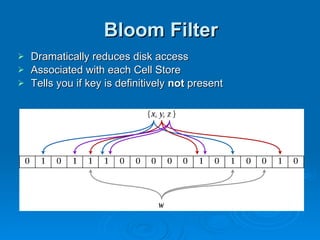
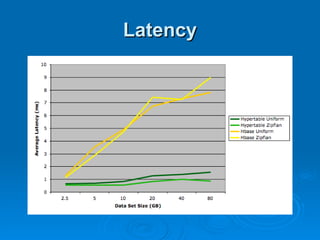
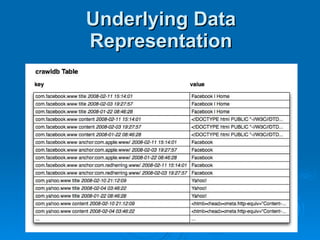
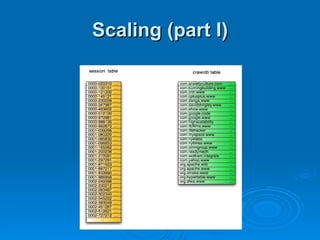
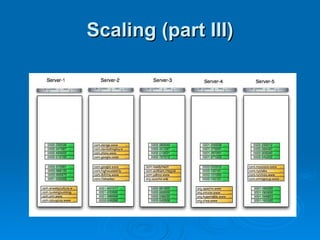
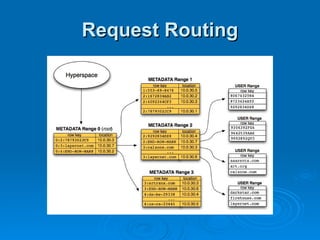
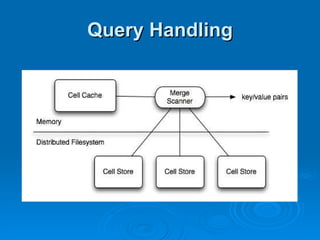
The document summarizes Hypertable, an open source scalable database modeled after Bigtable. It discusses Hypertable's architecture, data representation, scaling abilities, query handling, features like namespaces, column families, access groups, and regular expression filtering. It also evaluates Hypertable's performance compared to HBase, finding it has advantages for certain workloads like random reads and writes. Upcoming releases will focus on automatic range balancing and an improved monitoring system.












![Atomic Counters New column option: Modified via existing API using specially formatted values: create table counts ( url COUNTER, ); Reset counter to n =n Decrement counter by n -n Increment counter by n [+]n Description Value Format](https://image.slidesharecdn.com/nosql-series-part-3-hypertable-110127111610-phpapp02/85/Nosql-series-part-3-hypertable-17-320.jpg)