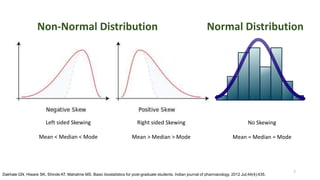
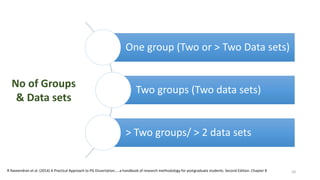
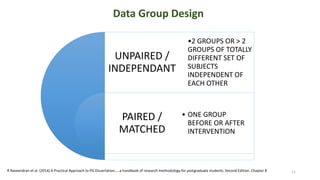
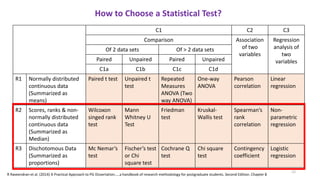
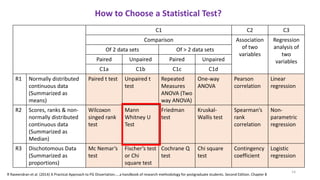
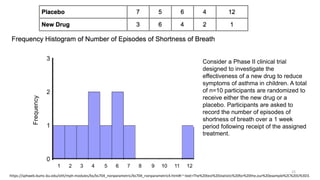
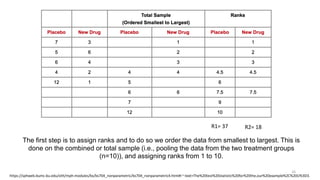
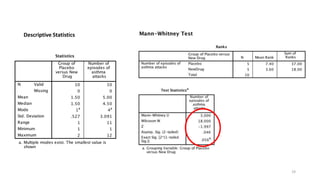
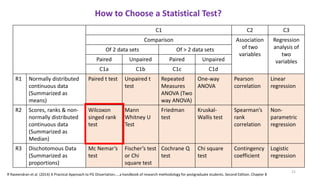
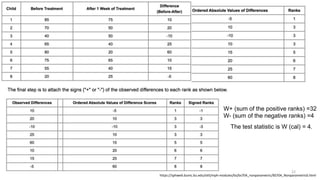
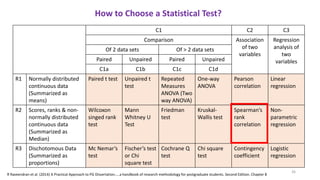
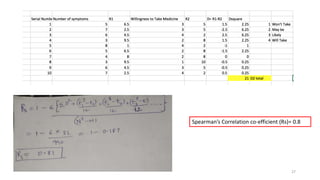
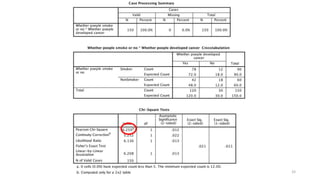
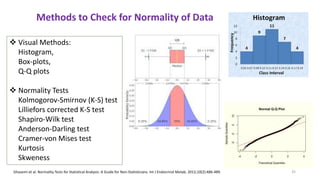
The document provides a comprehensive overview of choosing statistical tests in research, detailing parametric and non-parametric tests based on data distribution, type of data, analysis goals, and group design. It includes examples such as the Mann-Whitney U test and Chi-square test to illustrate application scenarios and hypotheses. Additionally, it discusses methods for checking data normality and the relevance of these tests in interpreting clinical trial results.