
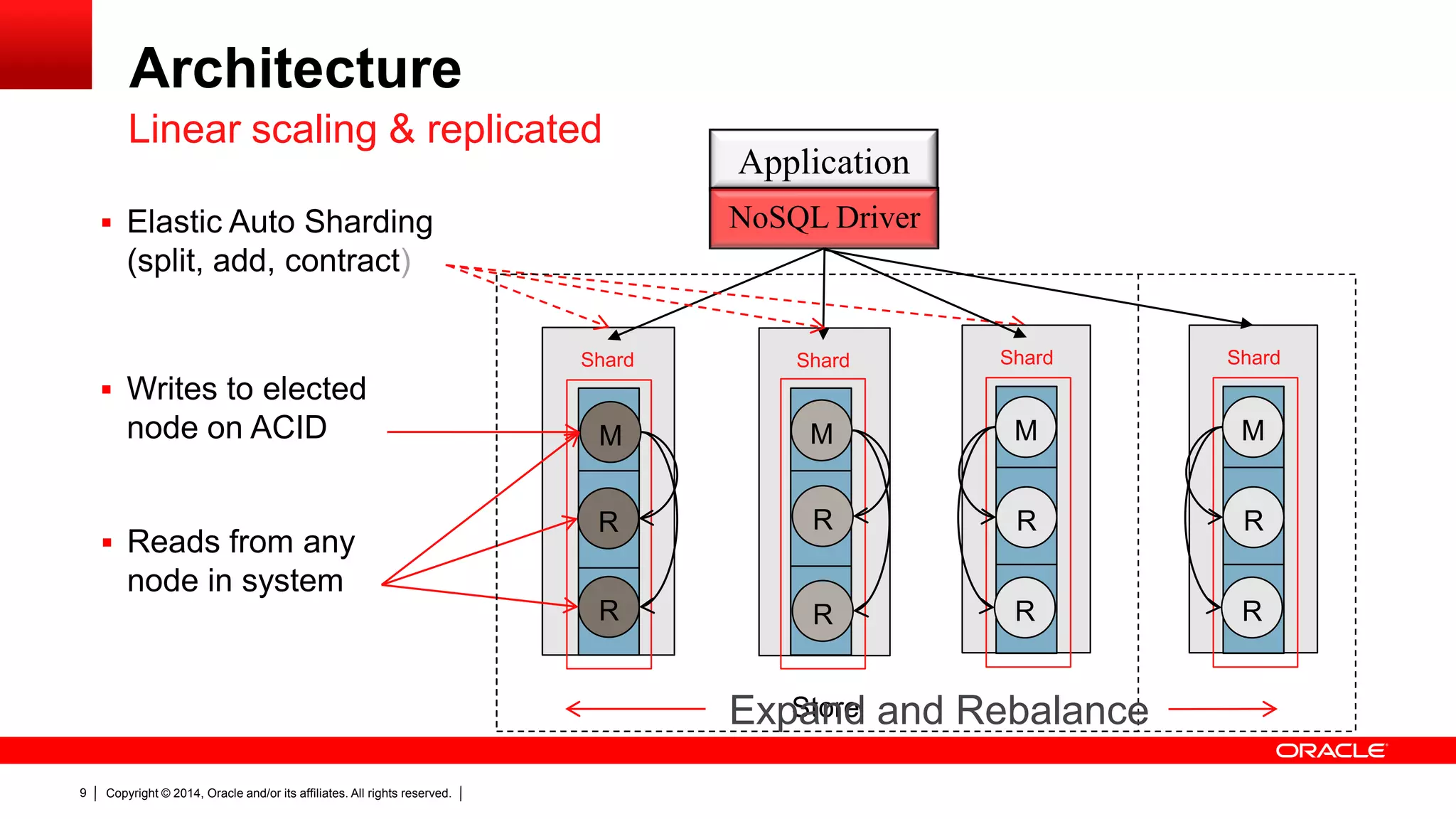
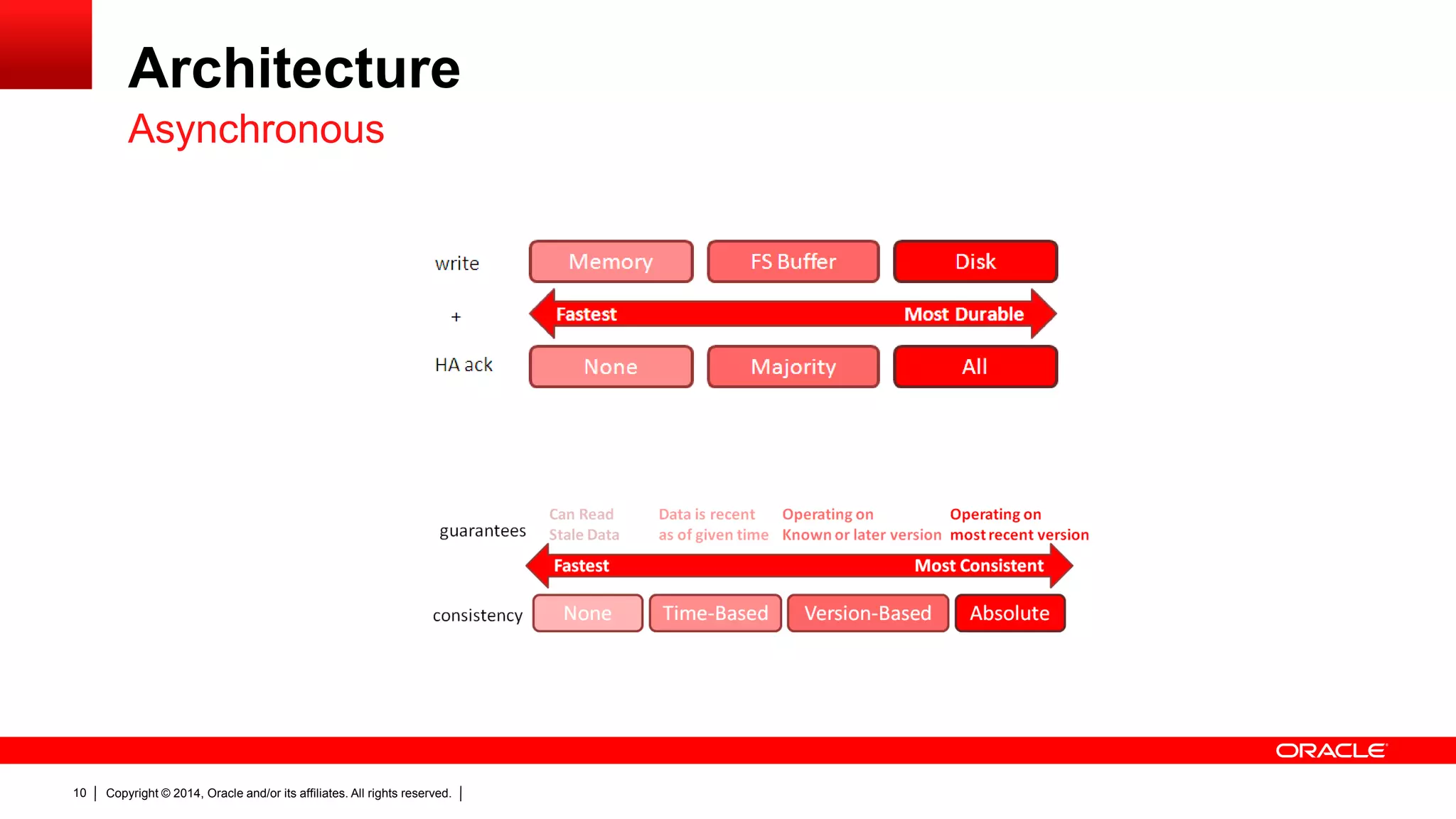
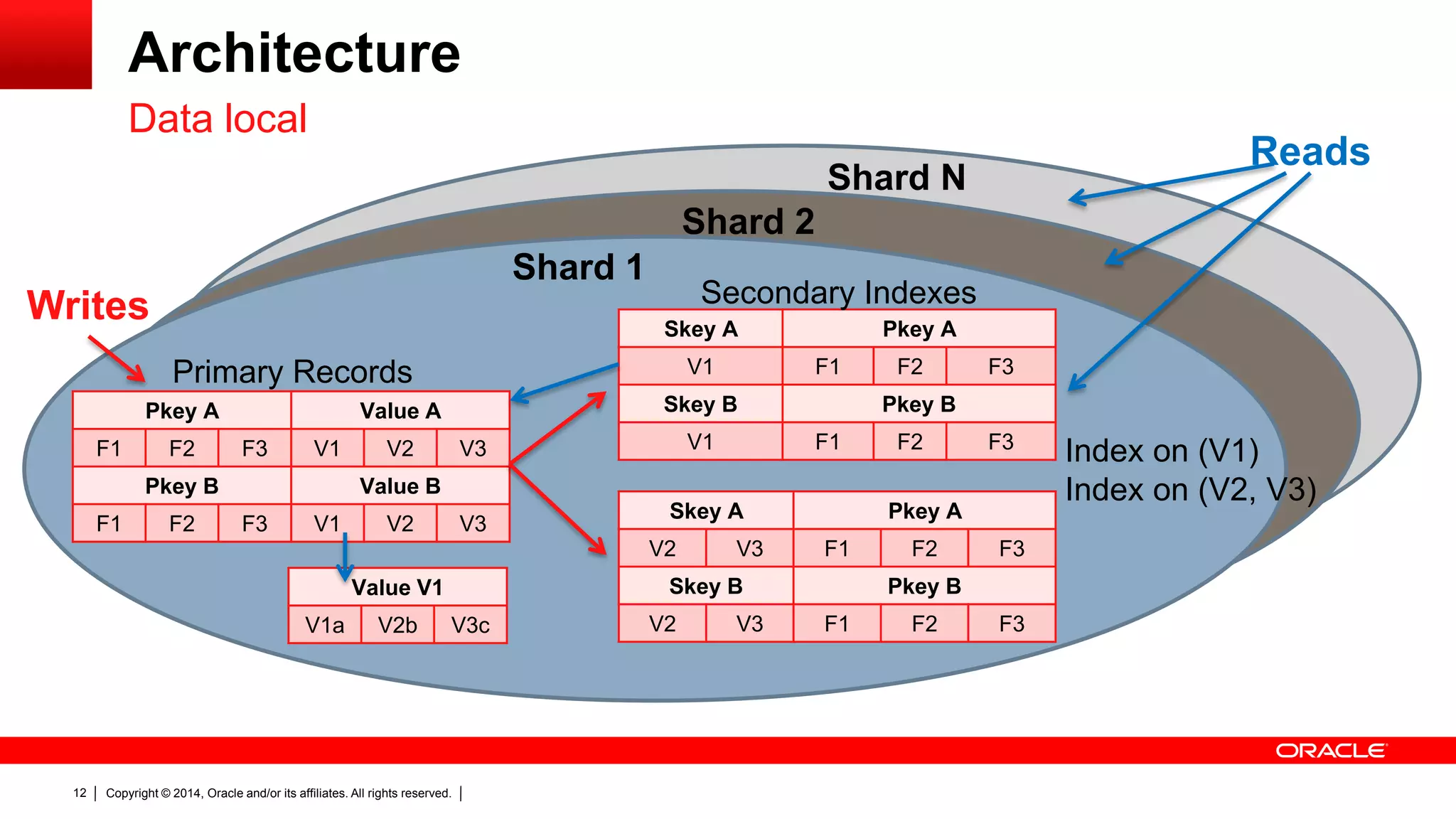

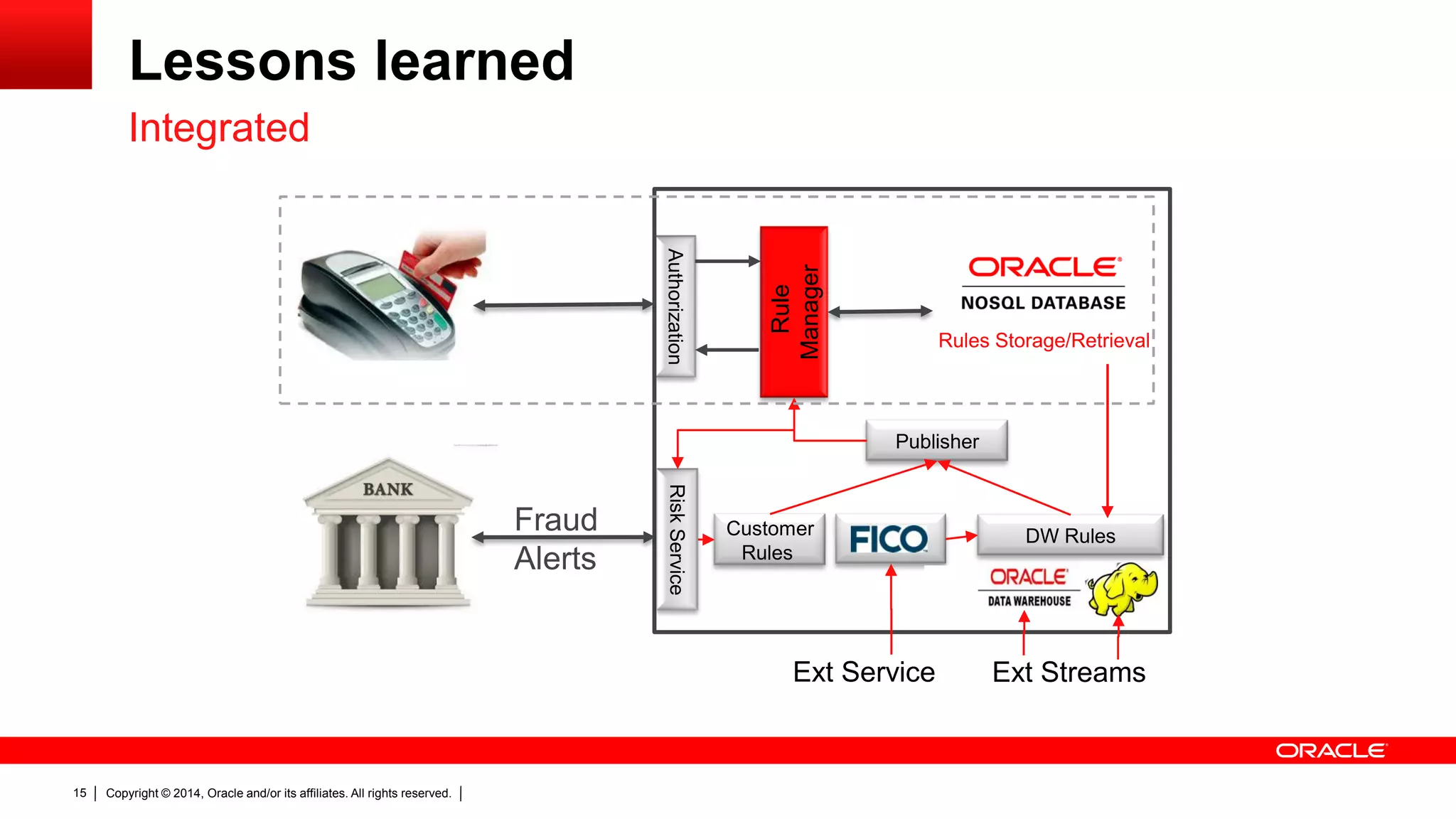




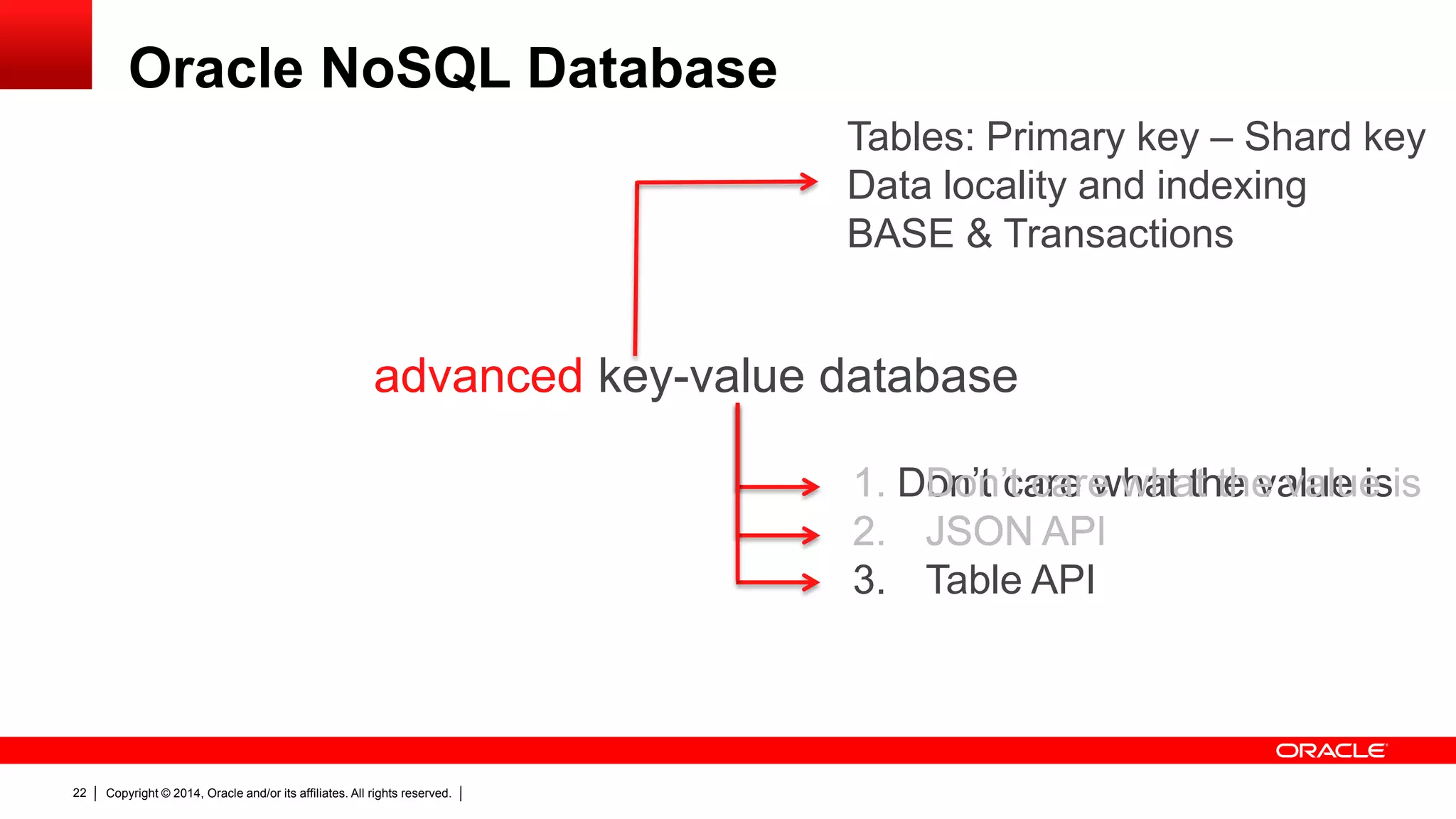



The document discusses Oracle's NoSQL database, focusing on modern data management workloads, system architecture, and lessons learned from application use cases. It highlights key architectural features like linear scaling, asynchronous processes, and the importance of data locality. The document also emphasizes the convergence of NoSQL features towards essential capabilities such as transactions, security, and ease of use.