Download as PDF, PPTX











![in‑order access is kind of terrible
[15, 3, 0, 6, 11, 4, 5, 9, 12, 13, 8, 2, 1, 14, 10, 7]
[15, 3, 0, 6, 11, 4, 5, 9, 12, 13, 8, 2, 1, 14, 10, 7]
[15, 3, 0, 6, 11, 4, 5, 9, 12, 13, 8, 2, 1, 14, 10, 7]
[15, 3, 0, 6, 11, 4, 5, 9, 12, 13, 8, 2, 1, 14, 10, 7]
[15, 3, 0, 6, 11, 4, 5, 9, 12, 13, 8, 2, 1, 14, 10, 7]
[15, 3, 0, 6, 11, 4, 5, 9, 12, 13, 8, 2, 1, 14, 10, 7]
(Robin Hood, linear probing, MurmurHash3 hash function)
12](https://image.slidesharecdn.com/odsceast2018-180418211050/85/Next-Generation-Indexes-For-Big-Data-Engineering-ODSC-East-2018-12-320.jpg)
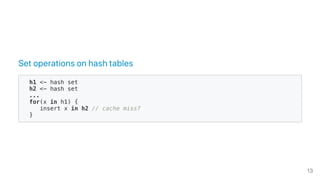



![Manipulate a bitmap
64‑bit processor.
Given x , word index is x/64 and bit index x % 64 .
add(x) {
array[x / 64] |= (1 << (x % 64))
}
18](https://image.slidesharecdn.com/odsceast2018-180418211050/85/Next-Generation-Indexes-For-Big-Data-Engineering-ODSC-East-2018-18-320.jpg)
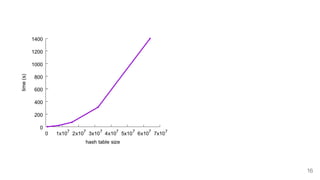
![How fast is it?
index = x / 64 -> a shift
mask = 1 << ( x % 64) -> a shift
array[ index ] |- mask -> a OR with memory
One bit every ≈ 1.65 cycles because of superscalarity
19](https://image.slidesharecdn.com/odsceast2018-180418211050/85/Next-Generation-Indexes-For-Big-Data-Engineering-ODSC-East-2018-19-320.jpg)






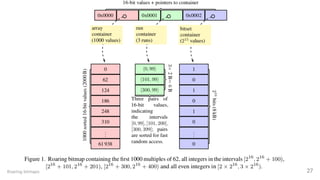
![Hybrid model
Set of containers
sorted arrays ({1,20,144})
bitset (0b10000101011)
runs ([0,10],[15,20])
Related to: O'Neil's RIDBit + BitMagic‑
Roaring bitmaps 26](https://image.slidesharecdn.com/odsceast2018-180418211050/85/Next-Generation-Indexes-For-Big-Data-Engineering-ODSC-East-2018-26-320.jpg)


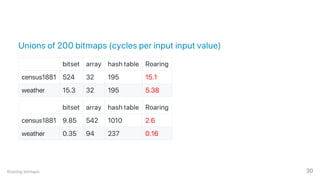





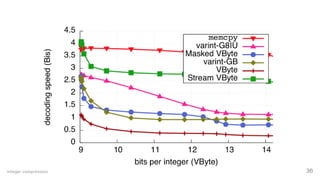

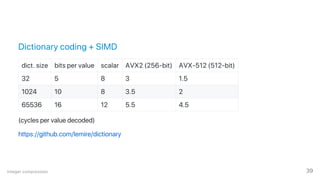


The document discusses advancements in big data engineering, highlighting the shift from monolithic systems to modular components that optimize performance through customizable database engines. It emphasizes the importance of specialized data structures, high-level optimizations, and modern indexing techniques like bitmaps and roaring bitmaps for efficient data manipulation. Additionally, various compression methods and their implementation in programming languages are explored to enhance data processing speed and efficiency.