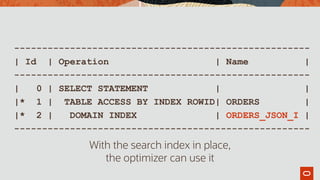
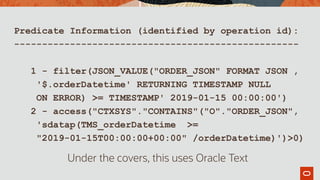
This document discusses storing product and order data as JSON in a database to support an agile development process. It describes creating tables with JSON columns to store this data, and using JSON functions like JSON_VALUE and JSON_TABLE to query and transform the JSON data. Examples are provided of indexing JSON columns for performance and updating product JSON to include unit costs by joining external data. The goal is to enable flexible and rapid evolution of the application through storing data in JSON.


















![{
"productName": "GEEKWAGON",
"descripion": "Ut commodo in …",
"unitPrice": 35.97,
"bricks": [ {
"colour": "red", "shape": "cube",
"quantity": 13
}, {
"colour": "green", "shape": "cube",
"quantity": 17
}, …
]
}
We need to search for this
value in the documents](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-20-320.jpg)




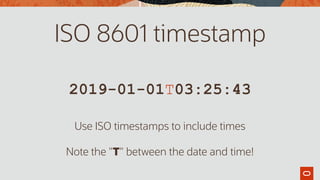
![{
"customerId" : 2,
"orderDatetime" : "2019-01-01T03:25:43",
"products" : [ {
"productId" : 1,
"unitPrice" : 74.95
}, {
"productId" : 10,
"unitPrice" : 35.97
}, …
]
}
We need to extract these
from the product array](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-25-320.jpg)
![select o.order_json.products[*].productId
from orders o;
PRODUCTS
[2,8,5]
[3,9,6]
[1,10,7,4]
...
With simple dot-notation,
you can get an array of
the values…](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-26-320.jpg)
![select json_query (
order_json, '$.products[*].productId'
with array wrapper
)
from orders o;
PRODUCTS
[2,8,5]
[3,9,6]
[1,10,7,4]
...
But to join these to
products, we need to
convert them to rows…
…or with json_query](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-27-320.jpg)

![with order_items as (
select order_id, t.*
from orders o, json_table (
order_json
columns (
customerId,
nested products[*] columns (
productId,
unitPrice
) )
) t
)
Simplified syntax 18c](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-29-320.jpg)
![with order_items as (
select order_id, t.*
from orders o, json_table (
order_json
columns (
customerId,
nested products[*] columns (
productId,
unitPrice
) )
) t
)
This tells the database to
return a row for each
element in the products
array…](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-30-320.jpg)




![{
"customerId" : 2,
"orderDatetime" : "2019-01-01T03:25:43",
"products" : [ {
"productId" : 1,
"unitPrice" : 74.95
}, {
"productId" : 10,
"unitPrice" : 35.97
}, …
]
}
We need to search
for this value in the
documents](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-35-320.jpg)


















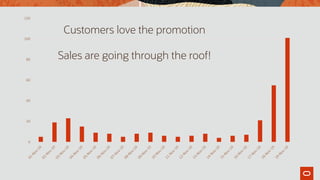





![{ …,
"bricks": [ {
"colour": "red",
"shape": "cube",
"quantity": 13
}, {
"colour": "green",
"shape": "cuboid",
"quantity": 17
}, …
]
}
Add unitCost](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-64-320.jpg)

!["bricks": [ {
"colour": "red",
"shape": "cube",
"quantity": 13
}, {
"colour": "green",
"shape": "cuboid",
"quantity": 17
}, …
] join on
colour, shape
We need to combine the spreadsheet
data with the stored JSON](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-66-320.jpg)
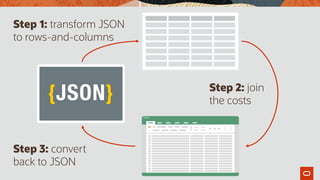


![select product_id, j.*
from products, json_table (
product_json columns (
nested bricks[*] columns (
pos for ordinality,
colour path '$.colour',
shape path '$.shape',
brick format json path '$'
)
)
) j
Using JSON_table to
extract the bricks as rows](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-70-320.jpg)
![select product_id, j.*
from products, json_table (
product_json columns (
nested bricks[*] columns (
pos for ordinality,
colour path '$.colour',
shape path '$.shape',
brick format json path '$'
)
)
) j](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-71-320.jpg)
![select product_id, j.*
from products, json_table (
product_json columns (
nested bricks[*] columns (
pos for ordinality,
colour path '$.colour',
shape path '$.shape',
brick format json path '$'
)
)
) j](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-72-320.jpg)



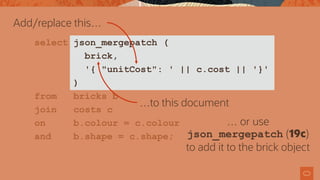


![[ {
"colour": "red",
"shape": "cube",
"quantity": 13,
"unitCost": 0.59
}, {
"colour": "green",
"shape": "cuboid",
"quantity": 17,
"unitCost": 0.39
}, …
]
Make the array into
an object with
json_object](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-79-320.jpg)

!["bricks": [ {
"colour": "red",
"shape": "cube",
"quantity": 13,
"unitCost": 0.59
}, {
"colour": "green",
"shape": "cuboid",
"quantity": 17,
"unitCost": 0.39
}, …
]
And replace this
array in the product
JSON with
json_mergepatch](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-81-320.jpg)
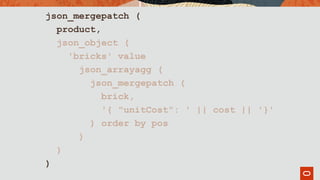
![{
"productName": "GEEKWAGON",
"descripion": "Ut commodo in …",
"unitPrice": 35.97,
"bricks": [ {
…, "unitCost": 0.59
}, {
…, "unitCost": 0.39
}, …
]
}
Finally!
We've added
unitCost to every
element in the array
We just need to
update the table…](https://image.slidesharecdn.com/agiledatabasedevwithjsonslideshare-191129145548/85/Agile-Database-Development-with-JSON-83-320.jpg)