



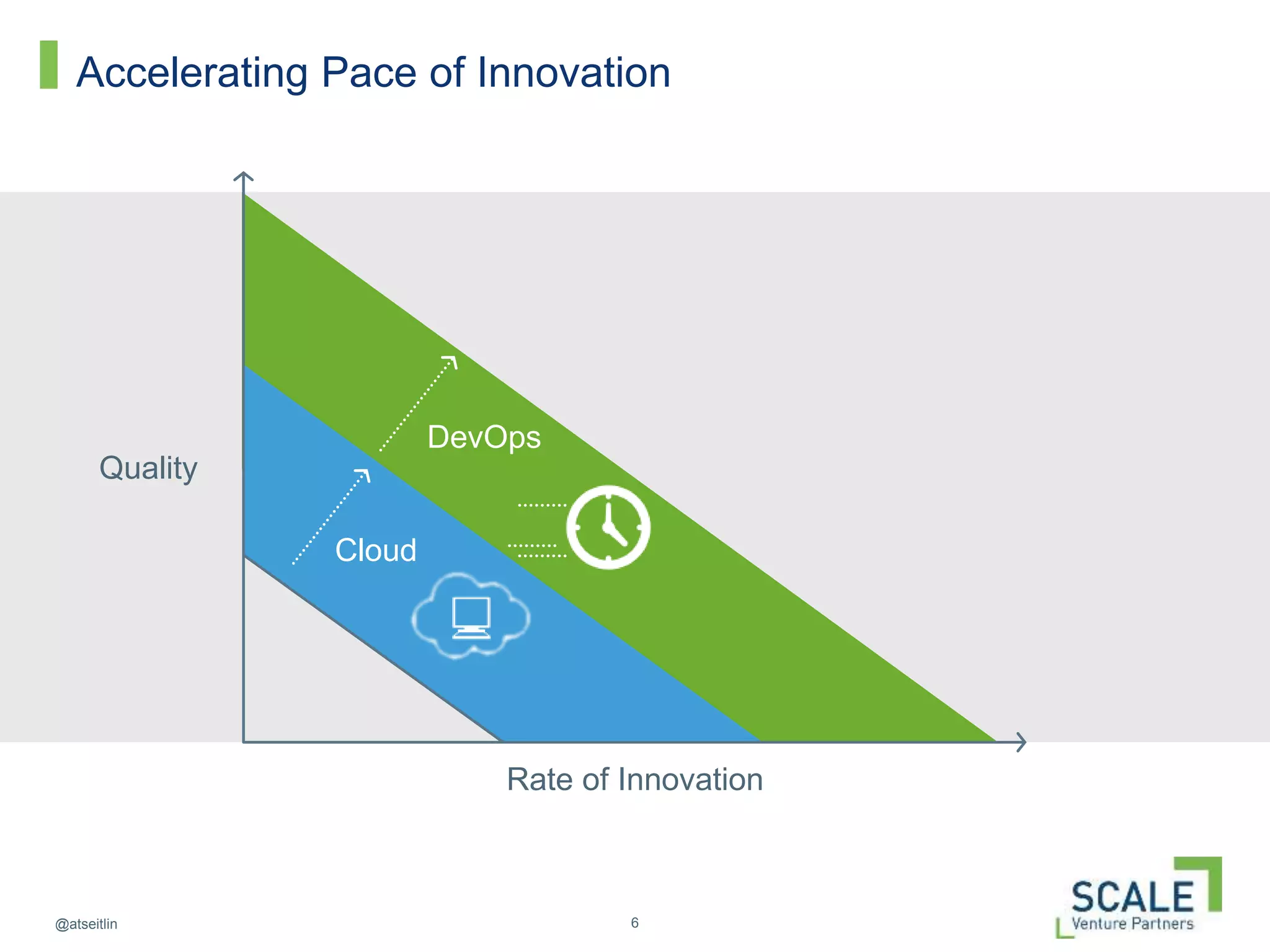

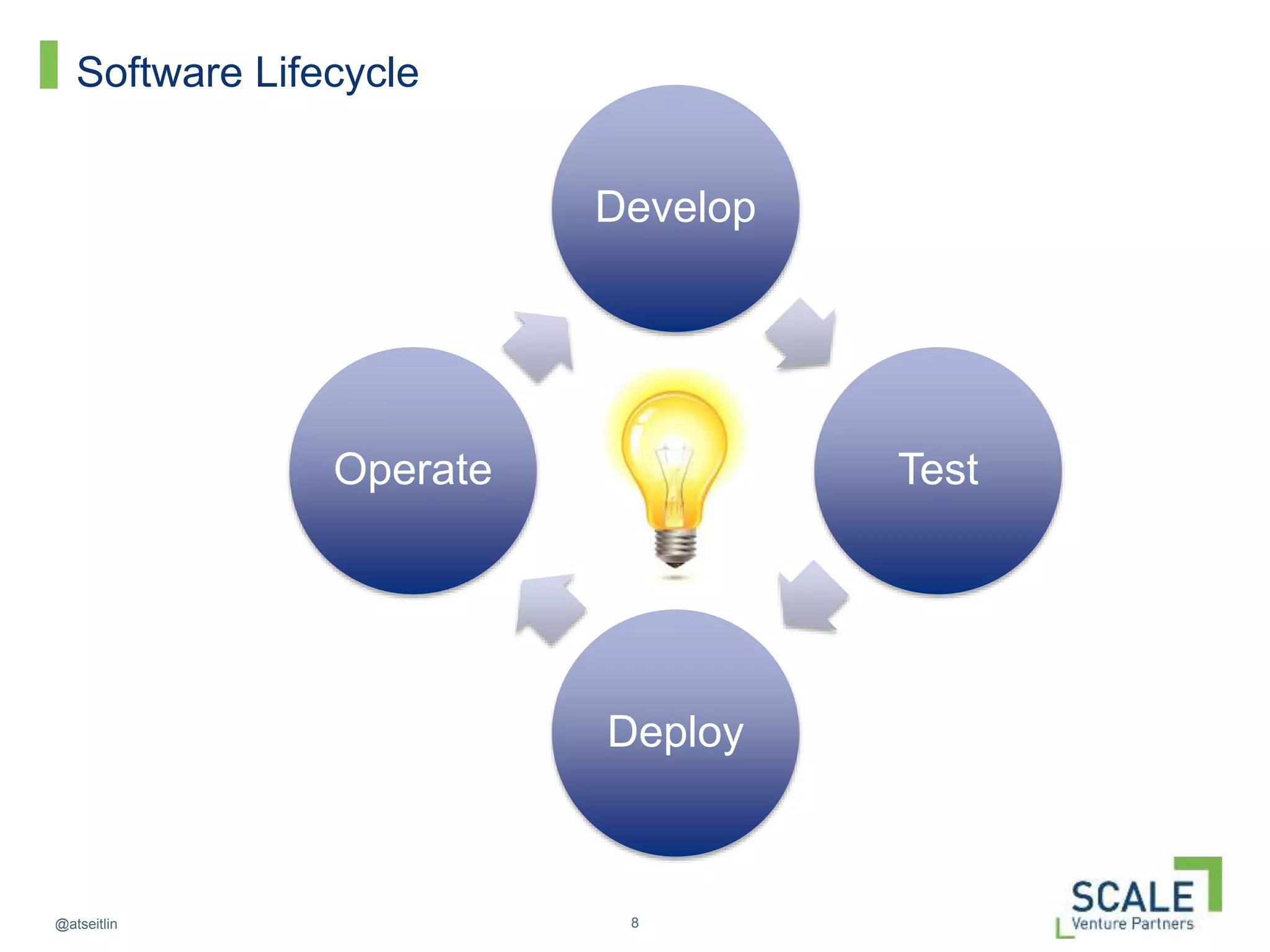




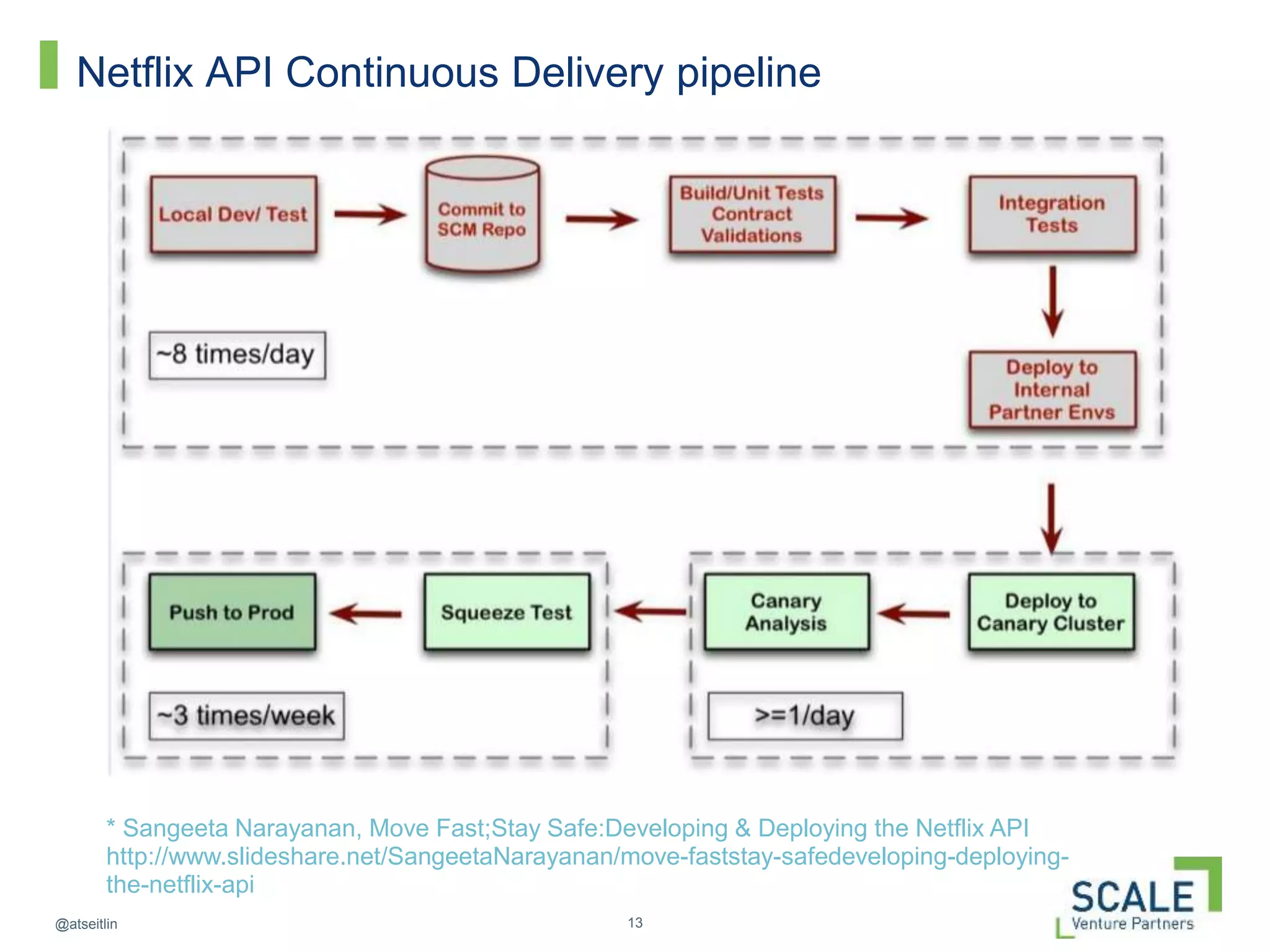




























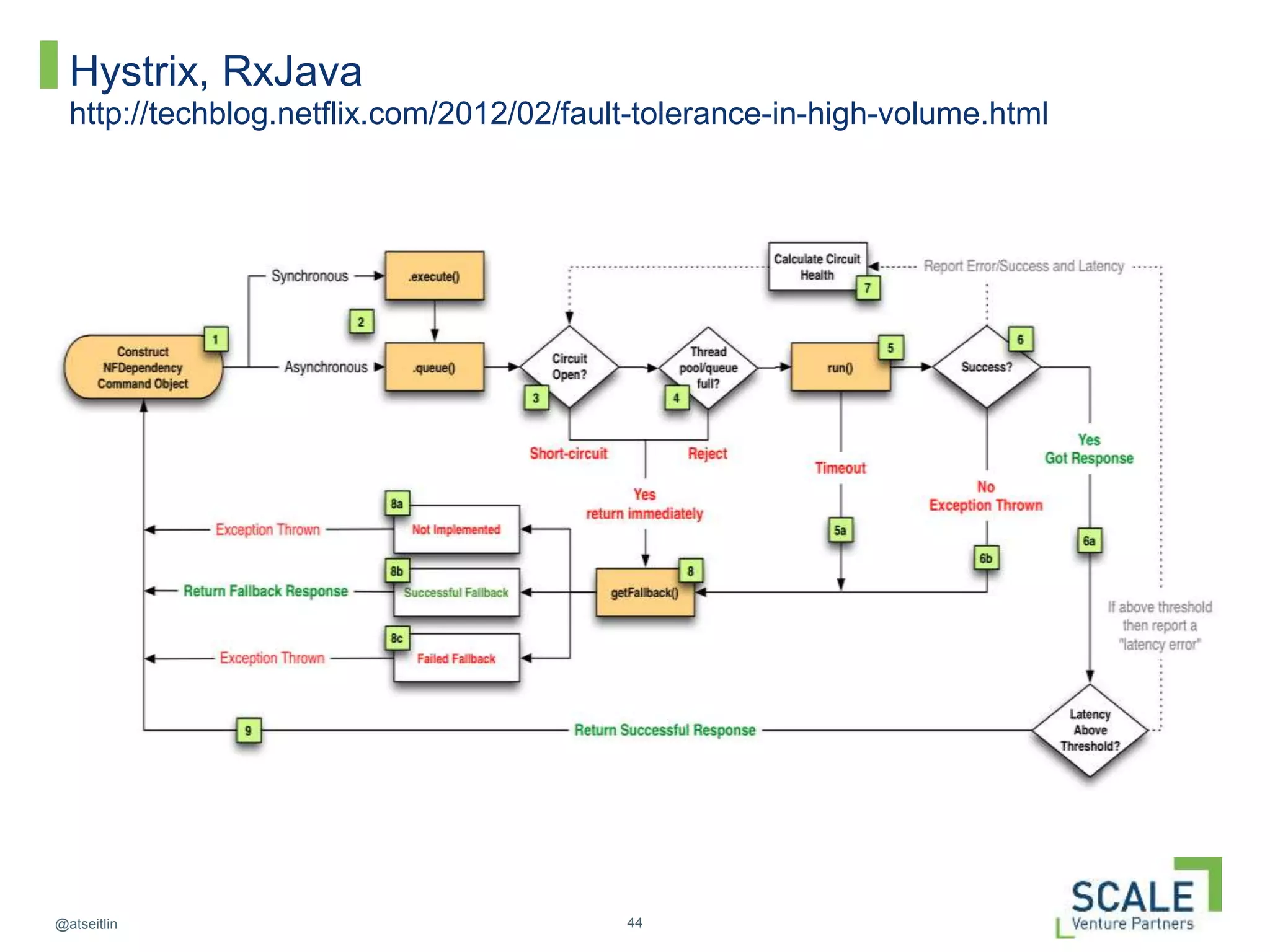

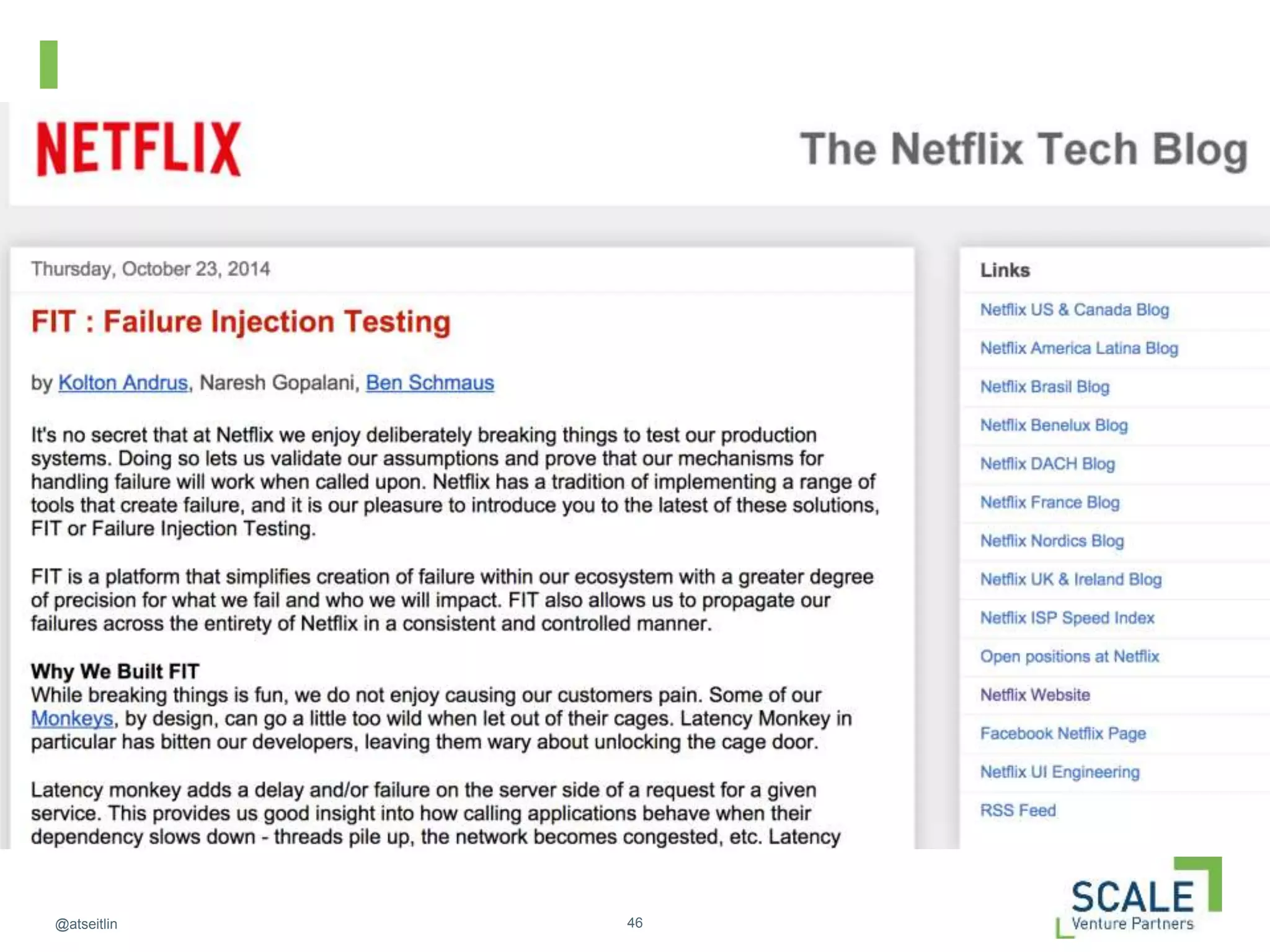










This document discusses how DevOps practices can help organizations accelerate innovation through software delivery. It outlines the core components of DevOps as self-service, automation, and collaboration. It then walks through the software development lifecycle from developing to operating software. Throughout, it emphasizes practices like continuous delivery, automated testing and configuration, zero-downtime deployments, monitoring, and designing systems to withstand failures using techniques like Netflix's "Chaos Monkey" which intentionally causes failures to test resiliency. The overall message is that DevOps can help organizations innovate faster by breaking down silos and automating the process of delivering high quality software.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















