Downloaded 82 times





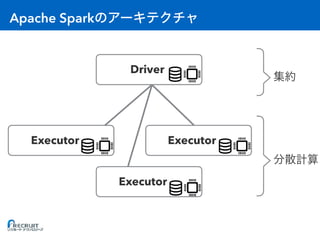
![Apache Spark
Lost executor X on xxxx: remote
Akka client disassociated
Container marked as failed:
container_xxxx on host: xxxx. Exit status: 1
Container killed by YARN for
exceeding memory limits
shutting down JVM since 'akka.jvm-exit-on-fatal-error'
is enabled for ActorSystem[Remote]](https://image.slidesharecdn.com/20161221sparkmemory-161221132628/85/Apache-Spark-8-320.jpg)









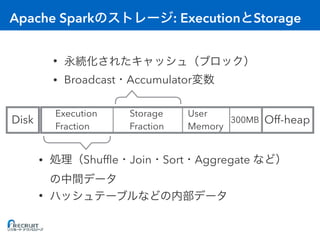
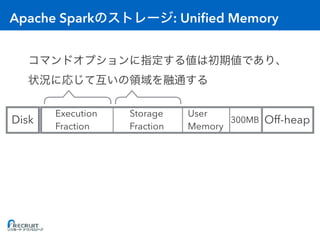

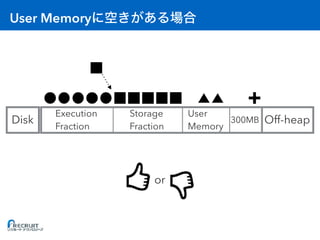
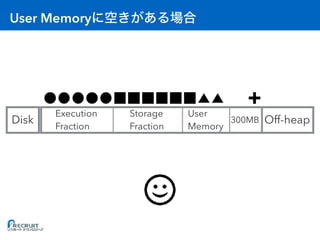

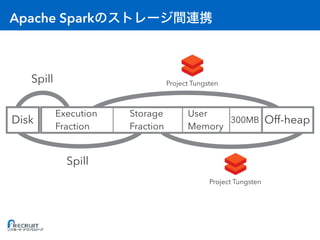




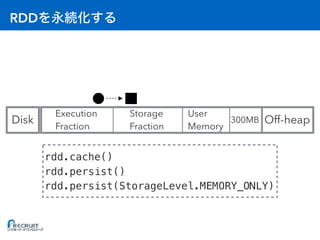
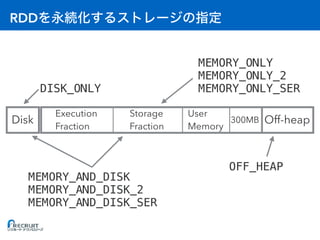

![RDD
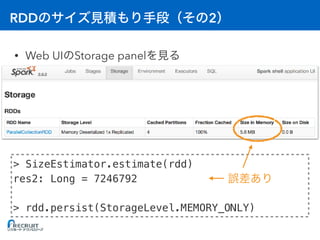
> orders = sc.textFile("lineorder.csv")
orders: org.apache.spark.rdd.RDD[String] = ...
> result = orders.map(...)
result: org.apache.spark.rdd.RDD[String] = ...
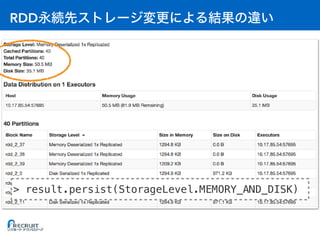
> orders.persist(StorageLevel.MEMORY_ONLY)
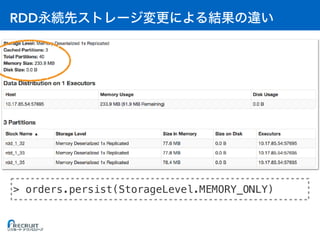
> result.persist(StorageLevel.MEMORY_AND_DISK)](https://image.slidesharecdn.com/20161221sparkmemory-161221132628/85/Apache-Spark-48-320.jpg)

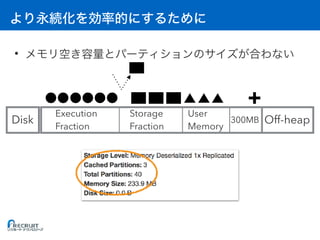
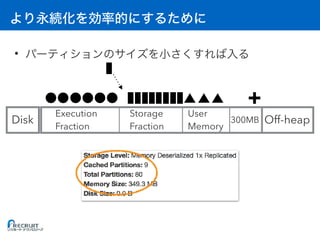


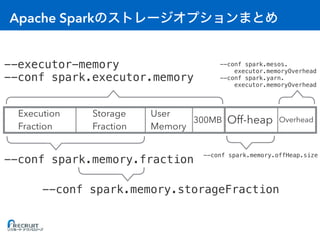
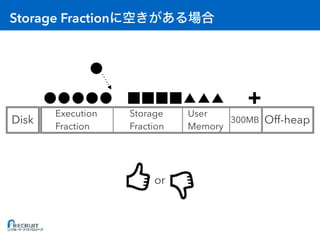
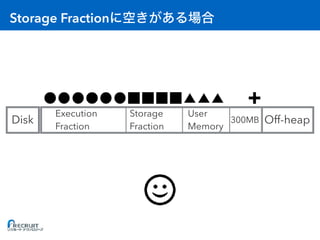
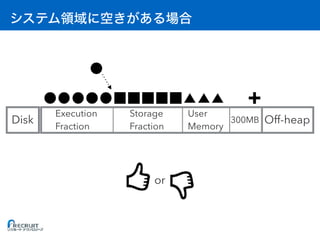
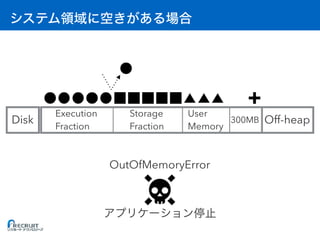
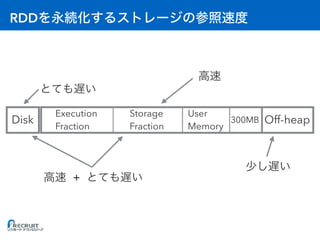
![: Executor
• [A] Storage Fraction = RDD
• [B] Execution Fraction = A
• [C] On-heap = (A + B) / 0.6 + 300MB // 0.6 User Memory
• [D] Off-heap = RDD
• [E] Overhead = max(C * 0.1, 384MB) //
• [F] 1 Container (Executor)
• [G] OS
• [H]
(C + D + E) * F + G < H](https://image.slidesharecdn.com/20161221sparkmemory-161221132628/85/Apache-Spark-59-320.jpg)




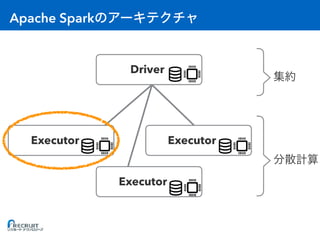
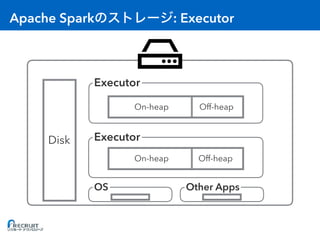
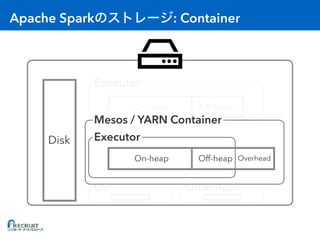
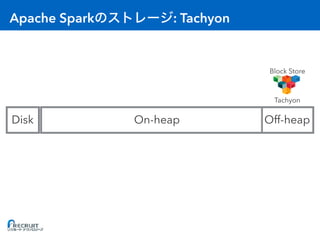
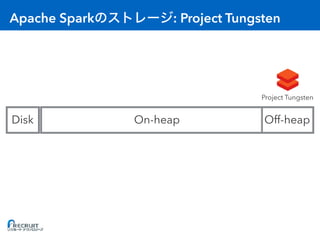
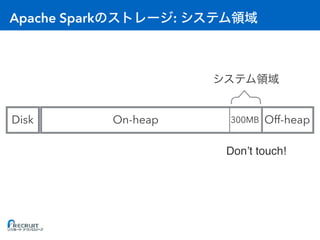
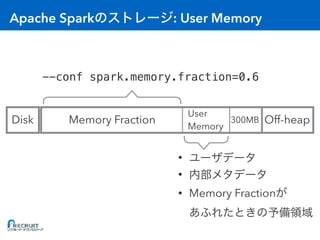
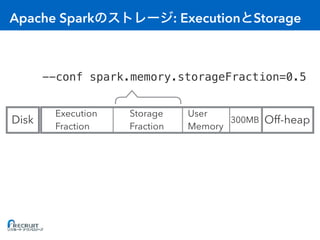
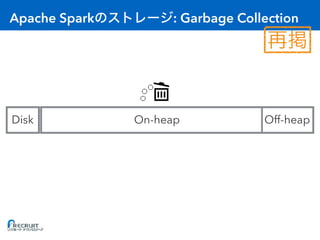
- Apache Spark is an open-source cluster computing framework for large-scale data processing. It was originally developed at the University of California, Berkeley in 2009 and is used for distributed tasks like data mining, streaming and machine learning. - Spark utilizes in-memory computing to optimize performance. It keeps data in memory across tasks to allow for faster analytics compared to disk-based computing. Spark also supports caching data in memory to optimize repeated computations. - Proper configuration of Spark's memory options is important to avoid out of memory errors. Options like storage fraction, execution fraction, on-heap memory size and off-heap memory size control how Spark allocates and uses memory across executors.













































































