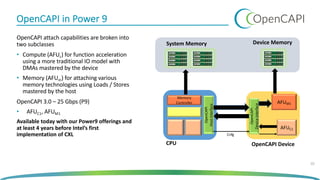
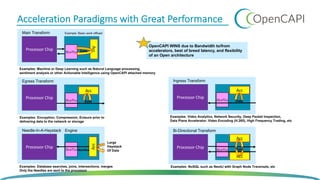
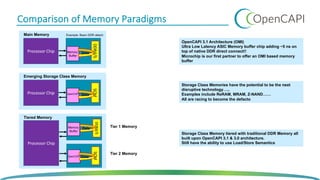
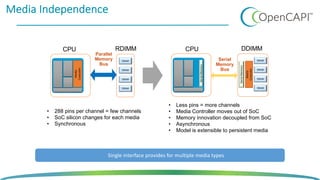
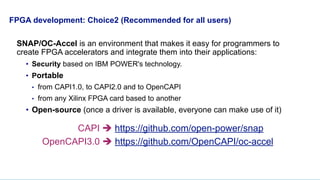
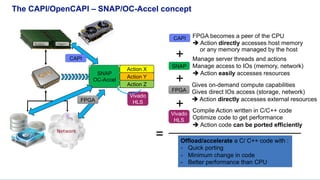
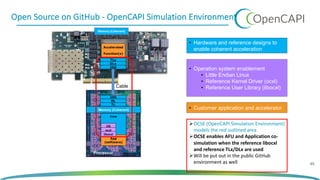
The document discusses OpenCAPI, an architectural advancement by IBM designed to improve data processing and memory management through high-bandwidth, low-latency connections for accelerators and memory. It highlights the challenges posed by rapid data growth and the limitations of traditional CPU and GPU architectures, advocating for the use of FPGA and other specialized hardware. Additionally, it outlines technical specifications, use cases, and the benefits of OpenCAPI in various computing environments, including details about available hardware solutions and programming frameworks.