Download as PDF, PPTX









![Interpreter
Kernel
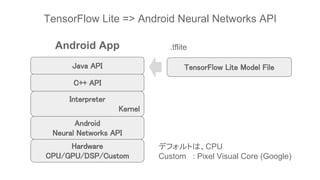
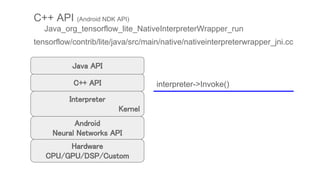
Java API
run
C++ API
Java API
Android
Neural Networks API
Hardware
CPU/GPU/DSP/Custom
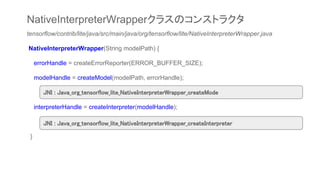
tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/NativeInterpreterWrapper.java
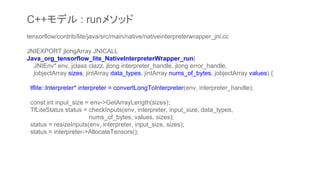
.tflite ファイルは、JavaのInterpreterクラス
(NativeInterpreterWrapperクラス)が生成さ
れたとき、内部的なC++ APIを介して、C++
コード内で読み込まれる
private static native long[] run(...);](https://image.slidesharecdn.com/tensorflowliteandroid8-180308015811/85/TensorFlow-Lite-r1-5-Android-8-1-Neural-Network-API-12-320.jpg)

![tensorflow/contrib/lite/java/demo/app/src/main/java/com/example/android/tflitecamerademo/
ImageClassifier.java
public class ImageClassifier {
ImageClassifier(Activity activity) throws IOException {
tflite = new Interpreter(loadModelFile(activity));
labelList = loadLabelList(activity);
imgData =
ByteBuffer.allocateDirect(
DIM_BATCH_SIZE * DIM_IMG_SIZE_X * DIM_IMG_SIZE_Y * DIM_PIXEL_SIZE);
imgData.order(ByteOrder.nativeOrder());
labelProbArray = new byte[1][labelList.size()];
Log.d(TAG, "Created a Tensorflow Lite Image Classifier.");
}
….
インタープリタの生成](https://image.slidesharecdn.com/tensorflowliteandroid8-180308015811/85/TensorFlow-Lite-r1-5-Android-8-1-Neural-Network-API-14-320.jpg)

![tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Interpreter.java
public void run(@NotNull Object input, @NotNull Object output) {
Object[] inputs = {input};
Map<Integer, Object> outputs = new HashMap<>();
outputs.put(0, output);
runForMultipleInputsOutputs(inputs, outputs);
}
Interpreterクラスのrunメソッド](https://image.slidesharecdn.com/tensorflowliteandroid8-180308015811/85/TensorFlow-Lite-r1-5-Android-8-1-Neural-Network-API-16-320.jpg)
![public void runForMultipleInputsOutputs(
@NotNull Object[] inputs, @NotNull Map<Integer, Object> outputs) {
if (wrapper == null) {
throw new IllegalStateException("The Interpreter has already been closed.");
}
Tensor[] tensors = wrapper.run(inputs);
if (outputs == null || tensors == null || outputs.size() > tensors.length) {
throw new IllegalArgumentException("Outputs do not match with model outputs.");
}
final int size = tensors.length;
for (Integer idx : outputs.keySet()) {
if (idx == null || idx < 0 || idx >= size) {
throw new IllegalArgumentException(
String.format("Invalid index of output %d (should be in range [0, %d))", idx, size));
}
tensors[idx].copyTo(outputs.get(idx));
}
}
NativeInterpreterWrapperクラスのrunメソッドを呼び出す](https://image.slidesharecdn.com/tensorflowliteandroid8-180308015811/85/TensorFlow-Lite-r1-5-Android-8-1-Neural-Network-API-17-320.jpg)
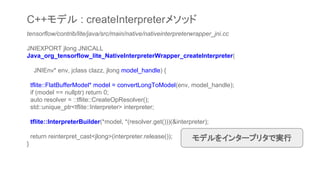
![tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/NativeInterpreterWrapper.java
Tensor[] run(Object[] inputs) {
int[] dataTypes = new int[inputs.length];
Object[] sizes = new Object[inputs.length];
int[] numsOfBytes = new int[inputs.length];
for (int i = 0; i < inputs.length; ++i) {
DataType dataType = dataTypeOf(inputs[i]);
dataTypes[i] = dataType.getNumber();
if (dataType == DataType.BYTEBUFFER) {
ByteBuffer buffer = (ByteBuffer) inputs[i];
numsOfBytes[i] = buffer.limit();
sizes[i] = getInputDims(interpreterHandle, i, numsOfBytes[i]);
} else if (isNonEmptyArray(inputs[i])) {
int[] dims = shapeOf(inputs[i]);
sizes[i] = dims;
numsOfBytes[i] = dataType.elemByteSize() * numElements(dims);
}
NativeInterpreterWrapperクラスのrunメソッドを呼び出す](https://image.slidesharecdn.com/tensorflowliteandroid8-180308015811/85/TensorFlow-Lite-r1-5-Android-8-1-Neural-Network-API-18-320.jpg)
![long[] outputsHandles =
run( interpreterHandle, errorHandle, sizes, dataTypes, numsOfBytes, inputs );
Tensor[] outputs = new Tensor[outputsHandles.length];
for (int i = 0; i < outputsHandles.length; ++i) {
outputs[i] = Tensor.fromHandle(outputsHandles[i]);
}
return outputs;
}
インタープリタ(JNI経由でC++モデル)に、入力データを渡して実行
Java_org_tensorflow_lite_NativeInterpreterWrapper_run
tensorflow/contrib/lite/java/src/main/native/nativeinterpreterwrapper_jni.cc
JNI経由でC++モデルのrunメソッドを呼び出す](https://image.slidesharecdn.com/tensorflowliteandroid8-180308015811/85/TensorFlow-Lite-r1-5-Android-8-1-Neural-Network-API-20-320.jpg)

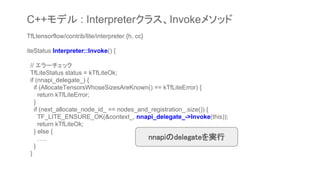
![status = setInputs(env, interpreter, input_size, data_types, nums_of_bytes, values);
interpreter->Invoke();
const std::vector<int>& results = interpreter->outputs();
jlongArray outputs = env->NewLongArray(results.size());
size_t size = results.size();
for (int i = 0; i < size; ++i) {
TfLiteTensor* source = interpreter->tensor(results[i]);
jlong output = reinterpret_cast<jlong>(source);
env->SetLongArrayRegion(outputs, i, 1, &output);
}
return outputs;
}
インタープリタ実行
C++モデル : runメソッド(続き)](https://image.slidesharecdn.com/tensorflowliteandroid8-180308015811/85/TensorFlow-Lite-r1-5-Android-8-1-Neural-Network-API-25-320.jpg)


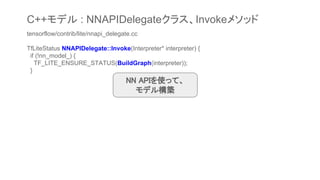




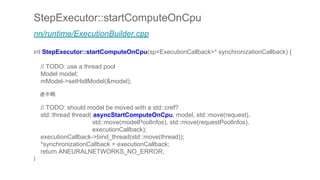
![void AddOpsAndParams(tflite::Interpreter* interpreter,
ANeuralNetworksModel* nn_model, uint32_t next_id) {
// 途中略
ANeuralNetworksExecution* execution = nullptr;
CHECK_NN(ANeuralNetworksExecution_create(nn_compiled_model_, &execution));
// Currently perform deep copy of input buffer
for (size_t i = 0; i < interpreter->inputs().size(); i++) {
int input = interpreter->inputs()[i];
// TODO(aselle): Is this what we want or do we want input instead?
// TODO(aselle): This should be called setInputValue maybe to be cons.
TfLiteTensor* tensor = interpreter->tensor(input);
CHECK_NN(ANeuralNetworksExecution_setInput(
execution, i, nullptr, tensor->data.raw, tensor->bytes));
}
C++モデル : AddOpsAndParams関数
入力データ](https://image.slidesharecdn.com/tensorflowliteandroid8-180308015811/85/TensorFlow-Lite-r1-5-Android-8-1-Neural-Network-API-34-320.jpg)
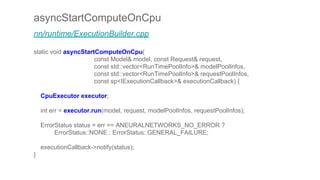
![for (size_t i = 0; i < interpreter->outputs().size(); i++) {
int output = interpreter->outputs()[i];
TfLiteTensor* tensor = interpreter->tensor(output);
CHECK_NN(ANeuralNetworksExecution_setOutput(
execution, i, nullptr, tensor->data.raw, tensor->bytes));
}
// Currently use blocking compute.
ANeuralNetworksEvent* event = nullptr;
CHECK_NN(ANeuralNetworksExecution_startCompute(execution, &event));
CHECK_NN(ANeuralNetworksEvent_wait(event));
ANeuralNetworksEvent_free(event);
ANeuralNetworksExecution_free(execution);
return kTfLiteOk;
}
出力データ
推論開始
終了待ち
データ開放
C++モデル : AddOpsAndParams関数 (続き)](https://image.slidesharecdn.com/tensorflowliteandroid8-180308015811/85/TensorFlow-Lite-r1-5-Android-8-1-Neural-Network-API-35-320.jpg)


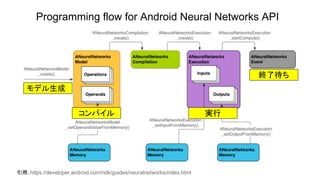









![Add
tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h
void Add (const float* input1_data, const Dims<4>& input1_dims,
const float* input2_data, const Dims<4>& input2_dims,
float* output_data, const Dims<4>& output_dims) {
gemmlowp::ScopedProfilingLabel label("Add");
/* const int batches = */ MatchingArraySize(input1_dims, 3, input2_dims, 3, output_dims, 3);
/* const int height = */ MatchingArraySize(input1_dims, 2, input2_dims, 2, output_dims, 2);
/* const int width = */ MatchingArraySize(input1_dims, 1, input2_dims, 1, output_dims, 1);
/* const int depth = */ MatchingArraySize(input1_dims, 0, input2_dims, 0, output_dims, 0);
TFLITE_DCHECK(IsPackedWithoutStrides(input1_dims));
TFLITE_DCHECK(IsPackedWithoutStrides(input2_dims));
TFLITE_DCHECK(IsPackedWithoutStrides(output_dims));
int i = 0;
const int size = input1_dims.sizes[3] * input1_dims.strides[3];
#ifdef USE_NEON
TensorFlow Lite
のコードを使う](https://image.slidesharecdn.com/tensorflowliteandroid8-180308015811/85/TensorFlow-Lite-r1-5-Android-8-1-Neural-Network-API-50-320.jpg)


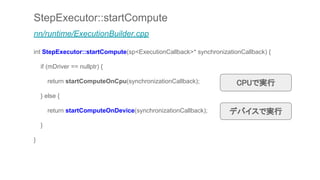

![int n = allocatePointerArgumentsToPool(&mInputs, &inputPointerArguments);
n = allocatePointerArgumentsToPool(&mOutputs, &outputPointerArguments);
for (auto& info : mInputs) {
if (info.state == ModelArgumentInfo::POINTER) {
DataLocation& loc = info.locationAndLength;
uint8_t* data = nullptr;
int n = inputPointerArguments.getPointer(&data);
memcpy(data + loc.offset, info.buffer, loc.length);
}
}
Request request;
setRequestArgumentArray(mInputs, &request.inputs);
setRequestArgumentArray(mOutputs, &request.outputs);
uint32_t count = mMemories.size();
request.pools.resize(count);
for (uint32_t i = 0; i < count; i++) {
request.pools[i] = mMemories[i]->getHidlMemory();
}
入力ポインタ
出力ポインタ
入力データ](https://image.slidesharecdn.com/tensorflowliteandroid8-180308015811/85/TensorFlow-Lite-r1-5-Android-8-1-Neural-Network-API-55-320.jpg)






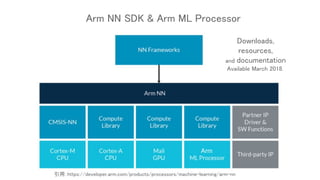




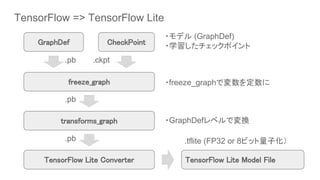
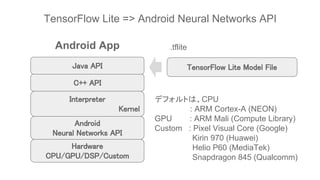

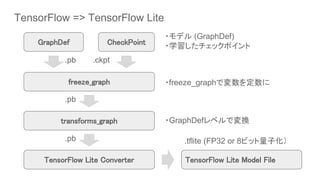
This document discusses TensorFlow Lite 1.5 and the Android 8.1 Neural Networks API. It provides an overview of converting TensorFlow models to the TensorFlow Lite format using conversion tools, and running those models on Android using the TensorFlow Lite and Neural Networks APIs. The key steps are converting TensorFlow models to TensorFlow Lite format, creating an interpreter to run the model, and using the interpreter and Neural Networks API to execute the model on Android hardware like the CPU.

































































