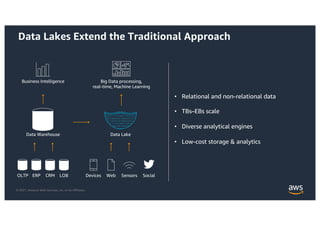
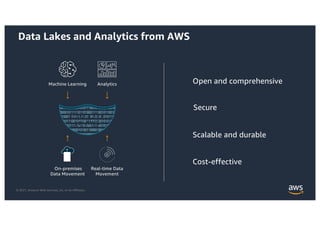
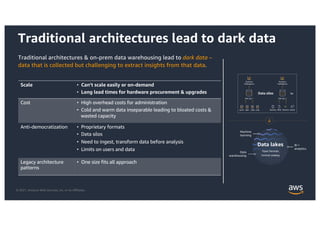
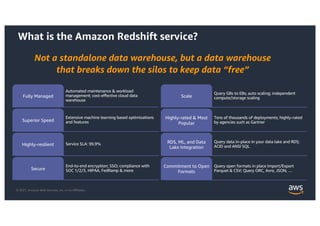
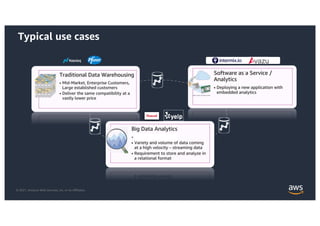
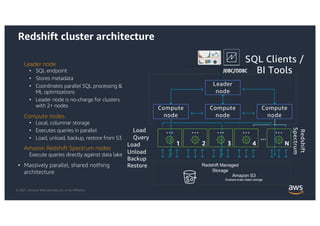
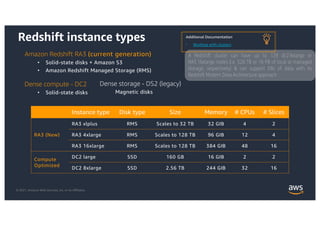
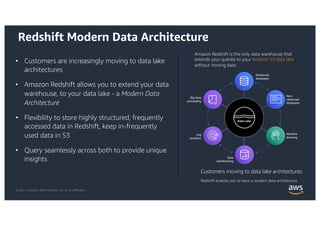
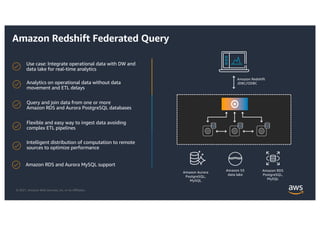
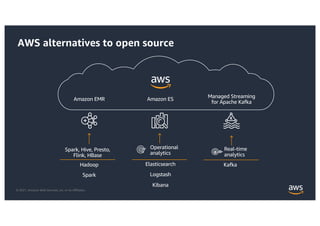
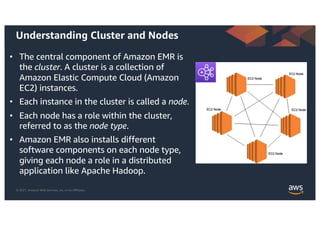
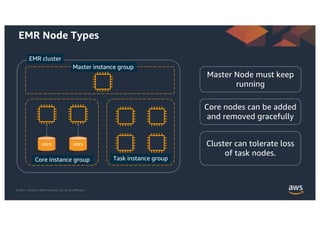
This document provides an agenda and overview for a workshop on building a data lake on AWS. The agenda includes reviewing data lakes, modernizing data warehouses with Amazon Redshift, data processing with Amazon EMR, and event-driven processing with AWS Lambda. It discusses how data lakes extend traditional data warehousing approaches and how services like Redshift, EMR, and Lambda can be used for analytics in a data lake on AWS.













![© 2021, Amazon Web Services, Inc. or its Affiliates.
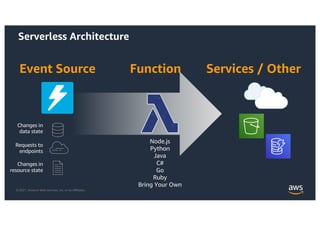
Anatomy of a Lambda Function
Handler function
• Function executed on invocation
• Processes incoming event
Event
• Invocation data sent to function
• Shape differs by event source
Context
• Additional information from Lambda service
• Examples: request ID, time remaining
def handler(event, context):
msg = ‘Hello {}’.format(
event[‘name’]
)
return { ‘message’: msg }
app.py](https://image.slidesharecdn.com/module2-datalake-211022050944/85/Module-2-Datalake-28-320.jpg)
























![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[よくわかるAmazon Redshift]Amazon Redshift最新情報と導入事例のご紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20140219redshiftupdatesv1tokyo-140224010117-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Provided Data - Brazil] Hung Nguyen](https://cdn.slidesharecdn.com/ss_thumbnails/brazilecom-datastorytelling-211019043402-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Provided Data - US] Hang Le](https://cdn.slidesharecdn.com/ss_thumbnails/use-commercehangle-211019043253-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Custom Data] Ngo Duy Vu](https://cdn.slidesharecdn.com/ss_thumbnails/ngoduyvupresentation-211019043049-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Provided Data - US] Khanh Ngo](https://cdn.slidesharecdn.com/ss_thumbnails/submition-211019042650-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Custom Data] Alice Nguyen](https://cdn.slidesharecdn.com/ss_thumbnails/alicenguyenawsdevax2021-211019042627-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Provided Data - US] Thien Tran](https://cdn.slidesharecdn.com/ss_thumbnails/thientran-211019041901-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Custom Data] Hy Dang](https://cdn.slidesharecdn.com/ss_thumbnails/datastory-tellingwithawsquicksightbyhydang-211019041800-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Provided Data - Brazil] Dương Hà Nguyễn Hoàng](https://cdn.slidesharecdn.com/ss_thumbnails/data-story-telling-ha-nguyen-hoang-duong-brasil-dataset-211019041642-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Custom Data] Ha Hoang](https://cdn.slidesharecdn.com/ss_thumbnails/hoanghaworkshopaws-211019041531-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Provided Data - US] Tran Chau](https://cdn.slidesharecdn.com/ss_thumbnails/use-commerce-devax2-211019041347-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Provided Data - Brazil] Ethan Phan](https://cdn.slidesharecdn.com/ss_thumbnails/datastorytellingawsquicksight-ethan-211019041246-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Provided Data - US] ChiQuyen Dinh](https://cdn.slidesharecdn.com/ss_thumbnails/datastorytellingwithawsquicksightquyendinhpdf-211019041142-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Provided Data - US] Chi Cuong Nguyen](https://cdn.slidesharecdn.com/ss_thumbnails/aws-datastorytellingwithquicksight-nguyenchicuong-211019041015-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Custom Data] Alice Nguyen](https://cdn.slidesharecdn.com/ss_thumbnails/alicenguyenawsdevax2021-211019040708-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Provided Data - Brazil] Vuong.le](https://cdn.slidesharecdn.com/ss_thumbnails/vuong-211019040512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Provided data - Brazil] Tran Manh Cuong](https://cdn.slidesharecdn.com/ss_thumbnails/cuong-211019040350-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Custom data] Ngo Duy Vu](https://cdn.slidesharecdn.com/ss_thumbnails/ngoduyvupresentation-211019040032-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Provided Data - US] Thao Phi](https://cdn.slidesharecdn.com/ss_thumbnails/datastorytellingphilamphuongthao-211019030856-thumbnail.jpg?width=640&height=640&fit=bounds)
![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)


















