Downloaded 282 times






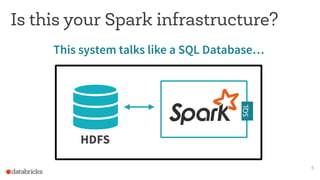
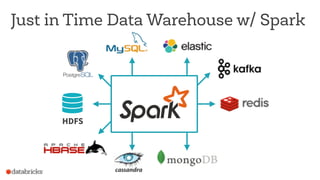













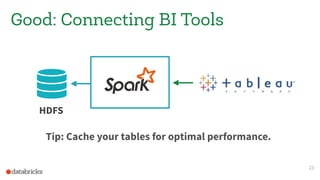

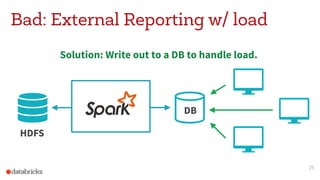




This document discusses appropriate and inappropriate uses of Apache Spark for different types of data and workloads. It provides guidance on when to use Spark versus other data stores like databases. Good uses of Spark include general purpose processing of file-based data, data transformation/ETL, and machine learning/data science. Bad uses include random access queries, frequent inserts/updates, external reporting with high load, and content searching with high load, as Spark is not optimized for these types of workloads. The document recommends using a database instead for workloads involving random access, frequent changes, or high query loads.























































































