Downloaded 27 times





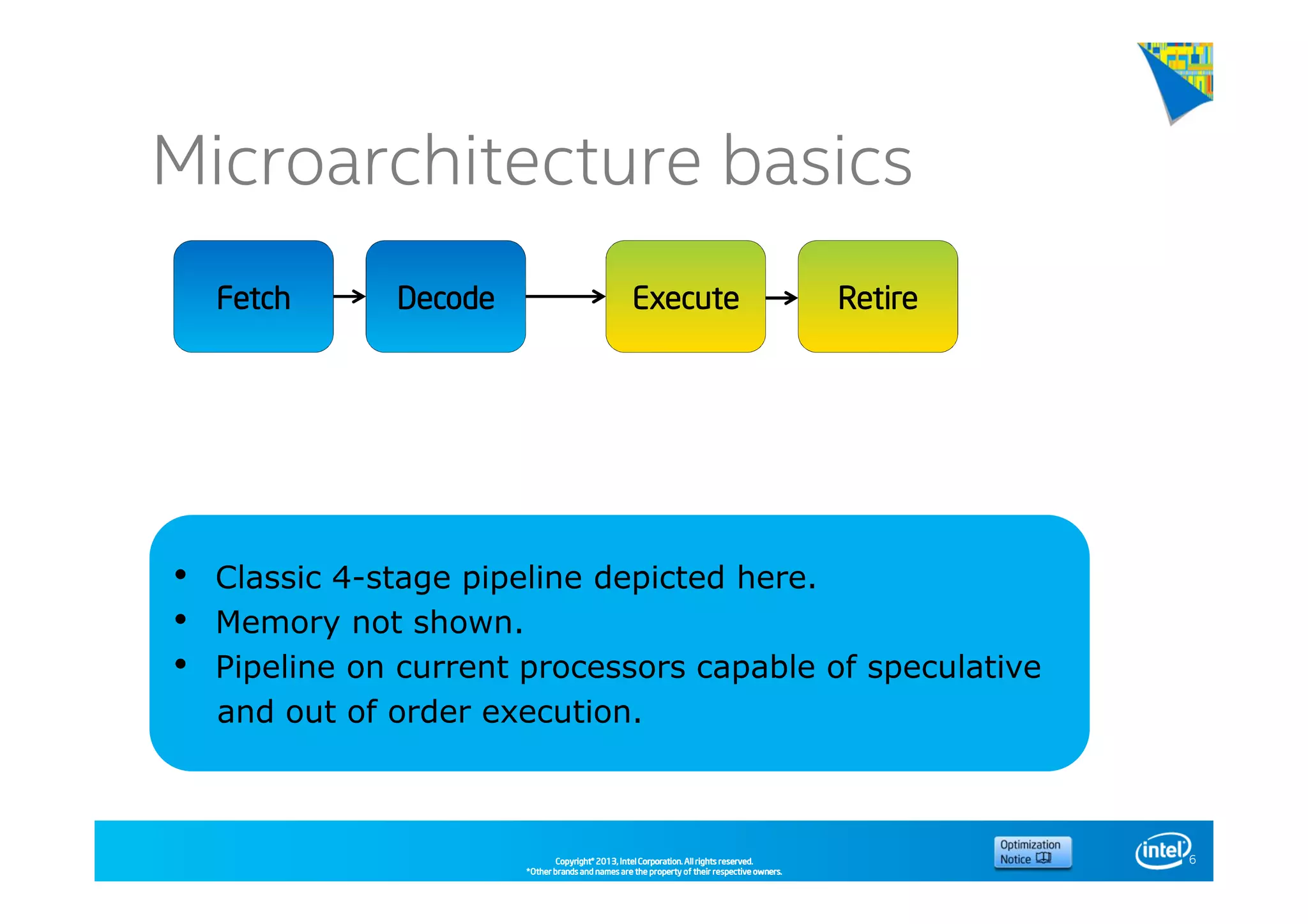

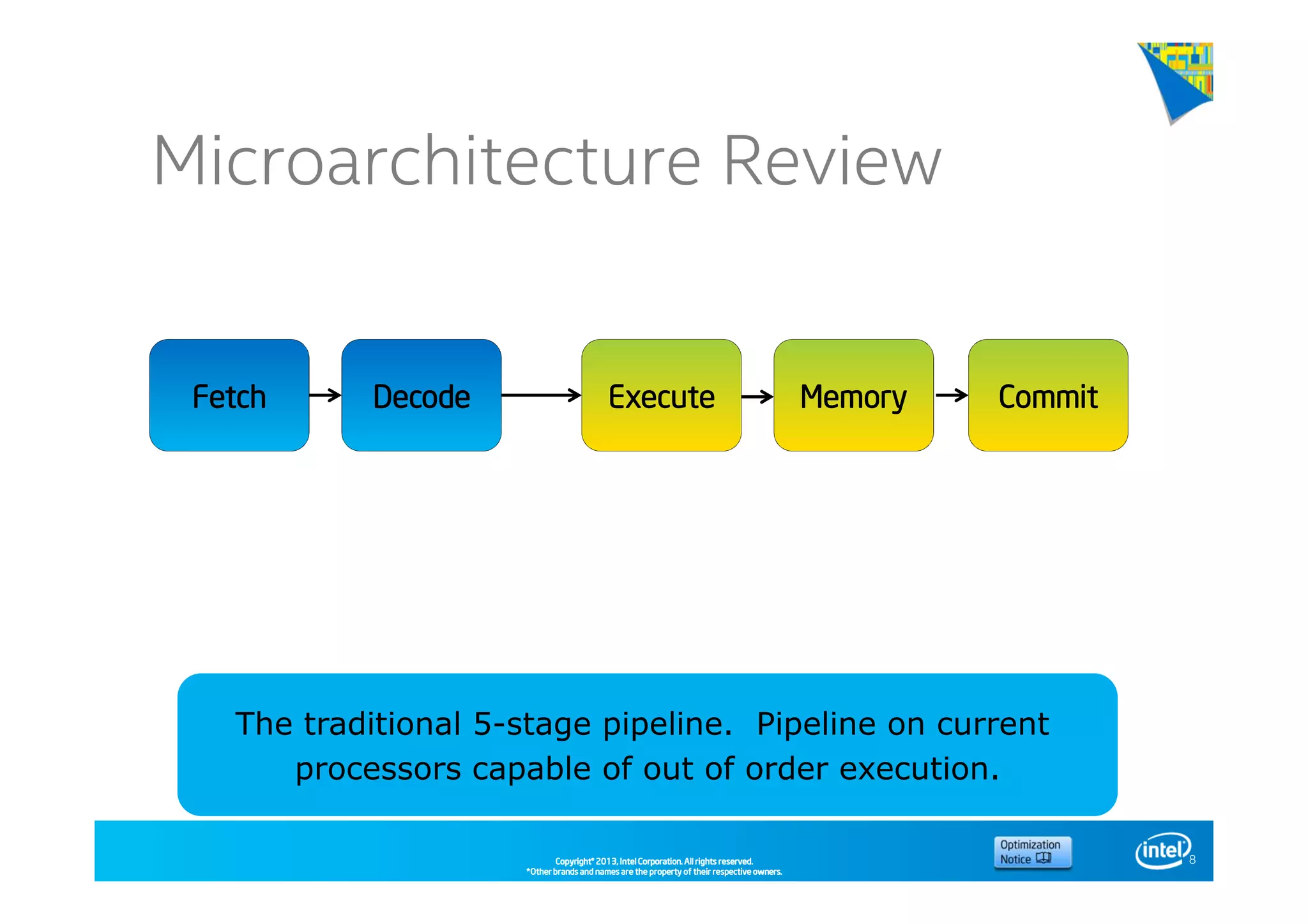
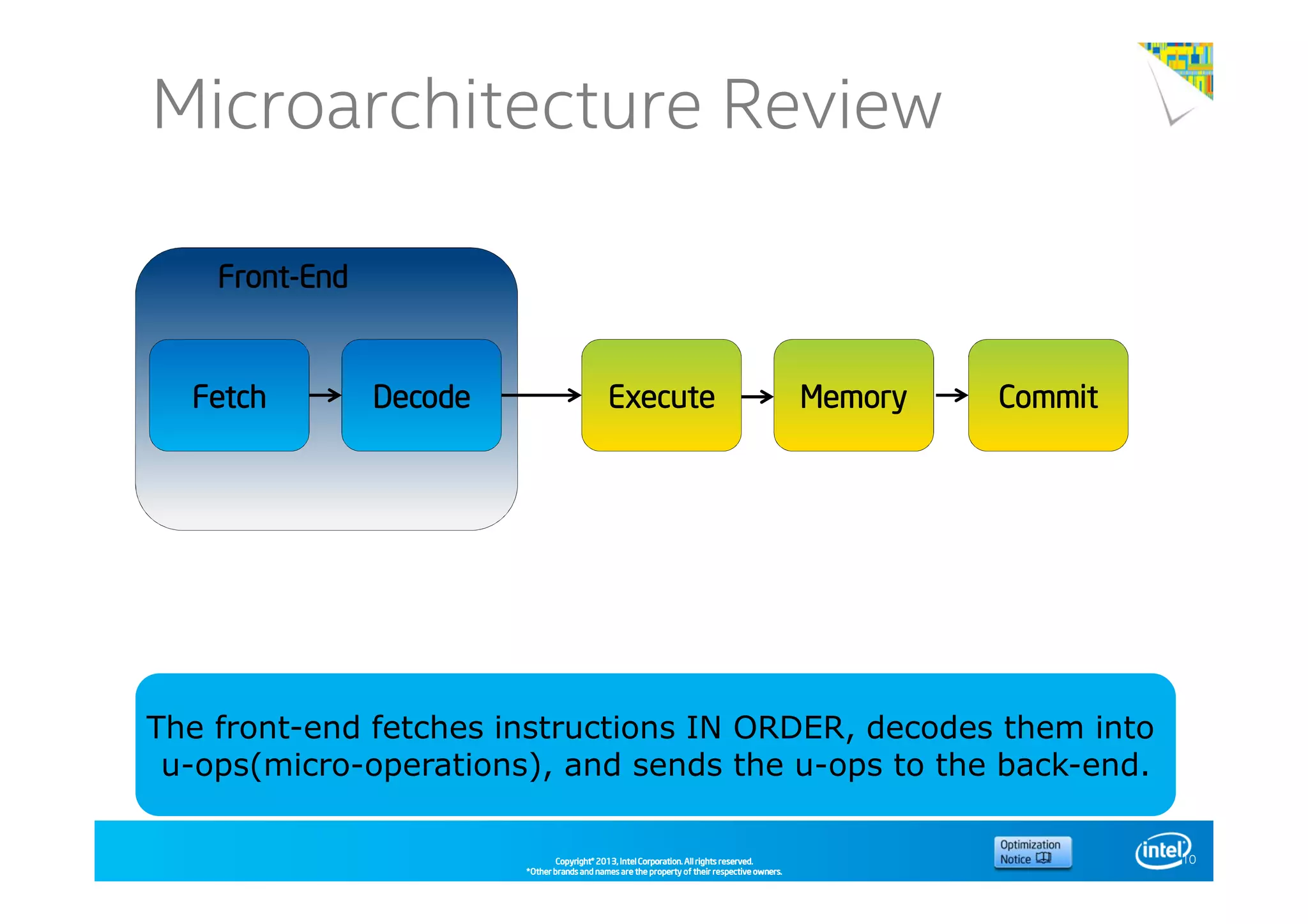
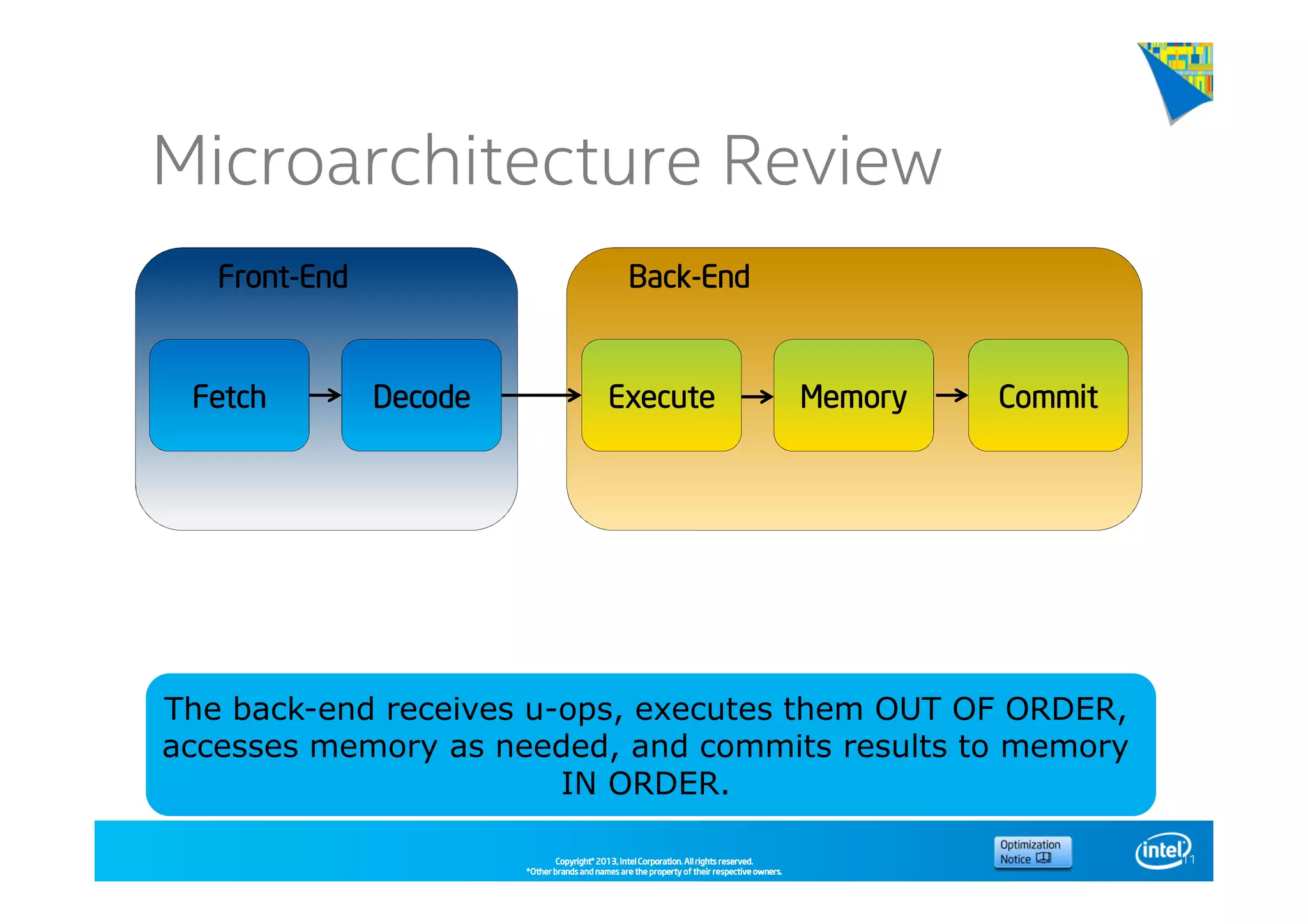
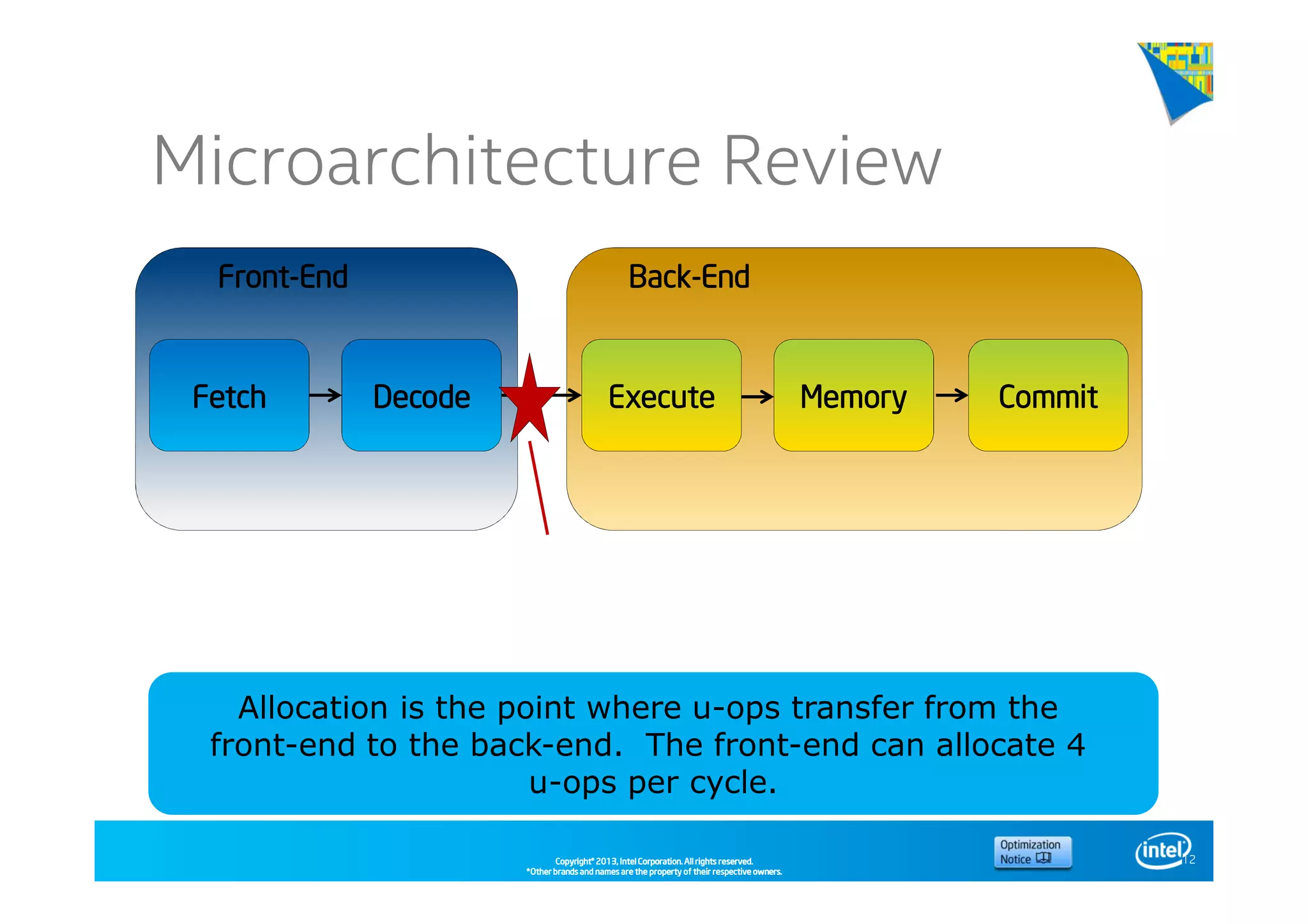
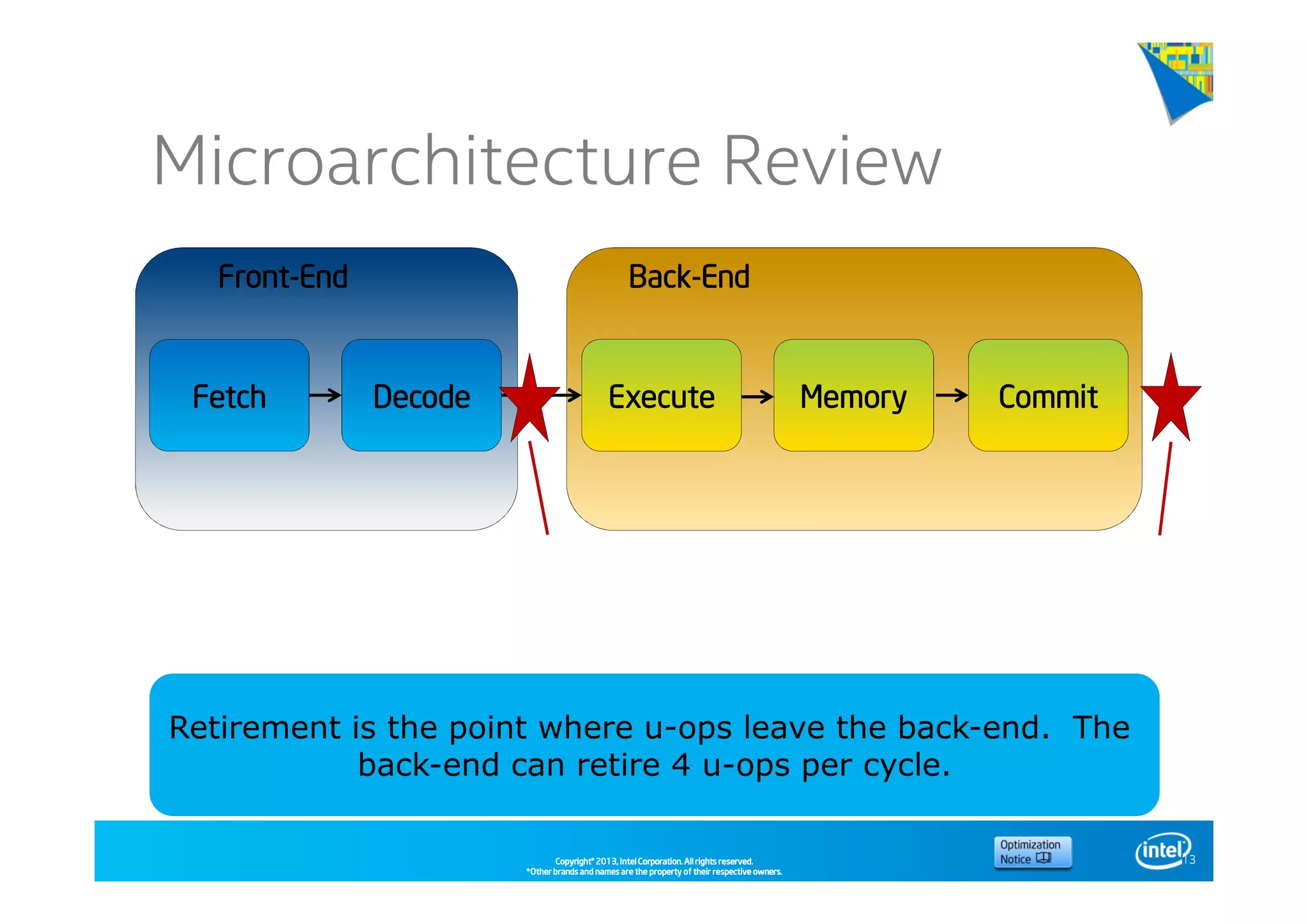
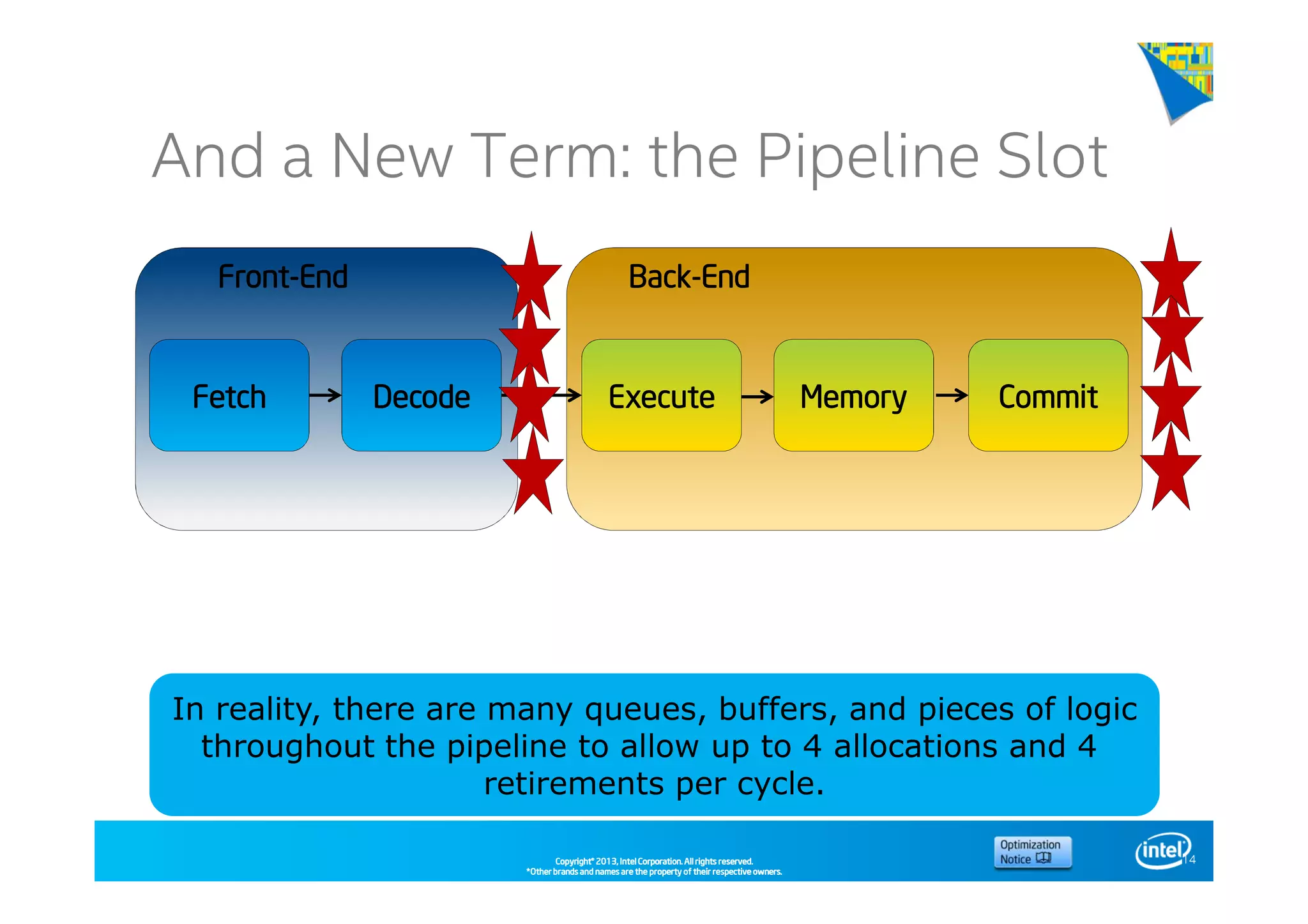
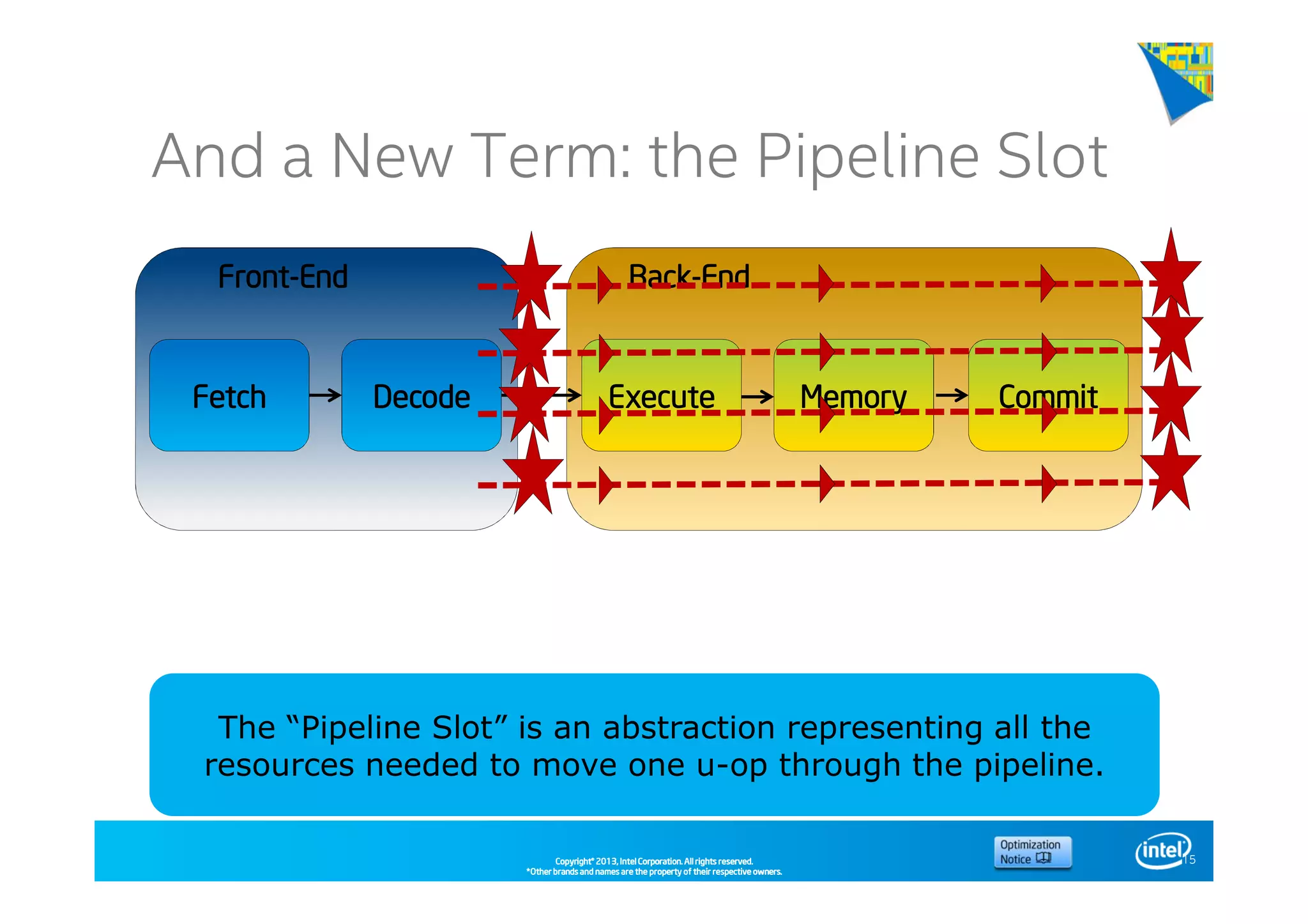
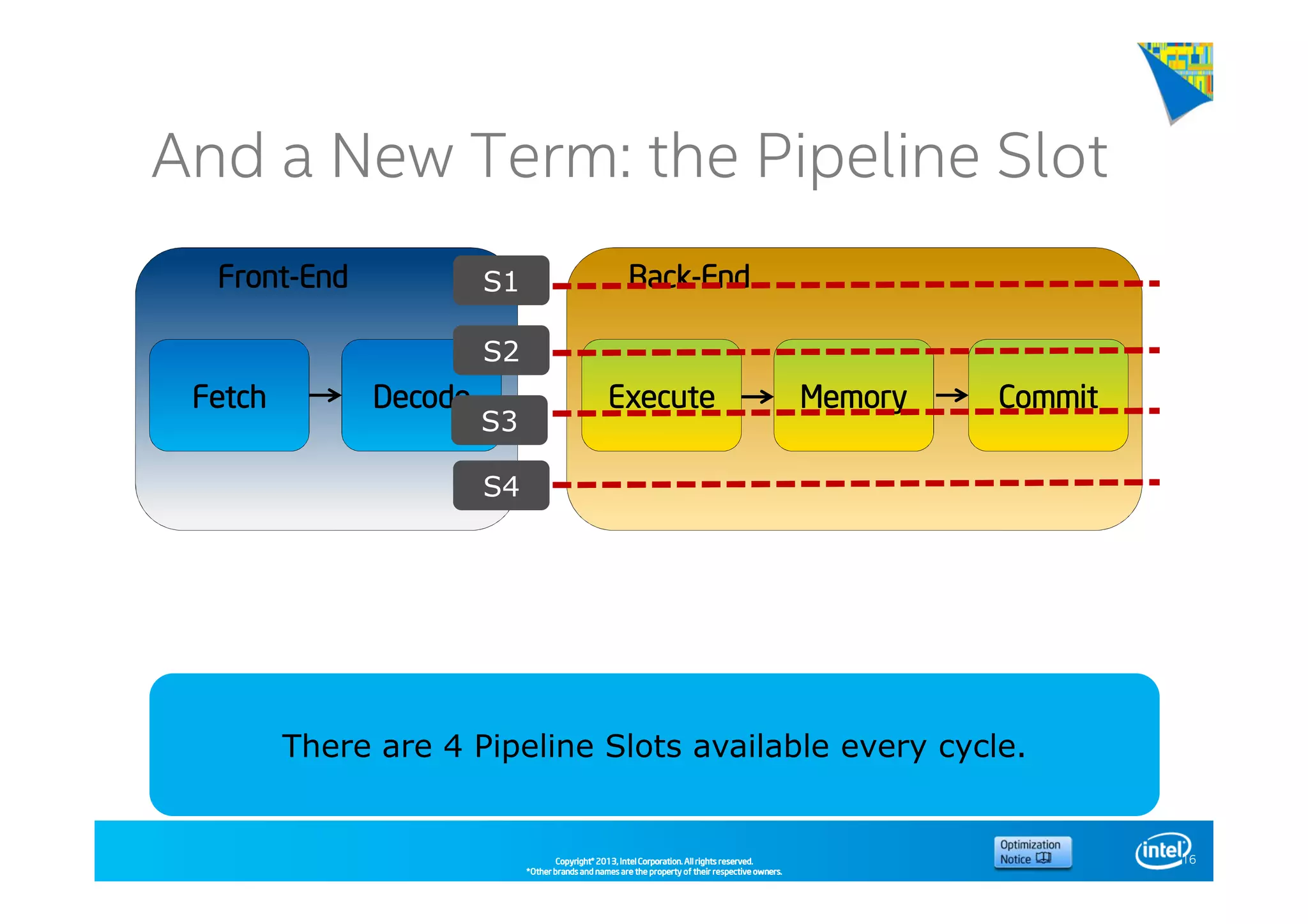
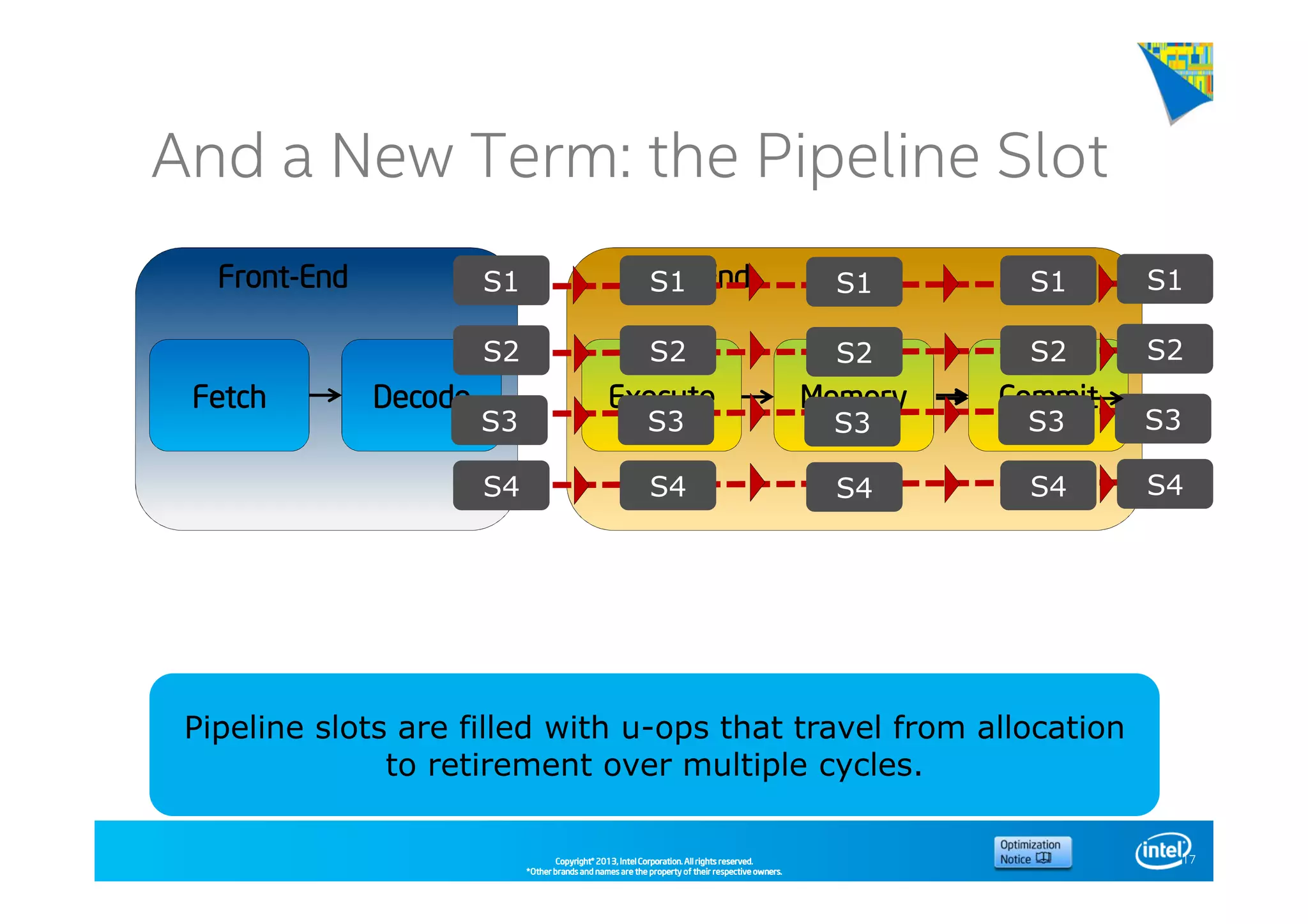

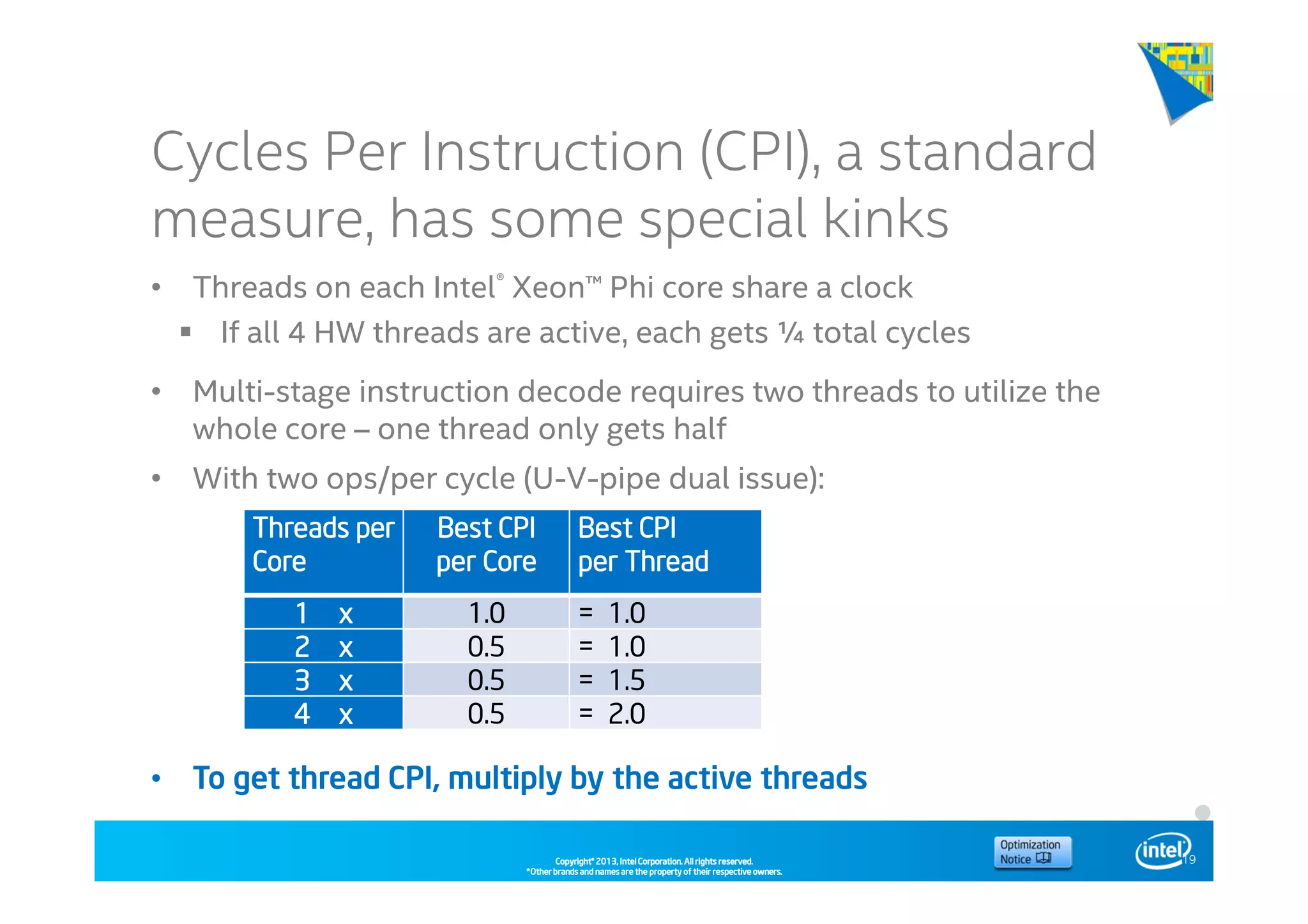

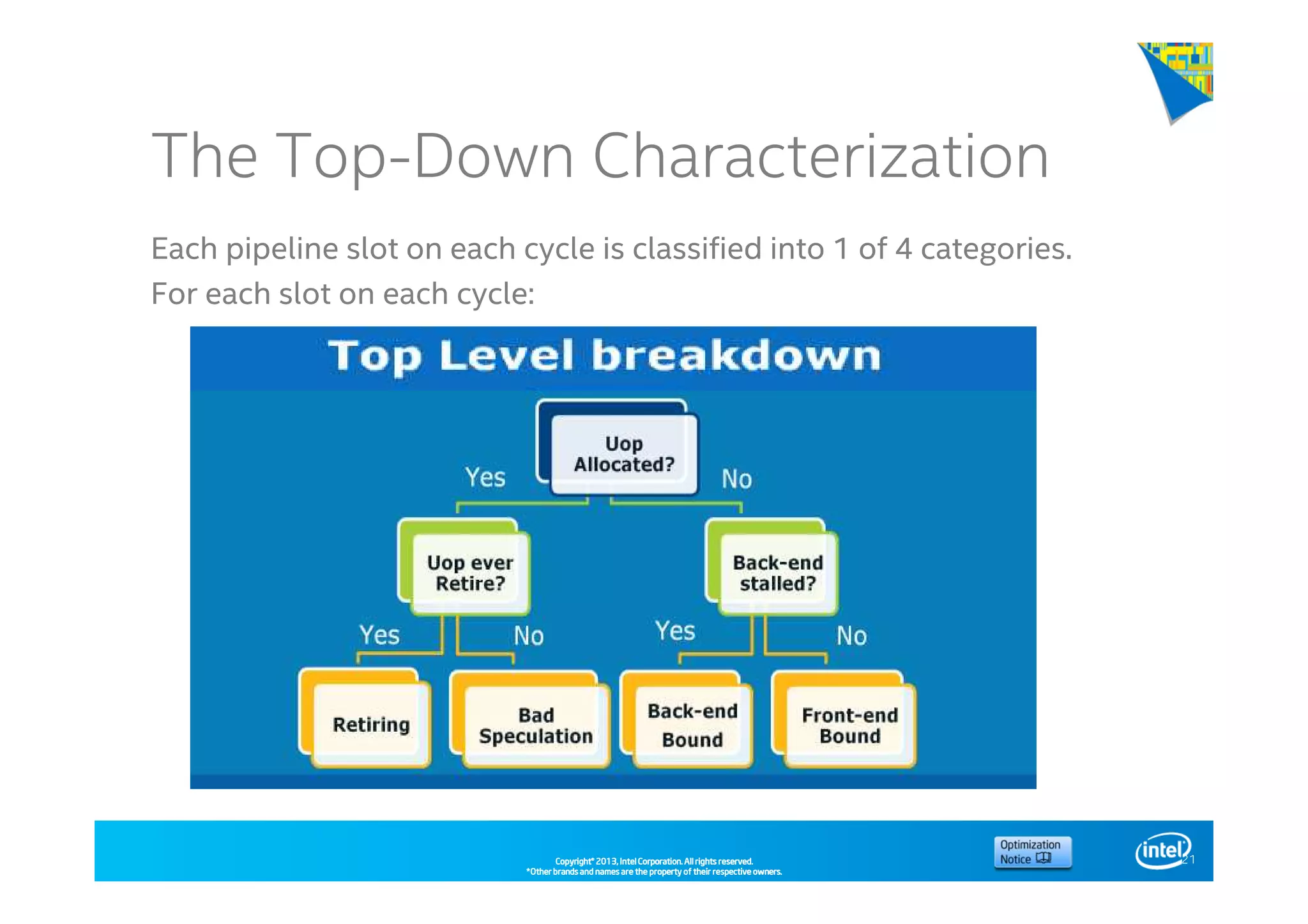

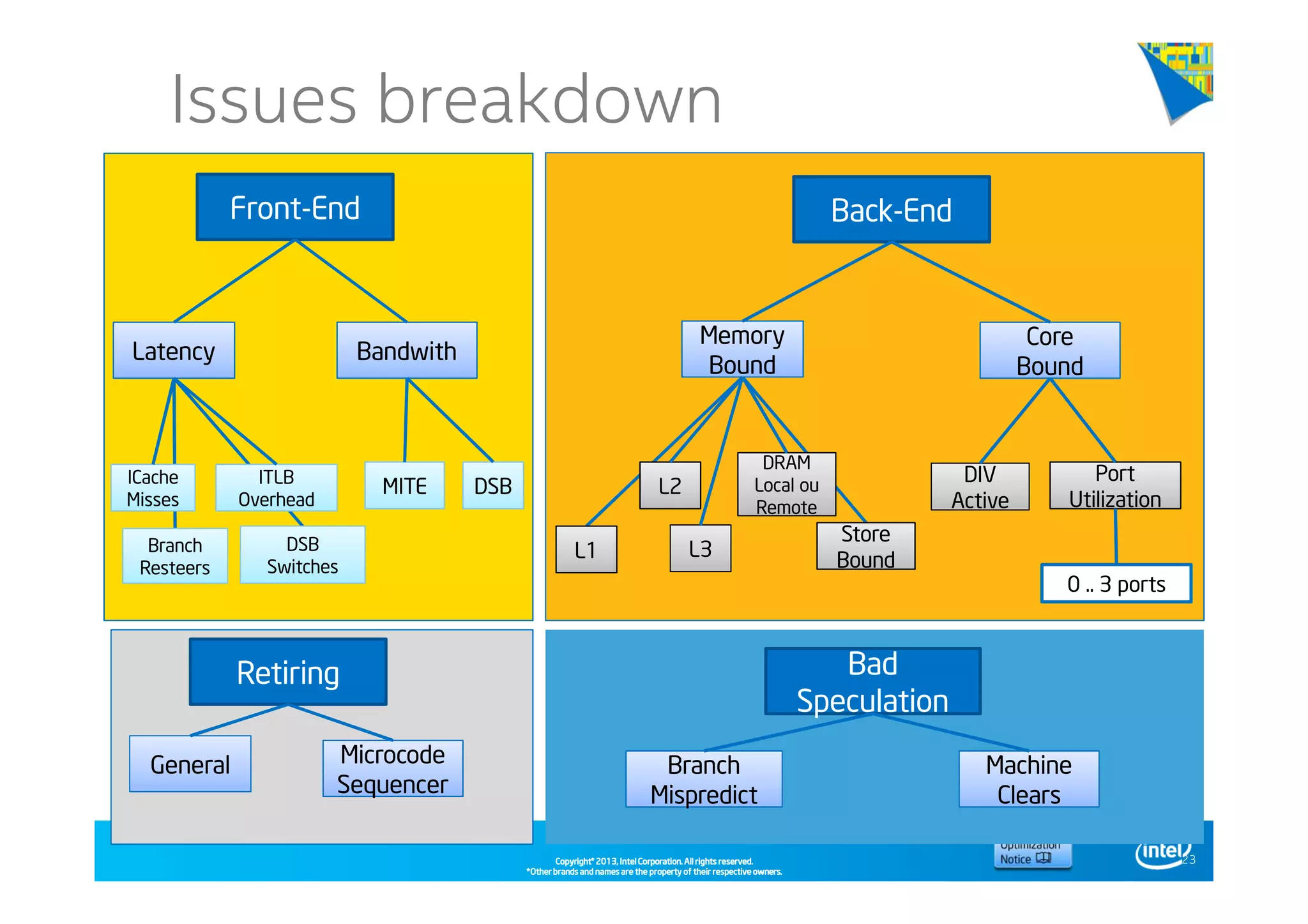

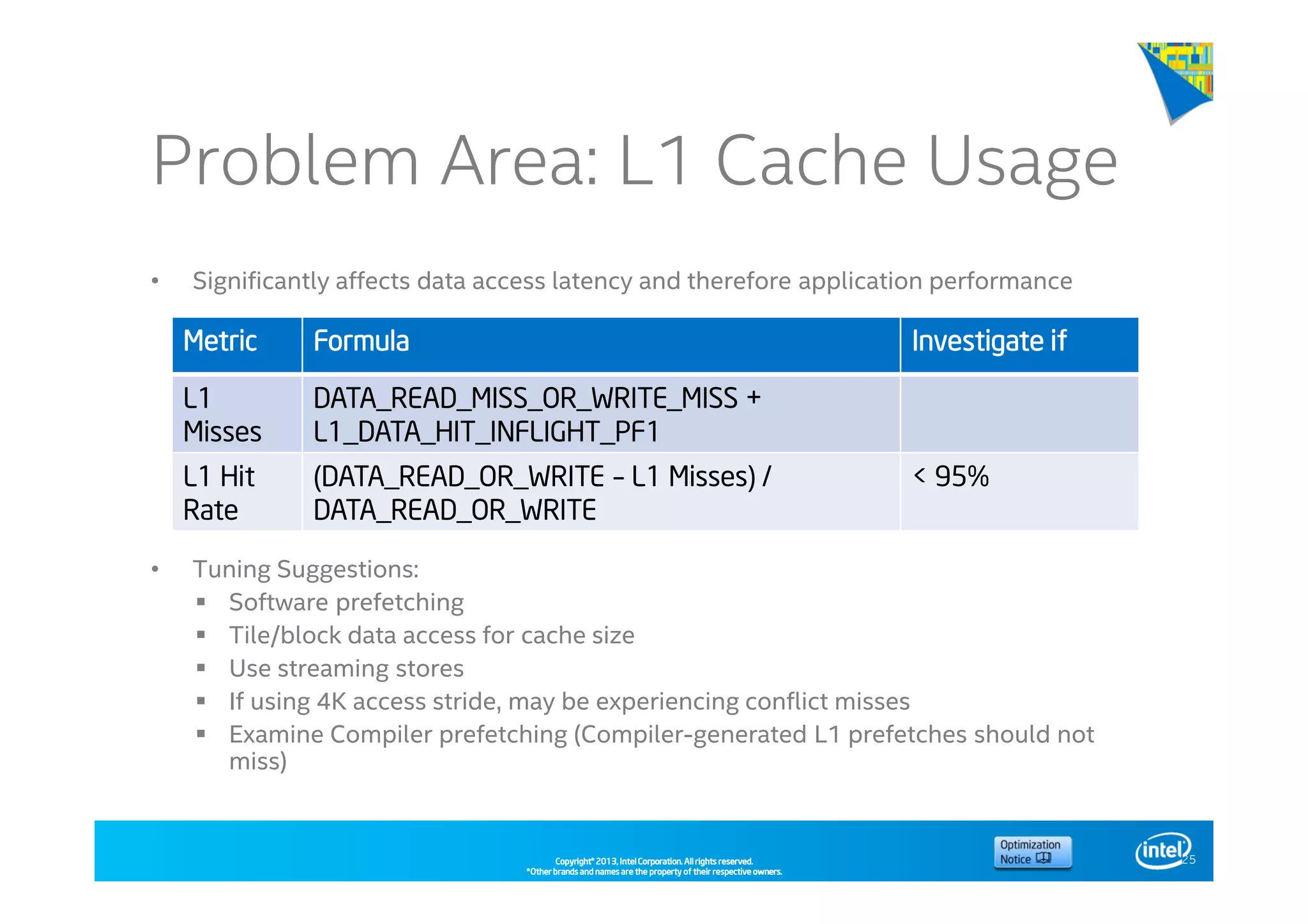






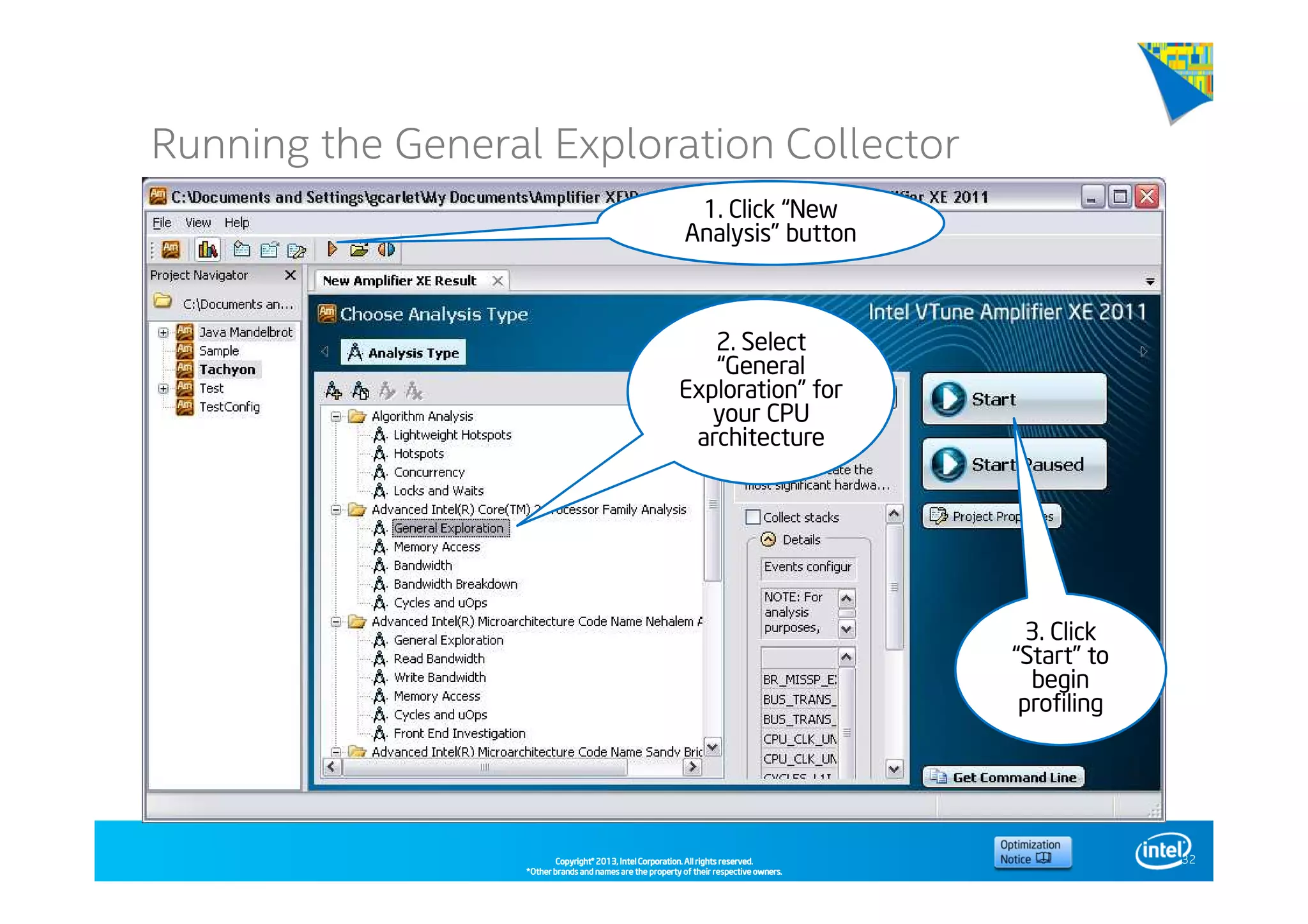
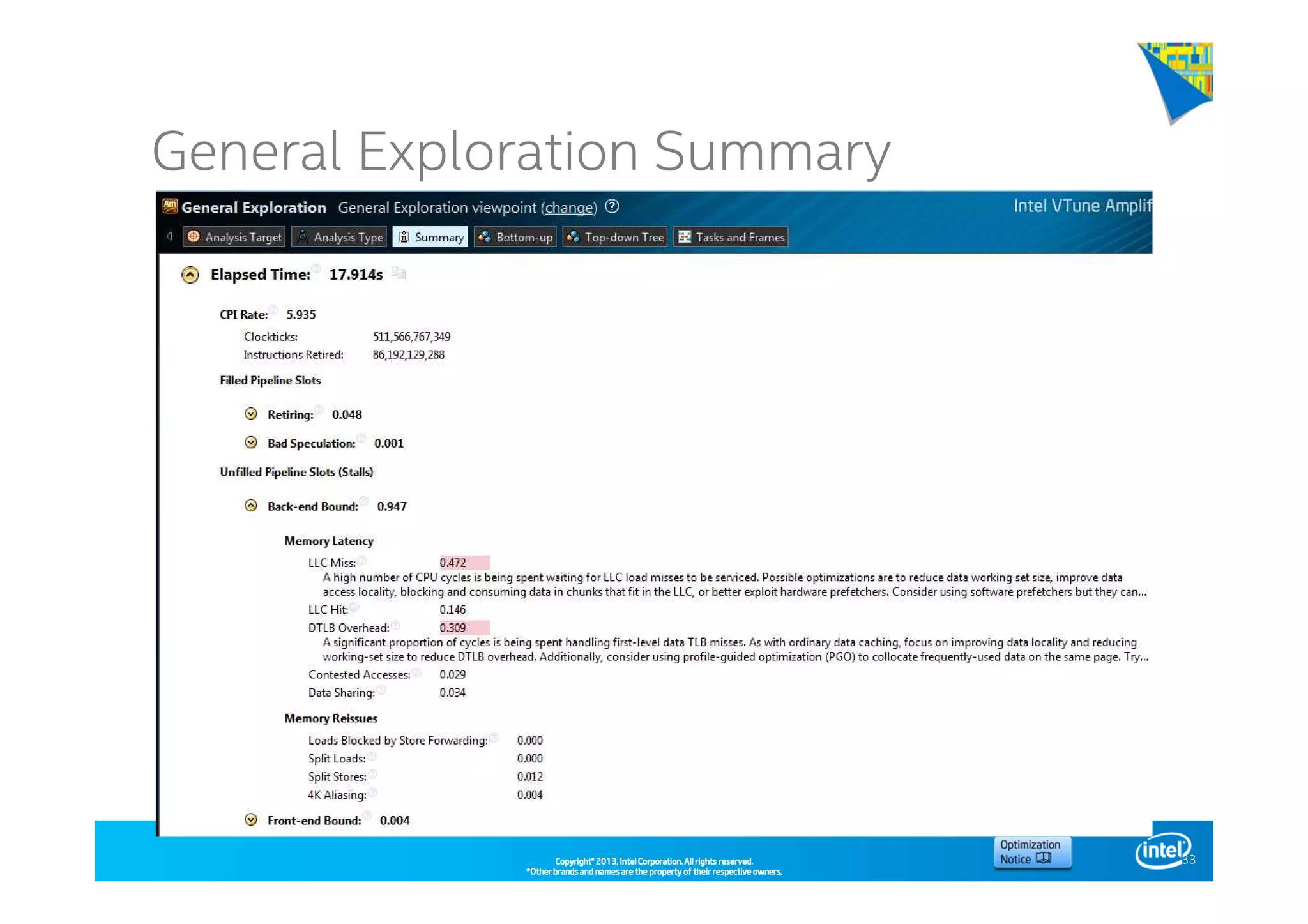
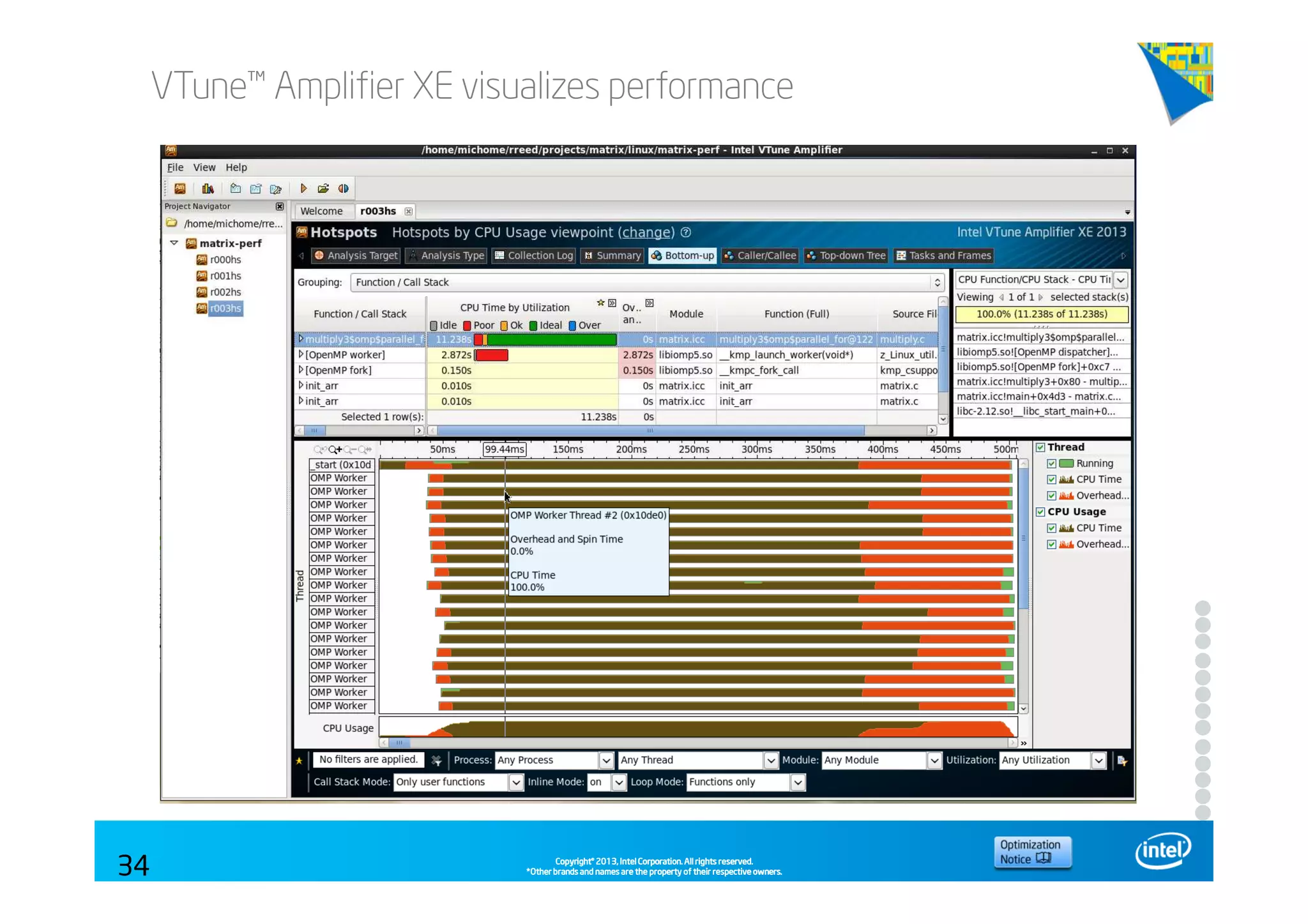
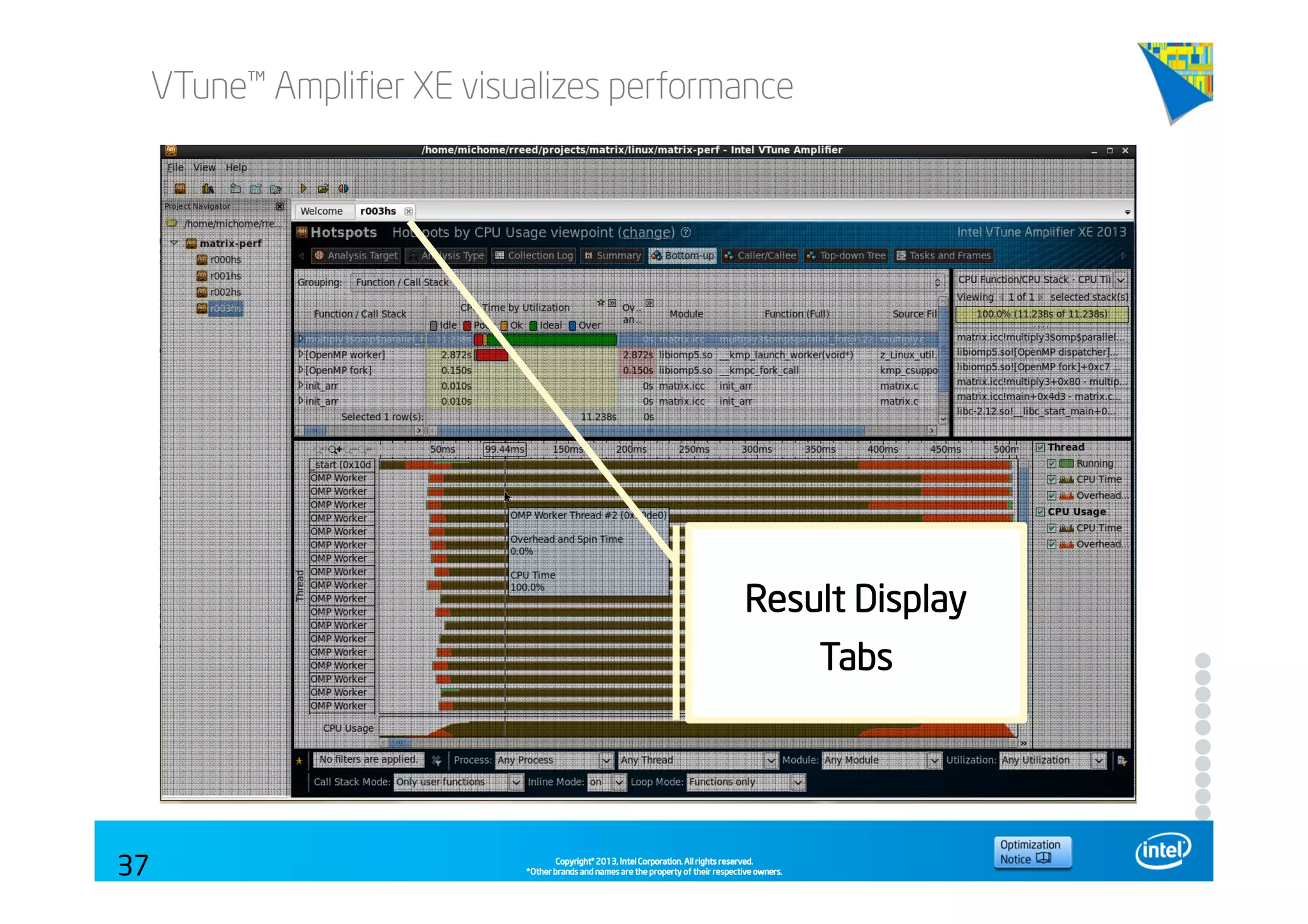
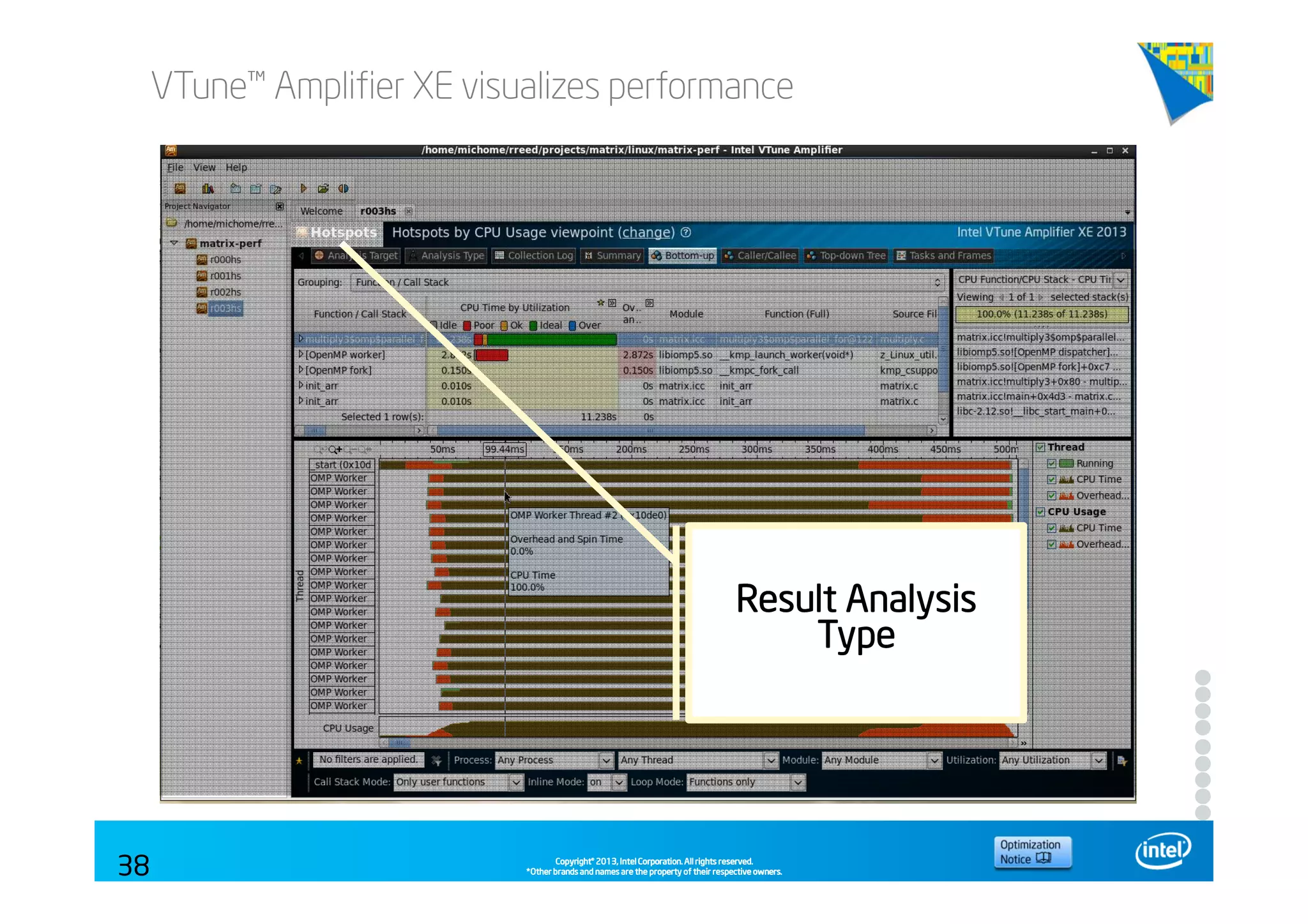
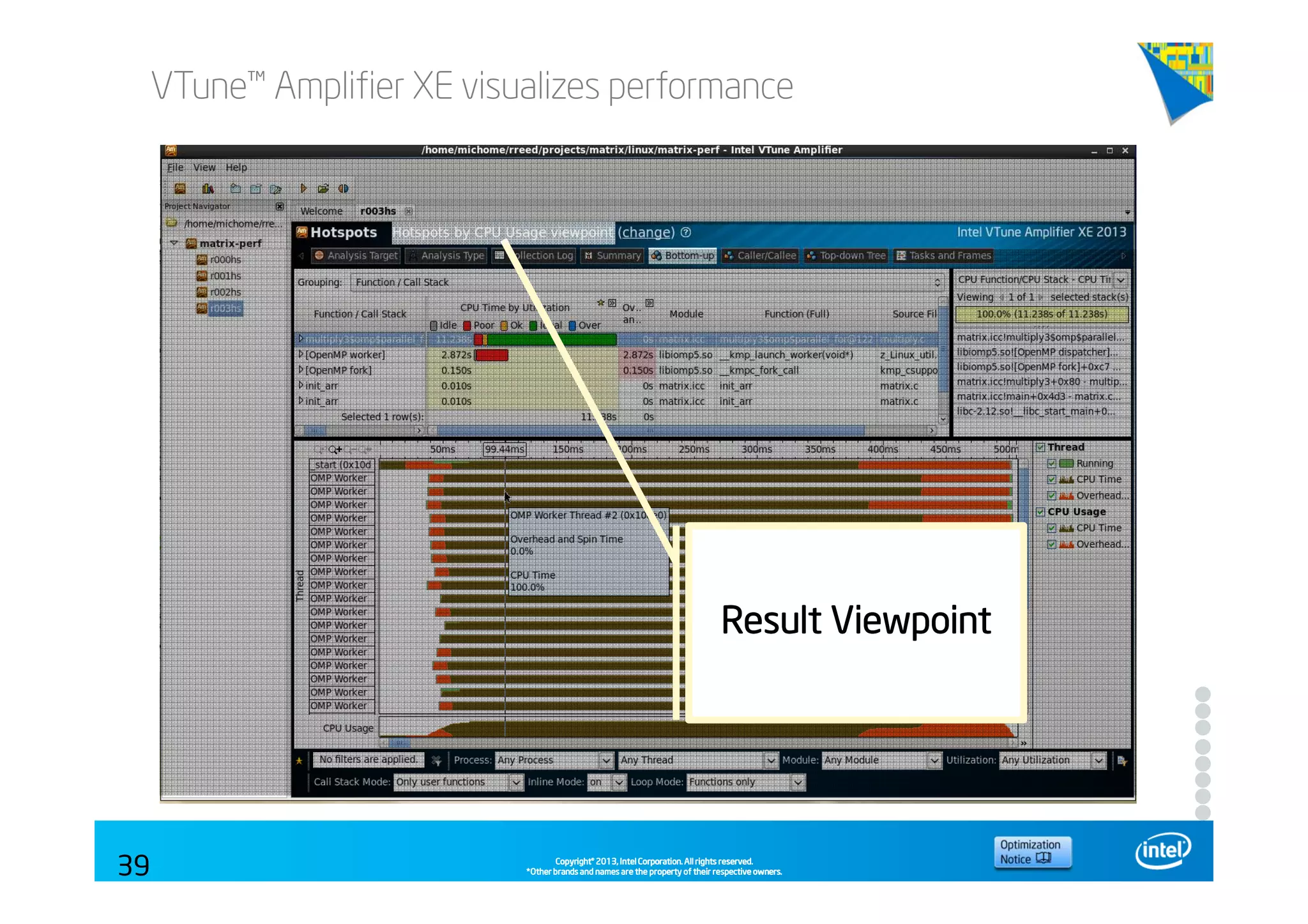
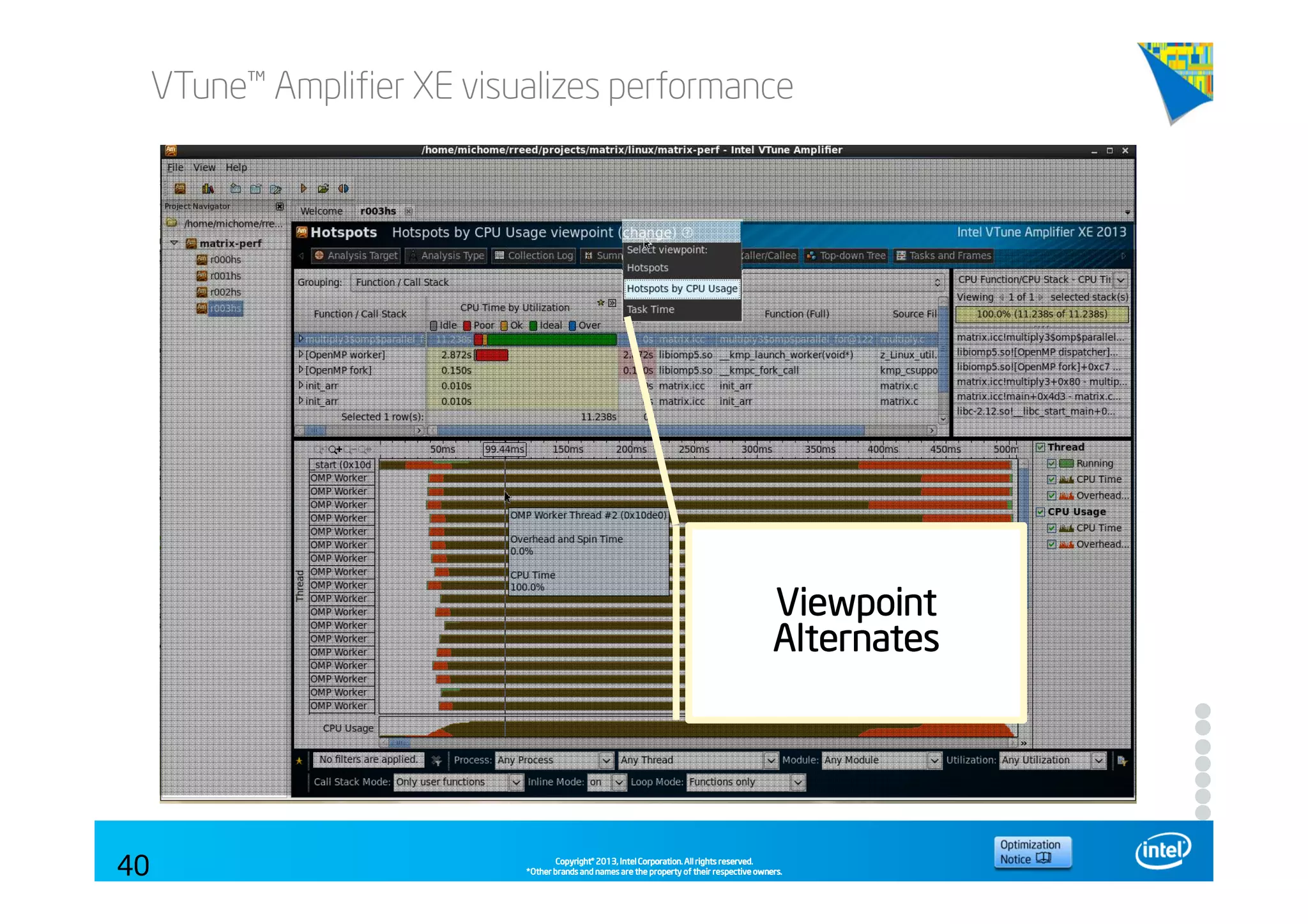
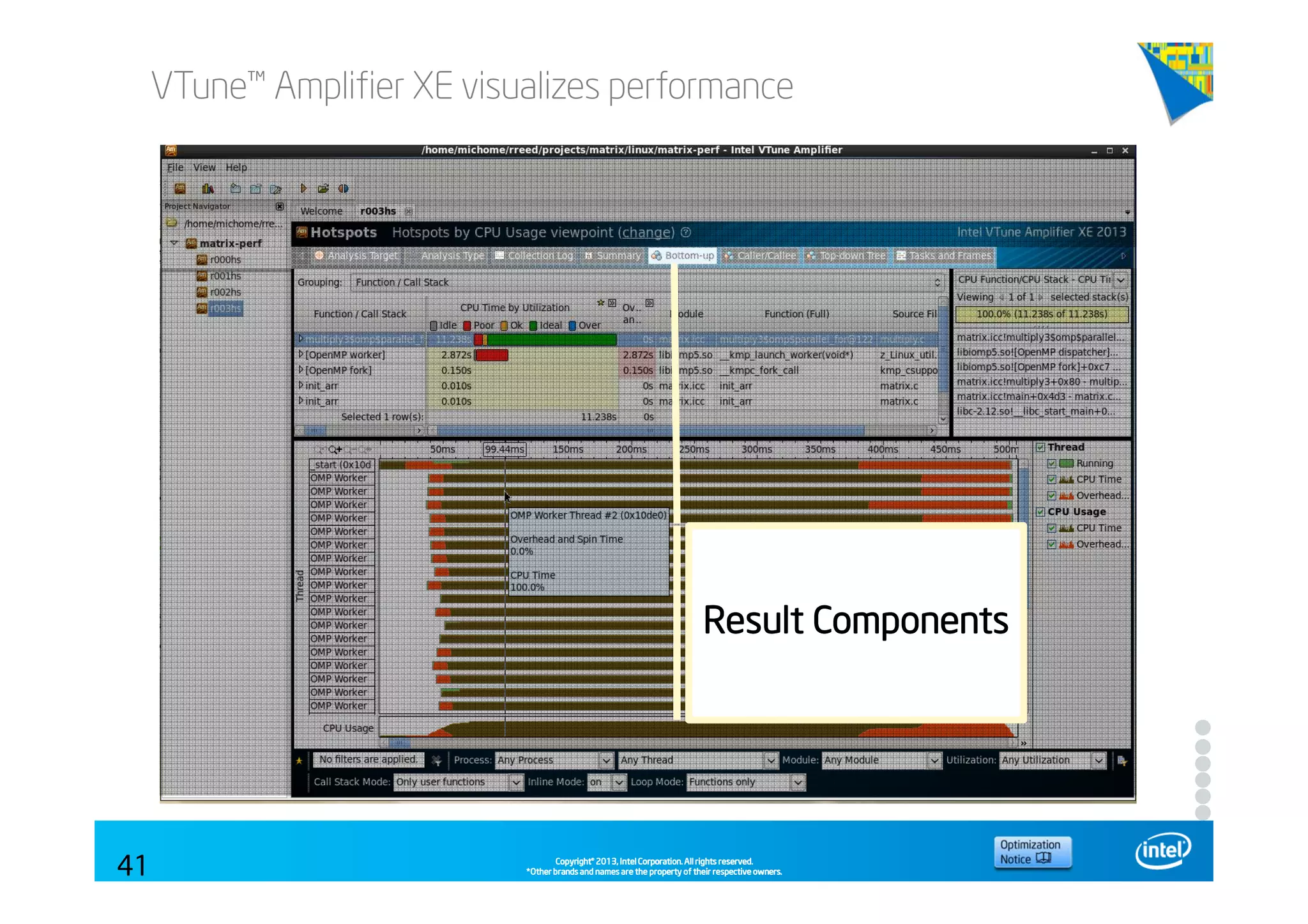
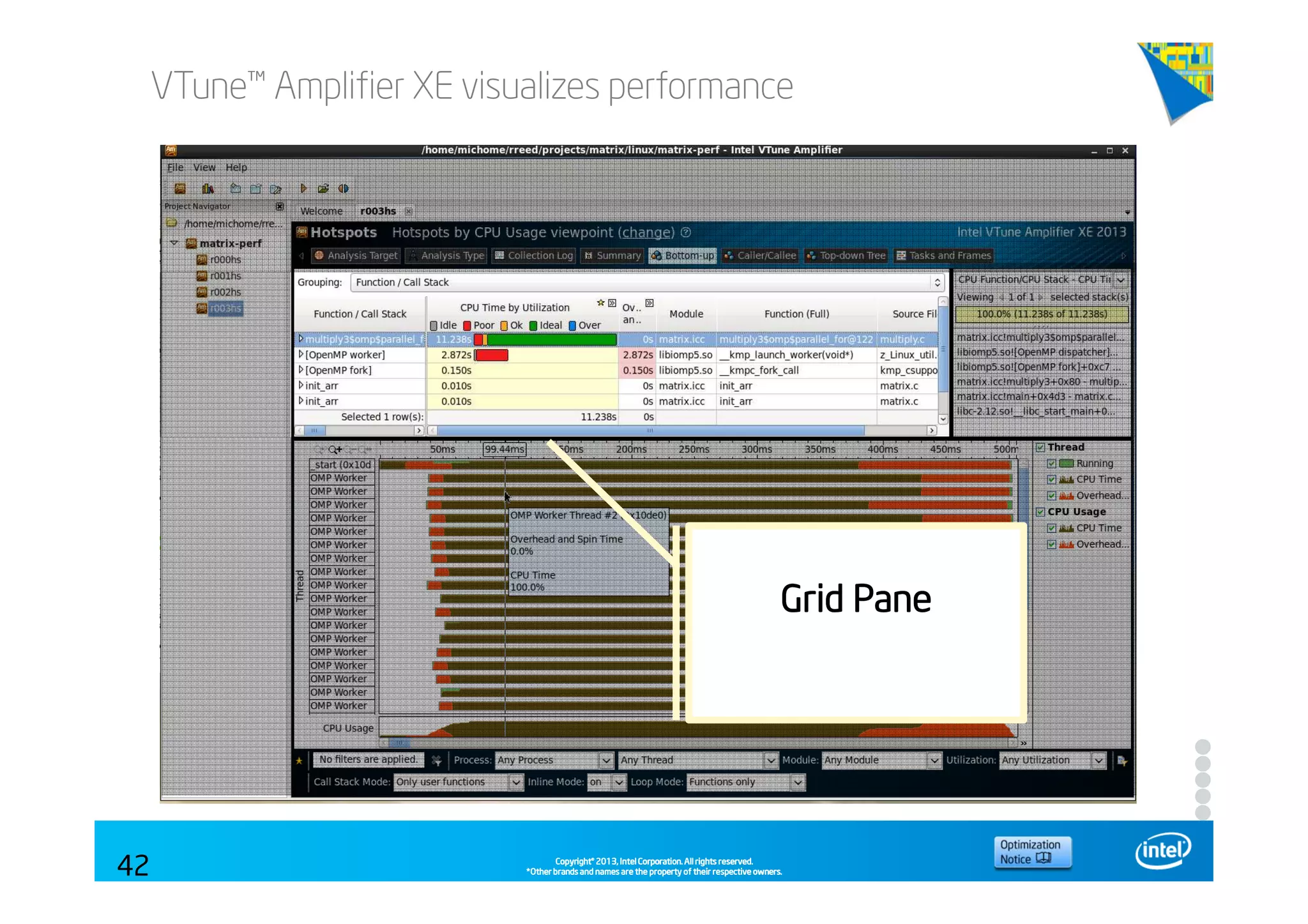
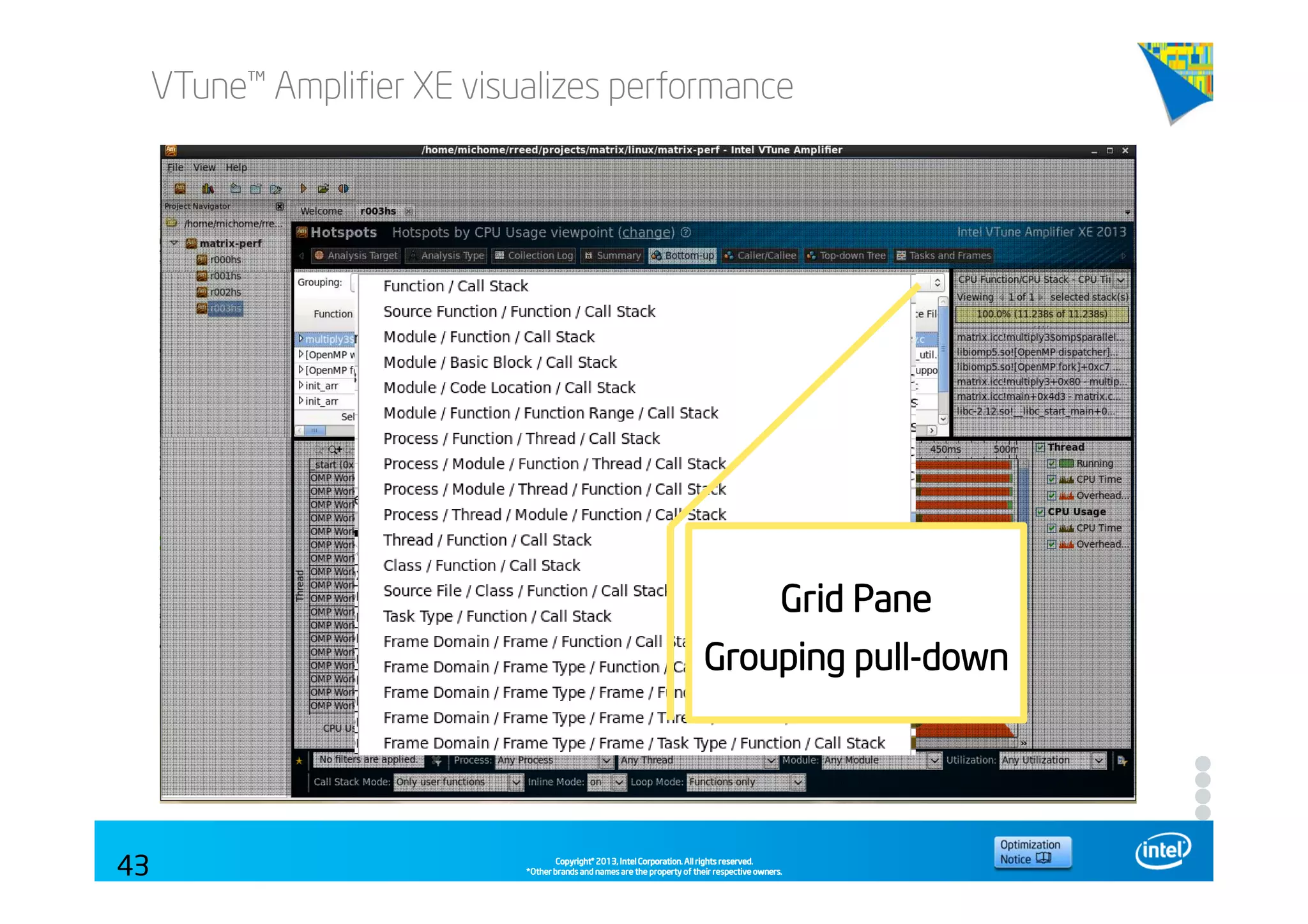
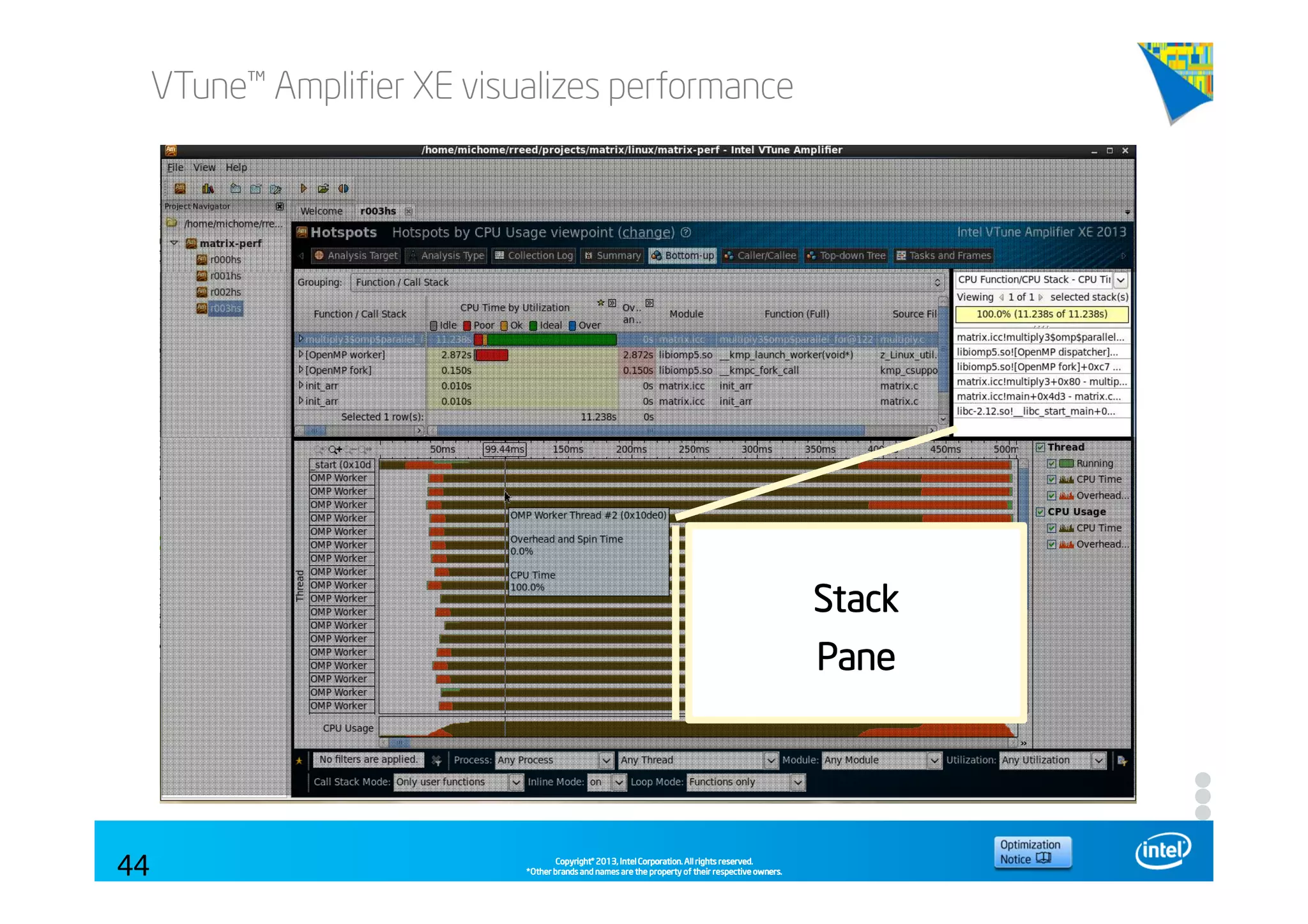





This document discusses analyzing application performance using Intel VTune Amplifier XE. It begins with an introduction to Intel VTune Amplifier XE and outlines its two main data collection methods: the software collector and hardware collector. It then provides a review of CPU microarchitecture basics like the fetch-decode-execute pipeline and front-end/back-end processing. The document defines key concepts like allocation, retirement, and "pipeline slots" to explain how instructions move through the various stages of the processor pipeline.























![No[1][1]](https://cdn.slidesharecdn.com/ss_thumbnails/no11-1196304497535347-2-thumbnail.jpg?width=640&height=640&fit=bounds)



























































