Downloaded 10 times











![{
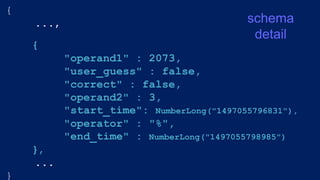
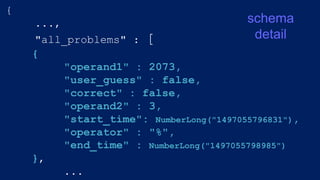
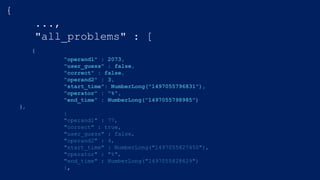
"all_problems" : [{
"operand1" : 14,
"correct" : true,
"user_guess" : false,
"operand2" : 5,
"start_time" : NumberLong("1497055834697"),
"operator" : "%",
"end_time" : NumberLong("1497055835953")
},
{
"operand1" : 24,
"correct" : true,
"user_guess" : true,
"operand2" : 2,
"start_time" : NumberLong("1497055828630"),
"operator" : "%",
"end_time" : NumberLong("1497055830491")
},
{
"operand1" : 69,
"correct" : true,
"user_guess" : false,
"operand2" : 2,
"start_time" : NumberLong("1497055824300"),
"operator" : "%",
"end_time" : NumberLong("1497055825997")
},
{
"operand1" : 26,
"correct" : true,
"user_guess" : false,
"operand2" : 5,
"start_time" : NumberLong("1497055796831"),
"operator" : "%",
"end_time" : NumberLong("1497055798985")
},
{
"operand1" : 67,
"correct" : true,
"user_guess" : false,
"operand2" : 2,
"start_time" : NumberLong("1497055814628"),
"operator" : "%",
"end_time" : NumberLong("1497055816652")
},
{
"operand1" : 31,
"correct" : true,
"user_guess" : false,
"operand2" : 4,
"start_time" : NumberLong("1497055802959"),
"operator" : "%",
"end_time" : NumberLong("1497055804802")
}
],
...](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-15-320.jpg)
![{
"_id" : ObjectId("593b42366523ec06eed182b9"),
"session_start" : NumberLong("1497055796716"),
"uuid" : "urn:uuid:55e72720-c0b1-4e81-89d6-ac1896b06661",
"subtopic" : "divisibility superpowers"
"all_problems" : [{
"operand1" : 14,
"correct" : true,
"user_guess" : false,
"operand2" : 5,
"start_time" : NumberLong("1497055834697"),
"operator" : "%",
"end_time" : NumberLong("1497055835953")
},
{
"operand1" : 24,
"correct" : true,
"user_guess" : true,
"operand2" : 2,
"start_time" : NumberLong("1497055828630"),
"operator" : "%",
"end_time" : NumberLong("1497055830491")
},
{
"operand1" : 69,
"correct" : true,
"user_guess" : false,
"operand2" : 2,
"start_time" : NumberLong("1497055824300"),
"operator" : "%",
"end_time" : NumberLong("1497055825997")
},
{
"operand1" : 26,
"correct" : true,
"user_guess" : false,
"operand2" : 5,
"start_time" : NumberLong("1497055796831"),
"operator" : "%",
"end_time" : NumberLong("1497055798985")
},
{
"operand1" : 67,
"correct" : true,
"user_guess" : false,
"operand2" : 2,
"start_time" : NumberLong("1497055814628"),
"operator" : "%",
"end_time" : NumberLong("1497055816652")
},
{
"operand1" : 31,
"correct" : true,
"user_guess" : false,
"operand2" : 4,
"start_time" : NumberLong("1497055802959"),
"operator" : "%",
"end_time" : NumberLong("1497055804802")
}
],](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-16-320.jpg)
![{
"_id" : ObjectId("593b42366523ec06eed182b9"),
"session_start" : NumberLong("1497055796716"),
"uuid" : "urn:uuid:55e72720-c0b1-4e81-89d6-ac1896b06661",
"subtopic" : "divisibility superpowers"
"all_problems" : [{
"operand1" : 14,
"correct" : true,
"user_guess" : false,
"operand2" : 5,
"start_time" : NumberLong("1497055834697"),
"operator" : "%",
"end_time" : NumberLong("1497055835953")
},
{
"operand1" : 24,
"correct" : true,
"user_guess" : true,
"operand2" : 2,
"start_time" : NumberLong("1497055828630"),
"operator" : "%",
"end_time" : NumberLong("1497055830491")
},
{
"operand1" : 69,
"correct" : true,
"user_guess" : false,
"operand2" : 2,
"start_time" : NumberLong("1497055824300"),
"operator" : "%",
"end_time" : NumberLong("1497055825997")
},
{
"operand1" : 26,
"correct" : true,
"user_guess" : false,
"operand2" : 5,
"start_time" : NumberLong("1497055796831"),
"operator" : "%",
"end_time" : NumberLong("1497055798985")
},
{
"operand1" : 67,
"correct" : true,
"user_guess" : false,
"operand2" : 2,
"start_time" : NumberLong("1497055814628"),
"operator" : "%",
"end_time" : NumberLong("1497055816652")
},
{
"operand1" : 31,
"correct" : true,
"user_guess" : false,
"operand2" : 4,
"start_time" : NumberLong("1497055802959"),
"operator" : "%",
"end_time" : NumberLong("1497055804802")
}
],](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-17-320.jpg)
![{
"_id" : ObjectId("593b42366523ec06eed182b9"),
"session_start" : NumberLong("1497055796716"),
"uuid" : "urn:uuid:55e72720-c0b1-4e81-89d6-ac1896b06661",
"subtopic" : "divisibility superpowers"
"all_problems" : [{
"operand1" : 14,
"correct" : true,
"user_guess" : false,
"operand2" : 5,
"start_time" : NumberLong("1497055834697"),
"operator" : "%",
"end_time" : NumberLong("1497055835953")
},
{
"operand1" : 24,
"correct" : true,
"user_guess" : true,
"operand2" : 2,
"start_time" : NumberLong("1497055828630"),
"operator" : "%",
"end_time" : NumberLong("1497055830491")
},
{
"operand1" : 69,
"correct" : true,
"user_guess" : false,
"operand2" : 2,
"start_time" : NumberLong("1497055824300"),
"operator" : "%",
"end_time" : NumberLong("1497055825997")
},
{
"operand1" : 26,
"correct" : true,
"user_guess" : false,
"operand2" : 5,
"start_time" : NumberLong("1497055796831"),
"operator" : "%",
"end_time" : NumberLong("1497055798985")
},
{
"operand1" : 67,
"correct" : true,
"user_guess" : false,
"operand2" : 2,
"start_time" : NumberLong("1497055814628"),
"operator" : "%",
"end_time" : NumberLong("1497055816652")
},
{
"operand1" : 31,
"correct" : true,
"user_guess" : false,
"operand2" : 4,
"start_time" : NumberLong("1497055802959"),
"operator" : "%",
"end_time" : NumberLong("1497055804802")
}
],](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-18-320.jpg)



![from pymongo import MongoClient
# SET UP THE CONNECTION
client = MongoClient("localhost", 27017)
db = client["aprender"]
mathcards = client["mathcards"]
users = client["users"]
collections](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-22-320.jpg)
![from pymongo import MongoClient
from secure import MONGO_USERNAME, MONGO_PASSWORD
# SET UP THE CONNECTION
client = MongoClient("localhost", 27017)
db = client["aprender"]
mathcards = client["mathcards"]
users = client["users"]
# AUTHENTICATE THE CONNECTION
client.aprender.authenticate(MONGO_USERNAME,
MONGO_PASSWORD,
mechanism='SCRAM-SHA-1')](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-23-320.jpg)
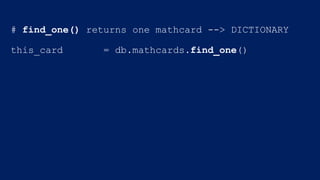
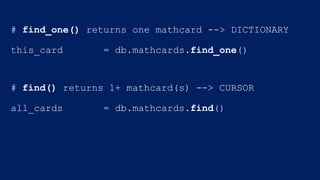
![# find_one() returns one mathcard --> DICTIONARY
this_card = db.mathcards.find_one()
# find() returns 1+ mathcard(s) --> CURSOR
all_cards = db.mathcards.find()
for card in all_cards:
for key in card.keys():
problem_data = card[key]
do_some_stuff(problem_data)](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-26-320.jpg)


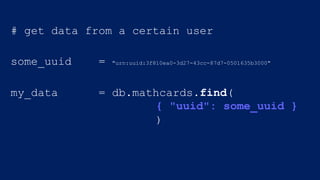
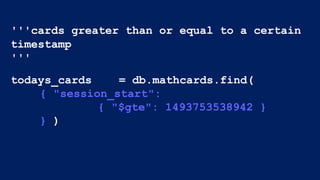


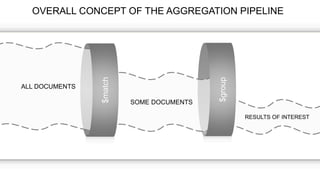
![$match example
pipeline1 = [
{"$match": { "session_start": { "$gte":
this_morning } } },
]
name of key criteria](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-36-320.jpg)


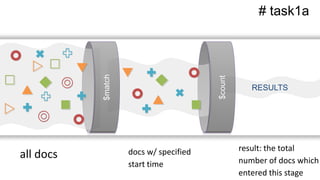
![$count example
pipeline1a = [
{"$match": { "session_start": { "$gte":
this_morning } } },
{"$count": "total_sessions_today" }
]
# task1a](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-39-320.jpg)
![$project example
pipeline1b = [
{"$match": { "session_start": { "$gte":
this_morning } } },
{"$project": {"session_start": 1}}
]
# task1b
name of key
display flag](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-40-320.jpg)
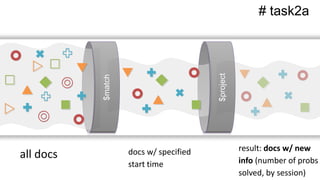
![$project
pipeline2a = [
{"$match": { "session_start": { "$gte":
this_morning } } },
{"$project": {"session_probs" :
{"$size": "$___________"} } }
]
# task2a](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-41-320.jpg)
![$project
pipeline2a = [
{"$match": { "session_start": { "$gte":
this_morning } } },
{"$project": {"session_probs" :
{"$size": "$___________"} } }
]
# task2a
name of the list of problems](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-42-320.jpg)
![$project
pipeline2a = [
{"$match": { "session_start": { "$gte":
this_morning } } },
{"$project": {"session_probs" :
{"$size": "$all_problems"} } }
]
# task2a
$all_problems](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-43-320.jpg)
![$group
pipeline2b = [
{"$match" : {"session_start" : {"$gte" :
this_morning } } },
{"$project" : {"session_probs" : {"$size" :
"$all_problems"} } },
{"$group" : {
"_id" : None,
"total_problems" : {"$sum" :
"_____________"}
}}
]
# task2b](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-44-320.jpg)
![$group
pipeline2b = [
{"$match" : {"session_start" : {"$gte" :
this_morning } } },
{"$project" : {"session_probs" : {"$size" :
"$all_problems"} } },
{"$group" : {
"_id" : None,
"total_problems" : {"$sum" :
"$session_probs"}
}}
]
# task2b](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-45-320.jpg)
![$group
pipeline2b = [
{"$project" : {"session_probs" : {"$size" :
"$all_problems"} } },
{"$group" : {
"_id" : None,
"total_problems" : {"$sum" :
"$session_probs"}
}}
]
# task3](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-46-320.jpg)
![$avg
pipeline4 = [
{"$match" : {"session_start" : {"$gte" : this_morning } } },
{"$project" : {"session_probs" : {"$size" : "$all_problems"} } },
{"$group" : {
"_id" : None,
"avg_num_probs" : {"______": "__________"}
}}
]
# task4
?](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-47-320.jpg)
![$avg
pipeline4 = [
{"$match" : {"session_start" : {"$gte" : this_morning } } },
{"$project" : {"session_probs" : {"$size" : "$all_problems"} } },
{"$group" : {
"_id" : None,
"avg_num_probs" : {"$avg": "$session_probs"}
}}
]
# task4](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-48-320.jpg)
![$stdDevSamp
pipeline4 = [
{"$match" : {"session_start" : {"$gte" : this_morning } } },
{"$project" : {"session_probs" : {"$size" : "$all_problems"} } },
{"$group" : {
"_id" : None,
"std_dev_num_probs" :
{"_________": "_________"}
}}
]
# task5
?](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-49-320.jpg)
![$stdDevSamp
pipeline4 = [
{"$match" : {"session_start" : {"$gte" : this_morning } } },
{"$project" : {"session_probs" : {"$size" : "$all_problems"} } },
{"$group" : {
"_id" : None,
"std_dev_num_probs" :
{"$stdDevSamp": "$session_probs"}
}}
]
# task5](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-50-320.jpg)

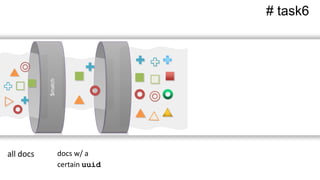
![Multi-stage aggregation pipelines
task6: Response time by operand2 [2,3,4,5,6,9] for one user
task7: Percent accuracy (“score”) by operand2 for one user
task8: Retrieve, for one user, operand2 w/ lowest score
task9: Retrieve, for one user, operand2 w/ fastest time
task10: Retrieve operand2 which challenged the most users](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-52-320.jpg)

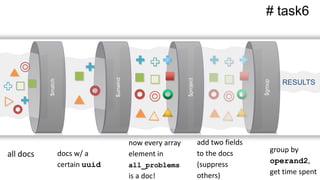
![$unwind # task6
pipeline6 = [
{ "$match" : # $match on uuid_of_interest
{ "$unwind" : # $unwind array of problems
{ "$project": {
"operand2": # use dot notation
"time_spent": # compute time spent
},
{ "$group":{
"_id": # group on operand2
"avg_time_spent": # compute $avg
}
}
]](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-60-320.jpg)
![$unwind # task6pipeline6 = [
{ "$match" : {"uuid" : uuid_of_interest } },
{ "$unwind" : "$all_problems" },
{ "$project": {
"operand2": "$all_problems.operand2",
"time_spent": {"$subtract": ["$all_problems.end_time",
"$all_problems.start_time"]},
"session_start":1,
"_id":0}
},
{ "$group":{
"_id": {"operand2": "$operand2"},
"avg_time_spent": {"$avg": "$time_spent"},
}
}
]](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-61-320.jpg)
![$addFields # task7
pipeline7a = [
{ "$match" : ...
{ "$unwind" : ...
{ "$group":{
"_id": # $group on operand2
"total_attempted": # $sum
"total_correct":
}
},
{ "$addFields":{
"percent_accuracy":
}
}
]](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-62-320.jpg)
![$group for task7 # task7
{"$group":{
"_id": "$all_problems.operand2",
"total_attempted": {"$sum":1},
"total_correct":
{"$sum": { "$cond":
["$all_problems.correct", 1, 0]
} }
}
}](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-63-320.jpg)
![$addFields for task7 # task7
{"$addFields":{
"percent_accuracy": {"$divide":
["$total_correct",
"$total_attempted"]
}
}
}](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-64-320.jpg)

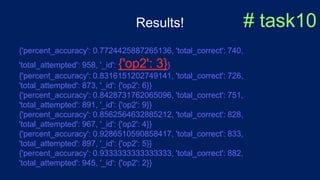
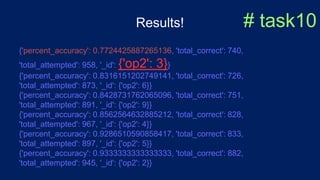
![$sort and $limit # task8
pipeline7.extend([
{"$sort": {"percent_accuracy": 1}},
{"$limit": 1}
])](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-66-320.jpg)

![$sort and $limit # task9
pipeline6.extend([
{"$sort":
{"avg_time_spent": 1}},
{"$limit": 1}
]}](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-68-320.jpg)








![$cond
{"$cond":{
"if": {"$and":[ {"$eq": ["$$nth.label", "tryHarder"]},
{"$eq": ["$$nth.user_response", "yes"]},
{"$eq": ["$$nplus1.label", "tryHarder"]},
{"$eq": ["$$nplus1.user_response", "yes"]}
]},
"then": True,
"else": False
}}](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-79-320.jpg)
![$cond
{"$cond":{
"if": {"$and":[ {"$eq": ["$$nth.label", "tryHarder"]},
{"$eq": ["$$nth.user_response", "yes"]},
{"$eq": ["$$nplus1.label", "tryHarder"]},
{"$eq": ["$$nplus1.user_response", "yes"]}
]},
"then": True,
"else": False
}}](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-80-320.jpg)
![{"$eq": ["$$nth.label", "tryHarder"]},
{"$eq": ["$$nth.user_response", "yes"]},
{"$eq": ["$$nplus1.label", "tryHarder"]},
{"$eq": ["$$nplus1.user_response", "yes"]}
$eq](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-81-320.jpg)
![{"$and": [ {},{},{},{} ]}
$and](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-82-320.jpg)
![{
"_id" : ObjectId("593b42366523ec06eed182b9"),
"session_start" : NumberLong("1497055796716"),
"uuid" : "urn:uuid:55e72720-c0b1-4e81-89d6-ac1896b06661",
"subtopic" : "divisibility superpowers"
"all_problems" : [...],
"interventions" : [
{
"deploy_time" : NumberLong("1497055817986"),
"label" : "tryHarder",
"user_response" : "no",
"dismiss_time" : 2939
}
}
71](https://image.slidesharecdn.com/crystalcday21540-1710robynallentutorial-170623161003/85/Building-Your-First-Data-Science-Applicatino-in-MongoDB-83-320.jpg)


The document outlines the development of a data science app focused on improving math literacy for students using MongoDB and PyMongo. It details the motivation behind the app, the database schema, and various queries to analyze student performance and engagement with math problems. Additionally, it provides coding examples and explanations of MongoDB operations such as data retrieval and aggregation pipelines.






















































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)


























![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




