



![Managing a Replica Set
• rs.conf()
• Shell helper: get current configuration
• rs.initiate([<cfg>]);
• Shell helper: initiate replica set
• rs.add(“hostname:<port>”)
• Shell helper: add a new member
• rs.reconfig(<cfg>)
• Shell helper: reconfigure a replica set
• rs.remove(“hostname:<port>”)
• Shell helper: remove a member](https://image.slidesharecdn.com/replication-december-2011-111205145153-phpapp01/85/Replication-and-replica-sets-5-320.jpg)








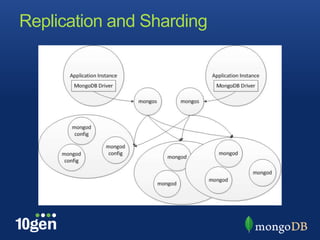





Replication in MongoDB allows for high availability and scaling of reads. A replica set consists of at least three mongod servers, with one primary and one or more secondaries that replicate from the primary. Writes go to the primary while reads can be distributed to secondaries for scaling. Replica sets are configured and managed through shell helpers, and maintain consistency through an oplog and elections when the primary is unavailable.


































































































