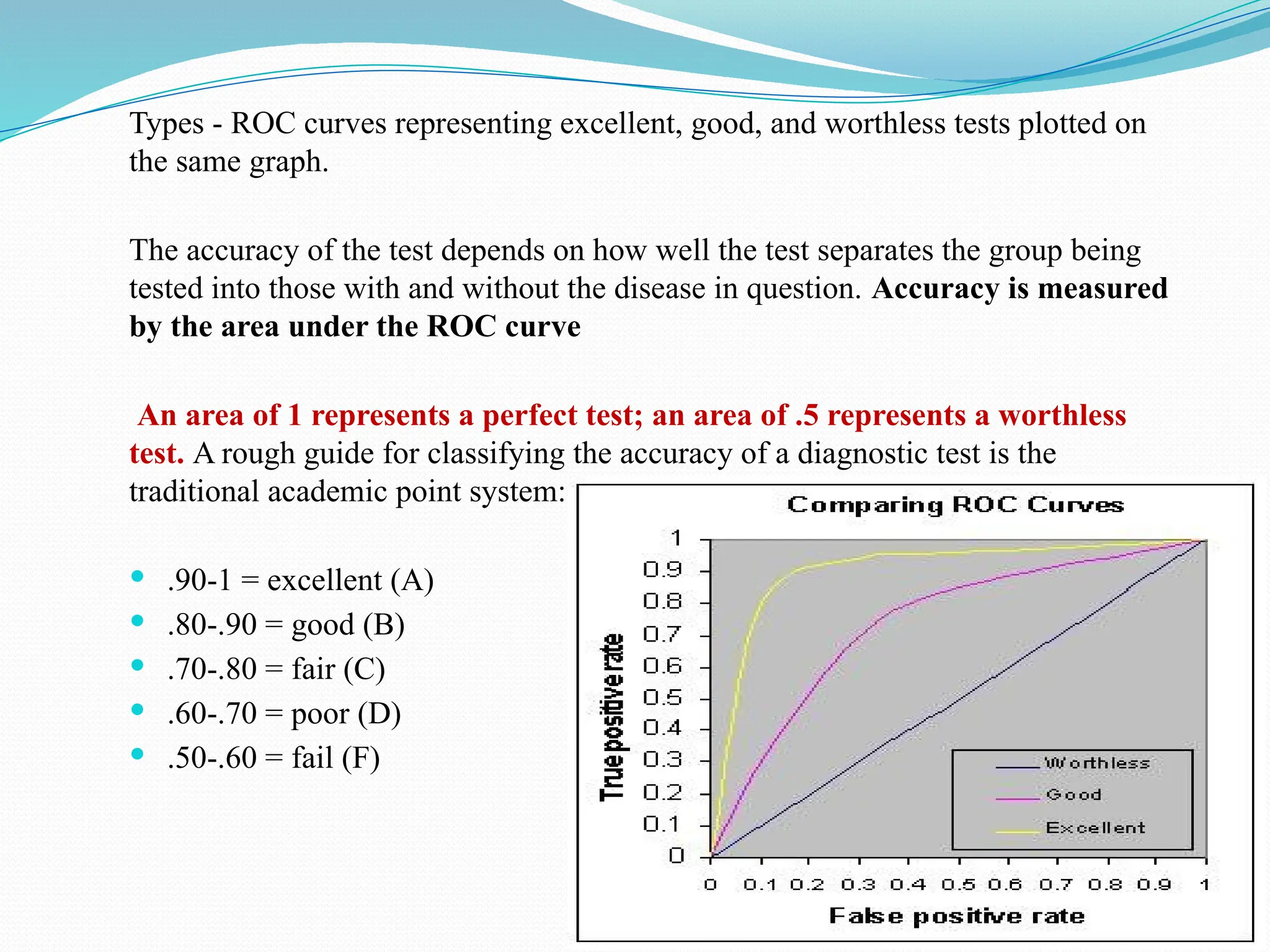
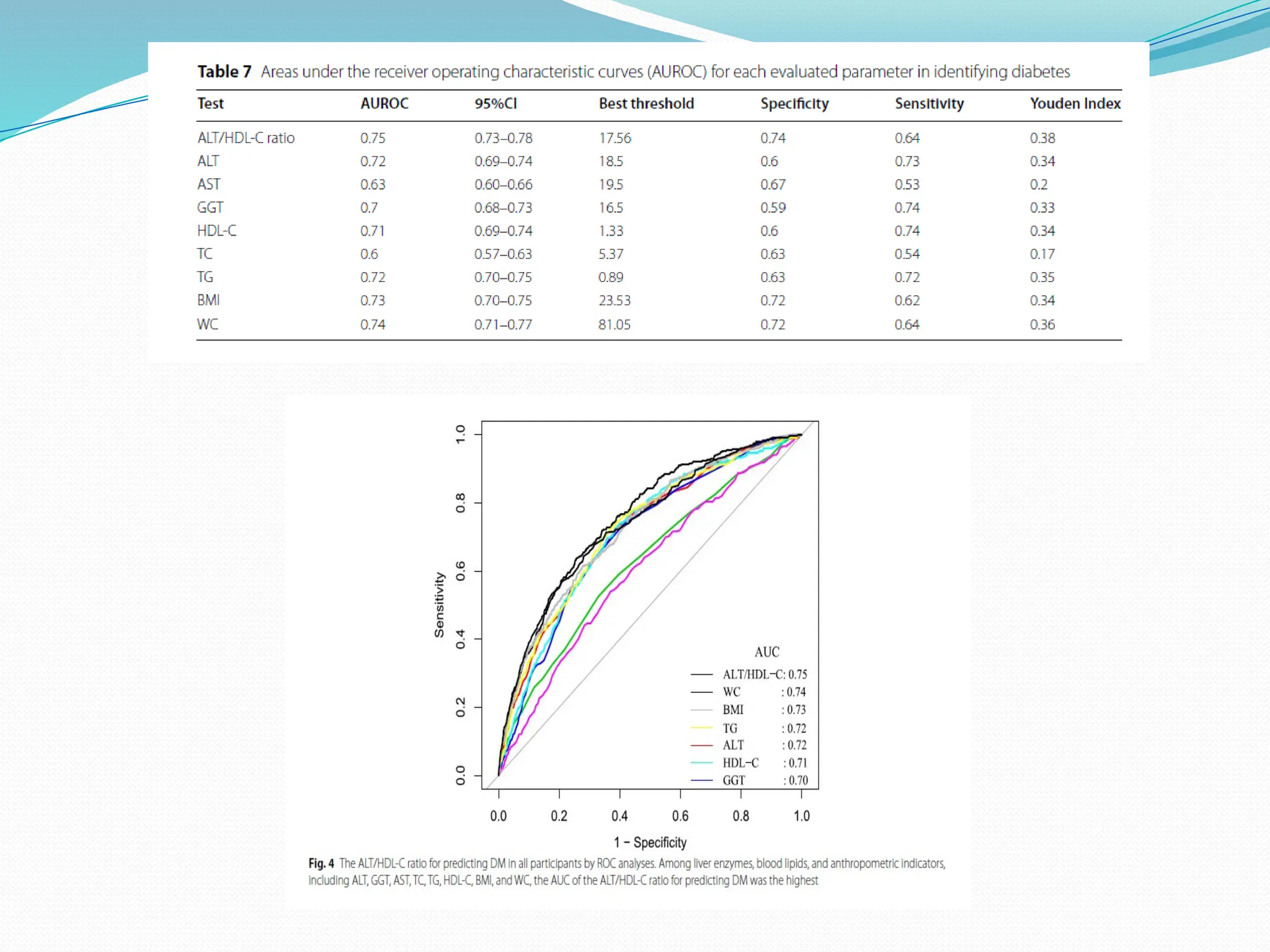
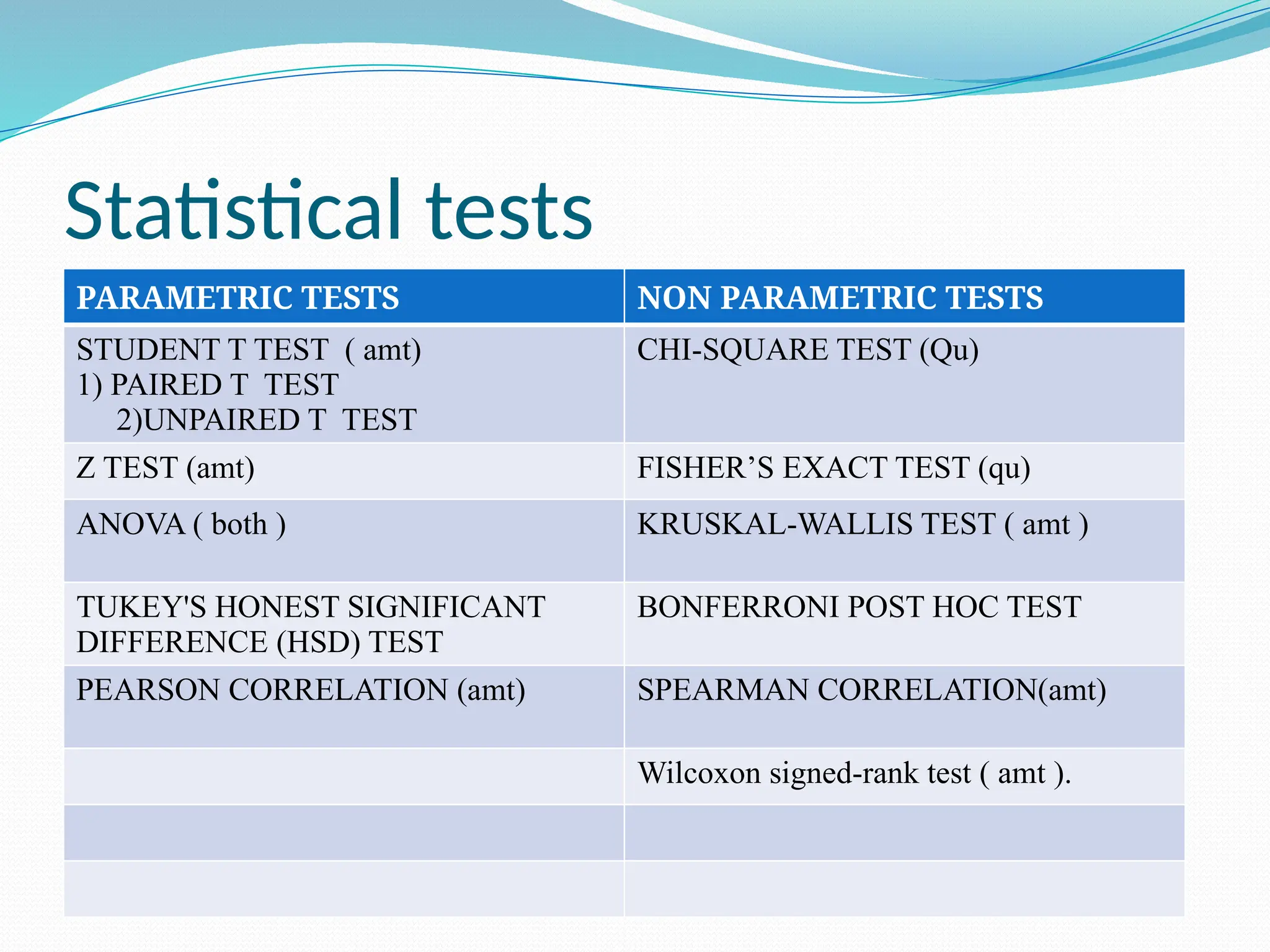
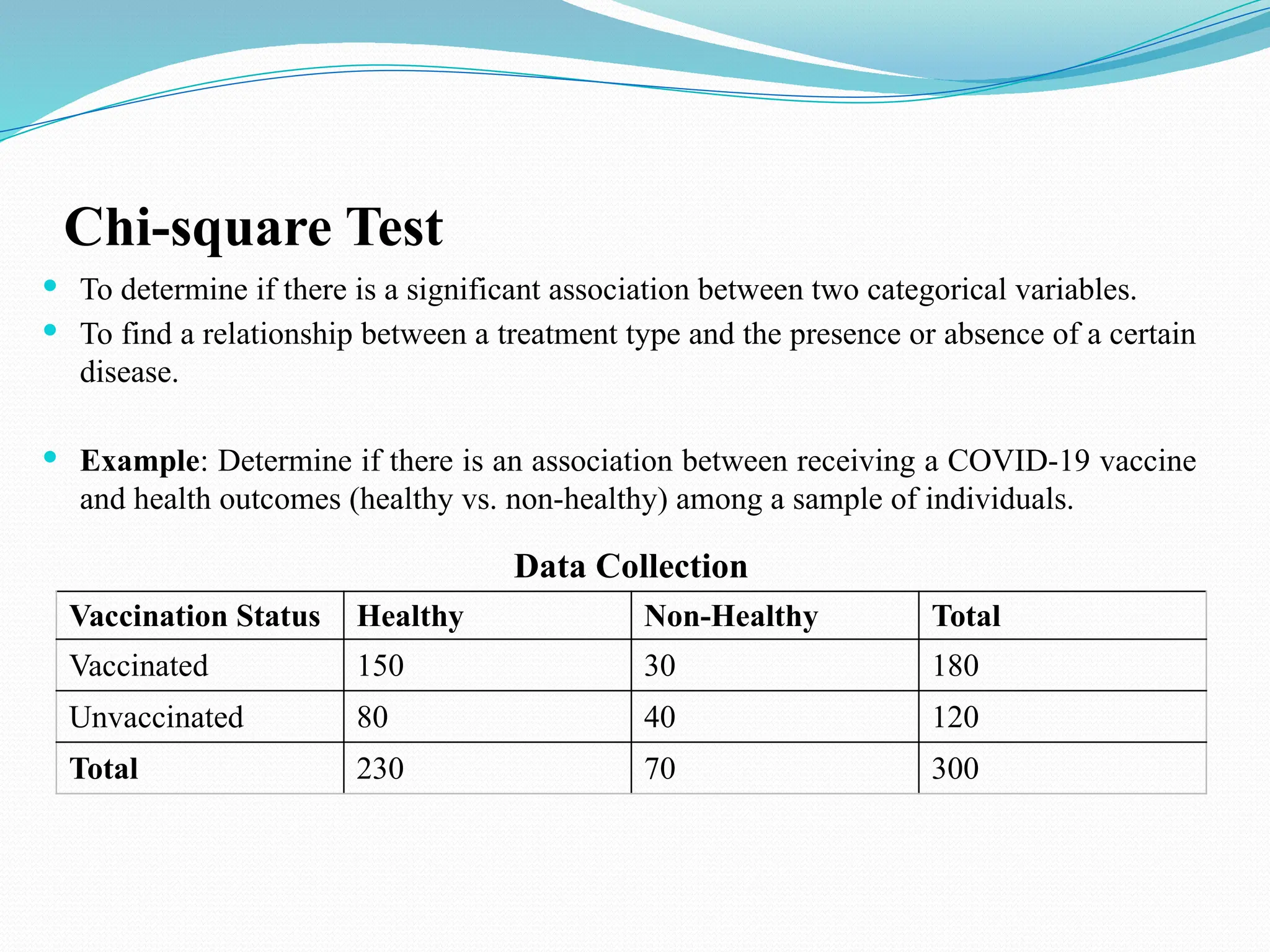
The document discusses various statistical tests used to analyze data, focusing on tests of significance, p-values, and confidence intervals. It explains different types of errors, including Type I and Type II errors, and various statistical methods like the paired t-test, unpaired t-test, chi-square test, ANOVA, and correlation coefficients. Additionally, the document details applications such as the Wilcoxon signed-rank test and the use of ROC curves for evaluating binary classifiers.




































![Steps in the Kruskal-Wallis Test:
1. Combine and Rank Data:
- Example: Suppose you are comparing the effectiveness of three different diets on weight loss in three groups
of participants:
- Group A (Diet A): 5, 7, 6
- Group B (Diet B): 8, 9, 7
- Group C (Diet C): 4, 3, 5
- Combine the data: [5, 7, 6, 8, 9, 7, 4, 3, 5]
- Rank the data: [3, 4, 5, 5, 5, 6, 7, 7, 8, 9]
2. Calculate the Test Statistic (H):
- Calculate the sum of ranks for each group.
- Compute the ( H ) statistic using the Kruskal-Wallis formula.](https://image.slidesharecdn.com/biostatistics1stsept-copy-241015152440-1c05237f/75/STATISTICAL-TESTS-USED-IN-VARIOUS-STUDIES-41-2048.jpg)