Download as PDF, PPTX








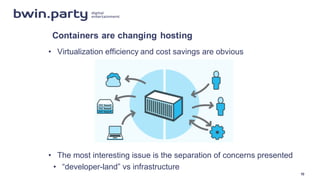



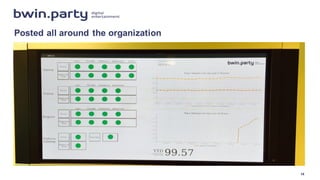



The document discusses the DevOps journey of a large online gaming company with separate sports betting and poker/casino divisions that were merged. It outlines the challenges of integrating different code bases and cultures. Key steps taken include adopting Agile, moving to Git/Jenkins, implementing monitoring with AppDynamics, and moving to containers. Automating testing environments and adopting continuous delivery principles helped improve quality and allow smaller, more frequent changes. Monitoring provided visibility and helped identify issues and refactoring needs. The changes helped bring development and operations teams together.
















































































