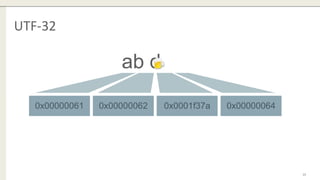
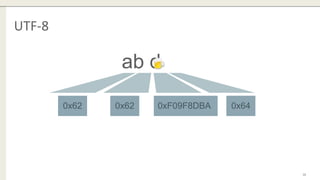
The document discusses the enhancements in MySQL 8.0 regarding regular expressions, including support for Unicode through the ICU library and new functions such as regexp_instr, regexp_like, regexp_replace, and regexp_substr. It outlines the limitations of the previous regex library and addresses security concerns such as memory and runtime caps. Additionally, the document offers insights into case sensitivity and conversion issues when working with different character sets.